segmentation专题

Segmentation简记-Multi-stream CNN based Video Semantic Segmentation for Automated Driving
创新点 1.RFCN & MSFCN 总结 网络结构如图所示。输入视频得到图像分割结果。 简单粗暴

Segmentation简记5-AuxNet: Auxiliary tasks enhanced Semantic Segmentation for Automated Driving
创新点 1.分割网络为主任务,深度估计网络为辅任务 2.loss的设计 总结如图所示 网络结构如图所示 其实很容易理解。 backbone是基于ResNet50 分割网络是基于FCN8 深度估计网络与分割网络类似,最后一层是回归深度层。 最有意思的是两种任务的loss的合并。 分割的loss很常见:cross entropy 深度loss:mean absolute error 算法一:

DS简记1-Real-time Joint Object Detection and Semantic Segmentation Network for Automated Driving
创新点 1.更小的网络,更多的类别,更复杂的实验 2. 一体化 总结 终于看到一篇检测跟踪一体化的文章 网络结构如下: ResNet10是共享的Encoder,yolov2 是检测的Deconder,FCN8 是分割的Deconder。 其实很简单,论文作者也指出:Our work is closest to the recent MultiNet. We differ by focus

Segmentation简记3-UPSNet: A Unified Panoptic Segmentation Network
Segmentation简记3-UPSNet: A Unified Panoptic Segmentation Network 创新点总结实验 创新点 1.统一的全景分割网络 总结 uber的作品 网络结构如下: 还是比较简洁的。 Backbone 采用了原始mask rcnn。 Instance Segmentation Head 使用了最大的特征图,包括bbox回归,分

Segmentation简记2-RESIDUAL PYRAMID FCN FOR ROBUST FOLLICLE SEGMENTATION
创新点 与resnet结合,五层/level的分割由此带来的梯度更新问题,设计了两种方案。 总结 有点意思。看图吧,很明了。 细节图: 全流程图: 实验 Res-Seg-Net-horz: 在UNet上堆叠5个细节图中的结构,没有上采样层。 Res-Seg-Net-non-fixed: 普通方式的更新 Res-Seg-Net-fixed: 每一层的更新,只依据距离它最近的一

3D Deeply Supervised Network for Automatic Liver Segmentation from CT Volumes
下面博主详细翻译了该篇论文,可以当做详尽的参考,并认真学习。 【参考】论文笔记:3D Deeply Supervised Network for Automatic Liver Segmentation from CT 数据集: MICCAI-SLiver07[1] 数据预处理: 作者没有讲数据预处理的过程。 CRF 轮廓精细修正: 参考上述博主博客。 参考文献: [1]Heimann,

Liver Segmentation in CT based on ResUNet with 3D Probabilistic and Geometric Post Process
一、摘要 本文提出了使用具有3D概率和几何后期处理功能的ResUNet的新型肝分割框架。 我们的语义分割模型ResUNet在U-Net的上采样和下采样部分添加了残差单元和批处理规范化层,以构建更深的网络。 为了快速收敛,我们提出了一种新的损失函数DCE,该函数由Dice损失和交叉熵损失线性组合。 我们使用连续的几个CT图像作为训练和测试的输入,以探索更多的上下文信息。 基于ResUNet的初始分割

Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges
前言: 该篇文章较为全面但稍偏简单的介绍医学图像分割的常见数据集、各种神经网络,以及常见的训练技巧等问题。 一、重点摘录 2.5D approaches are inspired by the fact that 2.5D has the richer spatial information of neighboing pixels wiht less computational costs t
![[RIS]GRES: Generalized Referring Expression Segmentation](https://i-blog.csdnimg.cn/direct/c7b8902dcfe94446af722adfcf47e393.png)
[RIS]GRES: Generalized Referring Expression Segmentation
1. BaseInfo TitleGRES: Generalized Referring Expression SegmentationAdresshttps://arxiv.org/pdf/2306.00968Journal/TimeCVPR2023Author南洋理工Codehttps://github.com/henghuiding/ReLARead20240829TableVisonLa

