本文主要是介绍Polyp-DDPM: Diffusion-Based Semantic Polyp Synthesis for Enhanced Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Polyp- ddpm:基于扩散的语义Polyp合成增强分割
摘要:
本研究介绍了一种基于扩散的方法Polyp-DDPM,该方法用于生成假面条件下息肉的逼真图像,旨在增强胃肠道息肉的分割。我们的方法解决了与医学图像相关的数据限制、高注释成本和隐私问题的挑战。通过对分割掩模(代表异常区域的二进制掩模)的扩散模型进行调节,poly - ddpm在图像质量(实现fr起始距离(FID)得分为78.47,而高于83.79)和分割性能(实现交集比(IoU)为0.7156,而基线模型合成图像低于0.6694,真实数据为0.7067)方面优于最先进的方法。我们的方法生成了一个高质量的、多样化的合成数据集用于训练,从而增强了息肉分割模型与真实图像的可比性,并提供了更大的数据增强能力来改进分割模型。
1 介绍
结直肠癌(Colorectal cancer, CRC)是全球第三常见、第二致命的癌症[1]。结直肠癌通常以结直肠息肉开始,这是该疾病的早期指标。
通过结肠镜检查及早发现并切除这些息肉可预防结直肠癌,降低死亡率。然而,在结肠镜检查中识别小息肉可能很困难,这取决于医生的专业知识和其他挑战,例如息肉在检查过程中看不到或被忽视[2]。
为了加强息肉的检测,研究人员正在利用机器学习来自主识别和强调内镜下的息肉[3]。然而,由于需要广泛和多样化的数据集,这些技术的发展面临着重大挑战,这些数据集对于训练模型实现高精度至关重要。由于异常区域出现的多样性、招募患者的困难、数据标注的高成本以及对患者数据隐私的担忧等原因,医疗行业经常面临此类数据的短缺[4]。
为了缓解数据稀缺问题,探索合成图像作为一种可行的解决方案已经引起了人们的关注[5]。
Thambawita等人[6]开发了一种基于gan的方法,用于使用分割蒙版创建息肉图像,使用两个阶段的过程,包括在1,000张图像的HyperKvasir数据集[7]上进行初始训练,然后进行风格转移以生成合成图像。尽管比其他GAN模型获得了更真实的图像,但他们的SinGAN-Seg模型在多样性和细节准确性方面面临挑战。GAN模型的一个普遍问题是模态崩溃问题。基于扩散的模型的最新进展已经克服了模式崩溃问题,产生了比gan更好的多样化、高质量的图像[8]。Macháček等人[9]使用Kvasir-SEG数据集[10],引入了一种用于息肉图像和掩模生成的两阶段扩散模型。这个过程包括使用改进的扩散模型生成掩模,然后在这些掩模上调节潜在扩散模型以创建图像。尽管该方法可以有效地生成各种图像,但由于需要两个模型,该方法在训练和推理方面的计算成本很高。