Clustering-Guided Class Activation for WeaklySupervised Semantic Segmentation
pdf:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10381698 code:https://github.com/DCVL-WSSS/ClusterCAM 摘要: 基于transformer的弱监督语义分割(WSSS)方法利用其捕获全局上下文的强大能力得到了积极的研究。然而,由于激活函数在transformer的自注意

U-Net for Image Segmentation
1.Unet for Image Segmentation 笔记来源:使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割) 1.1 DoubleConv (Conv2d+BatchNorm2d+ReLU) import torchimport torch.nn as nnimport torch.nn.functional as F# nn.Sequential
Splash of Color: Instance Segmentation with Mask R-CNN and TensorFlow
喷色:使用Mask R-CNN和TensorFlow进行实例分割 原文:Splash of Color: Instance Segmentation with Mask R-CNN and TensorFlow 原作者:Waleed Abdulla 0 概述 早在11月,我们就将Mask R-CNN的实现开源了,此后,它被forked了1400次,在许多项目中使用,并得到了许多贡献者的改进。
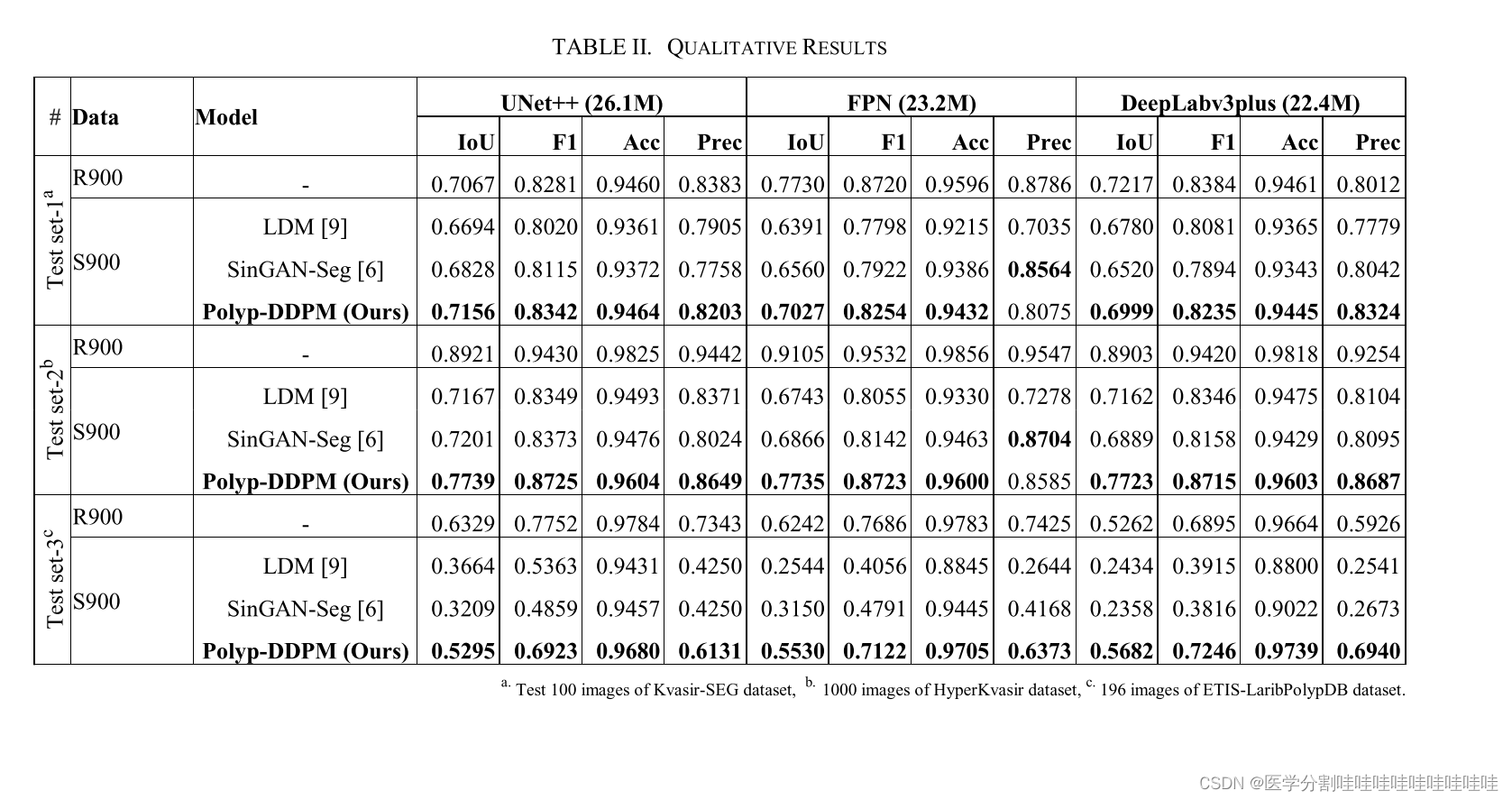
Polyp-DDPM: Diffusion-Based Semantic Polyp Synthesis for Enhanced Segmentation
Polyp- ddpm:基于扩散的语义Polyp合成增强分割 摘要: 本研究介绍了一种基于扩散的方法Polyp-DDPM,该方法用于生成假面条件下息肉的逼真图像,旨在增强胃肠道息肉的分割。我们的方法解决了与医学图像相关的数据限制、高注释成本和隐私问题的挑战。通过对分割掩模(代表异常区域的二进制掩模)的扩散模型进行调节,poly - ddpm在图像质量(实现fr起始距离(FID)得分为78.47

【C语言】解决C语言报错:Segmentation Fault
文章目录 简介什么是Segmentation FaultSegmentation Fault的常见原因如何检测和调试Segmentation Fault解决Segmentation Fault的最佳实践详细实例解析示例1:未初始化指针示例2:数组越界示例3:使用已释放的内存示例4:递归导致栈溢出 进一步阅读和参考资料总结 简介 Segmentation Fault(段

论文阅读--Cross-view Transformers for real-time Map-view Semantic Segmentation
一种新的2D维度的bev特征提取方案,其通过引入相机先验信息(相机内参和外参)构建了一个多视图交叉注意力机制,能够将多视图特征映射为BEV特征。 cross view attention:BEV位置编码+由根据相机标定结果(内参和外参)演算得到的相机位置编码+多视图特征做attention得到 整体上文章的网络前端使用CNN作为特征抽取网络,中端使用CNN多级特征作为输入在多视图下优化BEV特

实时语义分割--ICNet for Real-Time Semantic Segmentation on High-Resolution Images
github代码:https://github.com/hszhao/ICNet 语义分割算法精度和速度对比: 由图可以看出,ResNet38,PSPNet,DUC精度虽然较高,但是无法速度相对较慢,无法达到实时,ENet速度较快,但精度较低,而本文算法既可以达到实时,精度也相对较高. Speed Analysis PSPNet50的处理不同大小的输入图像所需时间: 图中,sta

【图像分割】DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation
DSNet: A Novel Way to Use Atrous Convolutions in Semantic Segmentation 论文链接:http://arxiv.org/abs/2406.03702 代码链接:https://github.com/takaniwa/DSNet 一、摘要 重新审视了现代卷积神经网络(CNNs)中的atrous卷积的设计,并证明了使用大内核

《汇编语言程序设计》例子出现segmentation fault
照着例子抄写了一下,直接用的 gcc 编译,源码如下,因为不支持 pushl,所以改成了 pushq #cpuid.s View the CPUID Vendor ID string using C library calls.section .dataoutput:.asciz "The processor Vendor ID is %s \n".section .bss.
Segmentation fault的原因和例子
最近有用cpp写点东西,然后就碰到Segmentation fault了,调试的时候,ide指出报错的地方看着没问题。后来研究发现,是递归层数太多导致的。 “Segmentation fault”(简称"segfault")是一个常见的计算机程序错误,通常发生在试图访问计算机内存中未分配(或不允许)的部分时。这种错误在多种操作系统和编程语言中都可能发生,尤其是在使用C或C++等低级语言时更为常见