为了应对这些挑战,我们引入了一种新的基于扩散的语义息肉合成方法,polyypddpm,旨在增强我们之前的工作Med-DDPM[11]的息肉分割。这种方法通过掩膜图像的通道级联来调节扩散模型。我们使用Kvasir-SEG数据集进行了实验,并将我们提出的方法与SinGAN-Seg[6]和潜在扩散模型[9]进行了比较,因为这些方法代表了注释息肉数据集生成的最新进展,包括基于gan和基于扩散的方法。在我们的实验中,与基线模型相比,poly - ddpm在图像质量和分割任务方面表现出优越的性能。本研究为任意给定掩模图像合成高质量的合成息肉图像提供了一种新的基于扩散的方法,可用于训练更准确的息肉分割模型,从而为该领域的研究做出了贡献。源代码和预训练模型是公开的,以进一步研究和应用在这一重要领域的医学成像。
2 方法
在本研究中,我们在之前语义3D脑MRI合成工作的基础上[11],并增强了基于分割蒙版生成条件2D息肉图像的架构。
我们的方法涉及前向扩散过程𝑞,由方差调度ϵ∼𝒩(0,i)定义的少量高斯噪声α̅t在给定时间步T中的每个时间步𝑥被添加到训练数据集的图像样本𝑡0:

为了避免噪声水平的突然波动,对[12]中提出的余弦噪声时间表进行了调整,定义如下:

其中,参数𝑠表示一个较小的偏移值,以防止在时间步长接近零时计划过小。[11]
在反向扩散过程𝑝θ中,我们采用了具有输入通道的U-Net结构作为去噪模型。我们所提出的方法的核心结构如图1所示。去噪器U-Net结构的主要组件包括正弦位置嵌入,它被用来编码时间步长𝑡,从而通知模型关于影响输入图像的特定噪声水平。该架构的一个关键元素是宽ResNet块,它由卷积层、完全连接层、组归一化、SI鲁激活层和跳过连接组成。组归一化结合了关注层之后的2D卷积层。为了实现条件建模,我们引入了一种简单而高效的技术,该技术通过以通道方式串联分割掩码𝑥𝑡来修改输入图像𝑐。
3 实验和结果
我们使用Kvasir-SEG数据集[10],与LDM[9]使用相同的训练和测试拆分来训练我们提出的方法。图像大小调整为256x256像素,像素强度调整为范围[-1,1]。我们的模型使用900张图像进行训练,然后在100张测试图像上进行测试。为了确保公平的比较,我们使用了LDM[9]和SinGan-Seg[6]的预训练模型。然而,SinGan-Seg模型在HyperKvasir数据集的1000张图像上进行了训练,并包含了样式转移,与仅在900张图像上训练而没有样式转移的模型进行了不公平的比较。尽管如此,我们的目标是评估我们的扩散模型对它的有效性。我们的模型使用了100,000次迭代,学习率为10-4,批次大小为32,输入通道,仅使用250个时间步,并使用了L1损失函数。在训练过程中,我们应用了旋转、水平翻转和随机旋转等增强技术。对于息肉分割任务,作为对合成图像的定性评估,我们使用了相同的分割模型-UNET++、FPN和DeepLabv3plus-AS[9],除了将历元数更改为100以及修改训练和测试图像数外,具有相同的超参数配置。对来自Kvasir-SEG训练集的900幅图像和从训练集的掩模图像创建的900幅合成图像对所有分割模型进行训练。为了评估合成图像的有效性,我们对HyperKvasir数据集[7]中的1000张图像和ETIS-LaribPolypDB数据集[13]中的196张图像以及Kvasir-SEG数据集的100张测试图像测试了分割模型。通过比较1,000个合成图像和真实图像的样本,使用Fréchet初始距离(FID)、初始分数(IS)和核心初始距离(KID)分数对合成图像进行定量评估。我们对两个不同的数据集:KvasirSEG和HyperKvasir进行了定量评估。使用联合交集(IOU)、F1评分、准确度和精确度评分来评估分割模型的性能。所有型号都在特斯拉V100-SXM2 32 GB GPU卡上进行了培训。