《PixelLink: Detecting Scene Text via Instance Segmentation》论文阅读笔记
前言 这篇论文发表在AAAI2018上,作者给出了源码,个人认为是一篇比较work的论文。在之前DPR和SegLink两篇论文的阅读过程中,我就曾思考二者multi-task的必要性。特别是DPR的classification task,其实跟segment是几乎等价的。在复现过程中,回归任务远比分类(分割)任务难收敛。 可以认为,在自然场景下的文本检测任务中,DPR证明了anchor的非必要性

深度学习小目标检测问题——(转载)谈一谈深度学习之semantic Segmentation
https://www.cnblogs.com/daihengchen/p/6345041.html 上一次发博客已经是9月份的事了…这段时间公司的事实在是多,有写博客的时间都拿去看paper了…正好春节回来写点东西,也正好对这段时间做一个总结。 首先当然还是好好说点这段时间的主要工作:语义分割。semantic segmentation 应该是DL这几年快速发展的最重要的领域之一了,但可惜的

【语义分割】——又快又强:Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road
出处:哈尔滨工业大学 论文 code:暂未开源 关键词: 实时语义分割 语义分割是自动驾驶汽车了解周围场景的关键技术,对于实际的自动驾驶汽车来说,为了获得高精度的分割结果而花费大量的推理时间是不可取的。使用轻量级架构(编码器解码器或two-pathway)或推理在低分辨率图像。本文提出的模型在单张2080ti上DDRNet-slim能打到77.4% mIoU和230FPS,DDRNet
【论文阅读】Semantic Segmentation with deep convolutional nets and fully connected CRFs
一、摘要 深度卷积神经网络(DCNN)最近在高级视觉任务中展示了最先进的性能,例如图像分类和对象检测。这项工作汇集了来自DCNN和概率图形模型的方法,用于解决像素级分类(也称为“语义图像分割”)的任务。我们表明DCNN最后一层的响应没有充分定位,无法进行精确的对象分割。这是由于非常不变的属性使DCNN有利于高级任务。 我们通过将最终DCNN层的响应与完全连接的条件随机场(CRF
【论文阅读】semantic image segmentation with deep convolutional nets and fully connected CRFs
文章的主要贡献: 速度:带atrous算法的DCNN可以保持8FPS的速度,全连接CRF平均推断需要0.5s;准确:在PASCAL语义分割挑战中获得了第二的成绩;简单:DeepLab是由两个非常成熟的模块(DCNN和CRFs)级联而成。 一、概述 自LeCun(1998)以来,DCNN一直被选作版面识别的方法,如今已经成为高级视觉研究的主流,提高了计算机视觉性能,广泛应用于图像分割,对

【论文总结】weakly- and semi-supervised learning of a DCNN for semantic Image Segmentation
一、概述 这篇文章研究了如何从弱注释的训练数据(如边界框或图像级标签)或少量强标记图像和许多弱标记图像的组合中学习DCNN用于语义图像分割的问题,在弱超监督和半监督条件下提出了期望最大化(EM)方法。 代码:https://bitbucket.org/deeplab/deeplab-public(caffe框架) 二、研究内容及方法 文章将焦点放在用弱标签训练调参上

论文阅读U-KAN Makes Strong Backbone for MedicalImage Segmentation and Generation
作为一种非常有潜力的代替MLP的模型,KAN最终获得了学术界极大的关注。在我昨天的博客里,解读了最近的热门模型KAN: 论文阅读KAN: Kolmogorov–Arnold Networks-CSDN博客 KAN的原文作者提到了很多不足。本文算是对其中两个现有不足的回应,也就是:1)KAN不仅只能用于特定结构和深度,2)KAN不仅能用于小规模AI+Science任务,还可以用于更大规模或更复杂