A. 图像合成的结果
图2显示了使用来自HyperKvasir数据集的给定掩模,由我们提出的方法和两个基线模型生成的真实和合成图像之间的比较。该数据集被用于训练SinGan-Seg模型,并作为我们提出的方法和潜在扩散模型(LDM)的不可见数据。比较表明,这两种扩散模型比SinGan-Seg模型具有更高的多样性样本生成能力。尽管使用其训练数据的输入掩码的GaN-Seg模型在理论上应该比其他两个扩散模型生成更好的图像,但很明显,预先训练的SinGANSeg模型遭受了模式崩溃的影响,并且只产生略有变化的图像。相比之下,这两种扩散模型能够产生多样化、高质量的样本。将提出的POLIP-DDPM算法与LDM算法进行比较,我们的模型能够生成比LDM算法更丰富、细节更精确的图像。在定量评估方面,我们提出的POLIP-DDPM方法在Kvasir-SEG和HyperKvasir数据集上的表现优于其他基线模型(表I)。
与Kvasir-SEG数据集的图像相比,我们的方法获得了最低的Fréchet初始距离(FID)得分78.47和核初始距离(KID)0.07,而在HyperKvasir数据集中的真实图像上FID和KID分别为81.10和0.07。相比之下,LDM的得分第二高,FID为95.82Kvasir-SEG上的KID为0.09,HyperKvasir上的FID为97.01,KID为0.09。
相反,与它自己的训练数据集HyperKvasir相比,SinGan-Seg的FID和KID得分分别为131.13和0.14,而且在Kvasir-SEG数据集上的表现也很差。然而,与两个基于扩散的模型相比,SinGan-Seg模型获得了最高的初始得分,这归因于SinGan-Seg模型从真实图像中转移风格的能力。
B.分割实验结果
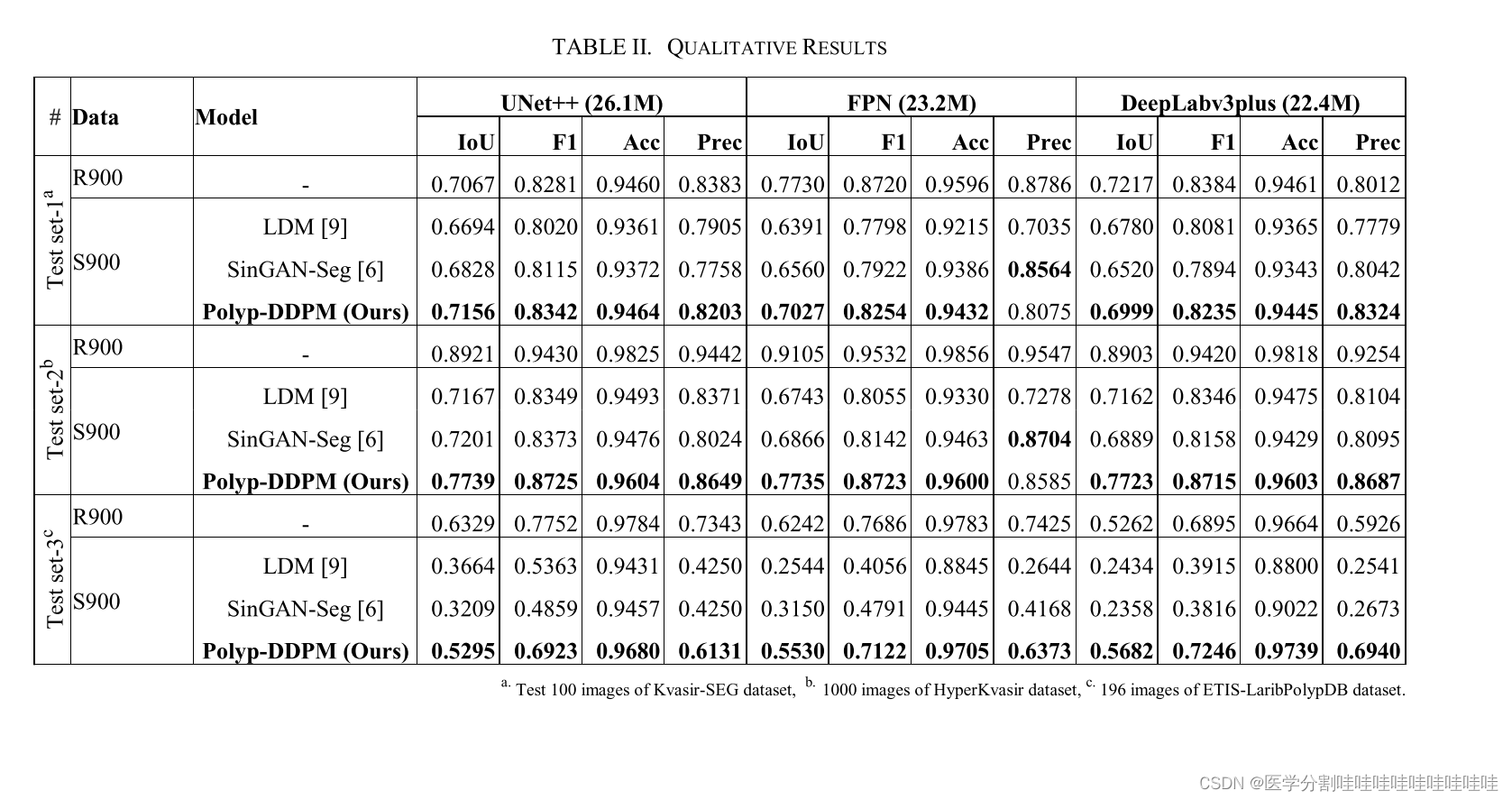
我们在三个不同的测试数据集:KvasirSEG、HyperKvasir和ETIS-LaribPolypDB上,对三种分割模型-UNET++、FPN和DeepLabv3plus的性能进行了全面的分析,比较了使用合成图像和真实图像进行训练的效果,如表II所示。当对900幅合成图像进行训练时,PolypDDPM模型在Kvasir-SEG数据集的测试集上显示了显著的结果。具体地说,该模型的欠条为0.7156,F1得分为0.8342,准确度为0.9464,精确度为0.8203,超过了SINGAN-SEG和LDM模型。与用900张真实图像训练时相比,这一改进更加明显,当时IOU为0.7067,F1得分为0.8281,突显了合成数据在提高分割性能方面的有效性。在FPN和DeepLabv3plus模型中也观察到了类似的趋势,其中Polyp-DDPM的表现优于其他两个基线模型。然而,FPN和DeepLabv3plus模型的IOU和F1得分低于真实图像结果。在不可见的HyperKvasir数据集上,PolypDDPM的优势更加明显。使用unet++模型,它获得了0.7739的借条和0.8725的F1得分,超过了在整个HyperKvasir数据集上训练的SinGan-Seg模型的性能,也超过了LDM。这一趋势在FPN和DeepLabv3plus模型中继续下去,甚至在未见过的ETIS-LaribPolypDB数据集中继续下去,强调了Polyp-DDPM更好地泛化的能力。在Kvasir-SEG和HyperKvasir数据集上的SinGAN-Seg图像上,FPN模型的唯一精度分数高于其他模型。然而,在ETIS-LaribPolypDB数据集上没有观察到这种模式。然而,当应用于这些看不见的数据集时,合成图像的性能与真实图像的性能不匹配,导致得分较低。这突出表明需要进一步改进合成图像的质量。此外,我们研究了使用真实图像和合成图像的组合来训练分割模型,并发现我们所提出的方法在数据增强能力方面有相当大的前景。例如,包含1800张图像(900REAL和900Polyp-DDPM)的混合训练集获得了0.7484的借条和0.8561的F1分数。相比之下,只使用了900张真实图像,借条和F1得分较低:unet++分别为0.7067和0.8281。同样,对于DeepLabv3plus,混合设置产生的借条为0.7496,F1为0.8569,超过了真实图像的借条0.7217和F1 0.8384。
4 结论
这项研究介绍了PolyP-DDPM,一种新的基于扩散的语义息肉合成方法,它在生成高质量、多样化的合成息肉图像方面优于现有的基于GaN和基于扩散的模型。使用Fréchet初始距离和核初始距离度量的定量评估进一步证实了POLIP-DDPM相对于SinGAN-Seg和潜在扩散模型的优势,特别是在生成与真实数据集特征非常相似的图像方面。此外,分割实验强调了我们提出的方法生成的合成图像有潜力改进息肉分割模型的训练,使其与真实图像具有可比性,并在各种测试数据集上取得了显著的结果。PolypDDPM的相对优势尤其明显,它能够以更高的多样性和精确度生成图像,从而解决了医学成像领域数据稀缺的关键挑战。这项研究不仅推进了合成图像生成的技术前沿,而且为更有效和更容易获得的医学成像解决方案铺平了道路,最终有助于改进对模型的培训,以早期发现和预防结直肠癌。


图1.用于训练和生成合成息肉图像的Polyp-DDPM的总体架构。A)训练:通过调节异常区域的二值分割掩模,训练Polyp-DDPM将随机噪声转换为逼真的息肉图像。B)PolypDDPM模型的核心构建块。C)推理:训练好的Polyp-DDPM模型对给定的输入掩模进行推理,生成相应的合成图像。

图2.真实样本和合成样本的比较:展示了从单一输入掩模生成的合成图像的多样性
这篇关于Polyp-DDPM: Diffusion-Based Semantic Polyp Synthesis for Enhanced Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








