本文主要是介绍U-Net for Image Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.Unet for Image Segmentation
笔记来源:使用Pytorch搭建U-Net网络并基于DRIVE数据集训练(语义分割)
1.1 DoubleConv (Conv2d+BatchNorm2d+ReLU)

import torch
import torch.nn as nn
import torch.nn.functional as F# nn.Sequential 按照类定义的顺序去执行模型,并且不需要写forward函数
class DoubleConv(nn.Sequential): # class 子类(父类)
# __init__() 是一个类的构造函数,用于初始化对象的属性。它会在创建对象时自动调用,而且通常在这里完成对象所需的所有初始化操作
# forward方法是实现模型的功能,实现各个层之间的连接关系的核心# def __init__(self) 只有一个self,指的是实例的本身。它允许定义一个空的类对象,需要实例化之后,再进行赋值# def __init__(self,args) 属性值不允许为空,实例化时,直接传入参数def __init__(self,in_channels,out_channels,mid_channels=None) # DoubleConv输入的通道数,输出的通道数,DoubleConv中第一次conv后输出的通道数if mid_channels is None: # mid_channels为none时执行语句mid_channels = out_channelssuper(DoubleConv,self).__init__( #继承父类并且调用父类的初始化方法nn.Conv2d(in_channels,mid_channels,kernel_size=3,padding=1,bias=False),nn.BatchNorm2d(mid_channels), # 进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定nn.ReLU(inplace=True), # 指原地进行操作,操作完成后覆盖原来的变量nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1,bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True))
1.1.1 Conv2d
直观了解kernel size、stride、padding、bias
原始图像通过与卷积核的数学运算,可以提取出图像的某些指定特征,卷积核相当于“滤镜”可以着重提取它感兴趣的特征
 下图来自:Expression recognition based on residual rectification convolution neural network
下图来自:Expression recognition based on residual rectification convolution neural network


1.1.2 BatchNorm2d
To understand what happens without normalization, let’s look at an example with just two features that are on drastically different scales. Since the network output is a linear combination of each feature vector, this means that the network learns weights for each feature that are also on different scales. Otherwise, the large feature will simply drown out the small feature.
Then during gradient descent, in order to “move the needle” for the Loss, the network would have to make a large update to one weight compared to the other weight. This can cause the gradient descent trajectory to oscillate back and forth along one dimension, thus taking more steps to reach the minimum.—Batch Norm Explained Visually — How it works, and why neural networks need it

if the features are on the same scale, the loss landscape is more uniform like a bowl. Gradient descent can then proceed smoothly down to the minimum. —Batch Norm Explained Visually — How it works, and why neural networks need it

Batch Norm is just another network layer that gets inserted between a hidden layer and the next hidden layer. Its job is to take the outputs from the first hidden layer and normalize them before passing them on as the input of the next hidden layer.
without batch norm
 include batch norm
include batch norm





下图来自:BatchNorm2d原理、作用及其pytorch中BatchNorm2d函数的参数讲解

1.1.3 ReLU
How an Activation function works?
We know, the neural network has neurons that work in correspondence with weight, bias, and their respective activation function. In a neural network, we would update the weights and biases of the neurons on the basis of the error at the output. This process is known as Back-propagation. Activation functions make the back-propagation possible since the gradients are supplied along with the error to update the weights and biases. —Role of Activation functions in Neural Networks


Why do we need Non-linear Activation function?
Activation functions introduce non-linearity into the model, allowing it to learn and perform complex tasks. Without them, no matter how many layers we stack in the network, it would still behave as a single-layer perceptron because the composition of linear functions is a linear function. —Convolutional Neural Network — Lesson 9: Activation Functions in CNNs
Doesn’t matter how many hidden layers we attach in neural net, all layers will behave same way because the composition of two linear function is a linear function itself. Neuron cannot learn with just a linear function attached to it. A non-linear activation function will let it learn as per the difference w.r.t error. Hence, we need an activation function.—Role of Activation functions in Neural Networks
 下图来自:Activation Functions 101: Sigmoid, Tanh, ReLU, Softmax and more
下图来自:Activation Functions 101: Sigmoid, Tanh, ReLU, Softmax and more

1.2 Down (MaxPool+DoubleConv)

class Down(nn.Sequential):def __init__(self,in_channels,out_channels):super(Down,self).__init__(nn.MaxPool2d(2,stride=2), # kernel_size核大小,stride核的移动步长DoubleConv(in_channels,out_channels))
1.2.1 MaxPool
Two reasons for applying Max Pooling :
- Downscaling Image by extracting most important feature
- Removing Invariances like shift, rotational and scale
下图来自:Max Pooling, Why use it and its advantages.

Max Pooling is advantageous because it adds translation invariance. There are following types of it
- Shift Invariance(Invariance in Position)
- Rotational Invariance(Invariance in Rotation)
- Scale Invariance(Invariance in Scale(small or big))


1.3 Up (Upsample/ConvTranspose+DoubleConv)
双线性插值进行上采样

转置卷积进行上采样
class Up(nn.Module):
# __init__() 是一个类的构造函数,用于初始化对象的属性。它会在创建对象时自动调用,而且通常在这里完成对象所需的所有初始化操作def __init__(self,in_channels,out_channels,bilinear=True): #默认通过双线性插值进行上采样super(Up,self).__init__()if bilinear: #通过双线性插值进行上采样self.up = nn.Upsample(scale_factor=2,mode='bilinear',align_corners=True) #输出为输入的多少倍数、上采样算法、输入的角像素将与输出张量对齐self.conv = DoubleConv(in_channels,out_channels,in_channels//2)else #通过转置卷积进行上采样self.up = nn.ConvTranspose2d(in_channels,in_channels//2,kernel_size=2,stride=2)self.conv = DoubleConv(in_channels,out_channels) # mid_channels = none时 mid_channels = mid_channels
# forward方法是实现模型的功能,实现各个层之间的连接关系的核心def forward(self,x1,x2) # 对x1进行上采样,将上采样后的x1与x2进行cat# 对x1进行上采样x1 = self.up(x1)# 对上采样后的x1进行padding,使得上采样后的x1与x2的高宽一致# [N,C,H,W] Number of data samples、Image channels、Image height、Image widthdiff_y = x2.size()[2] - x1.size()[2] # x2的高度与上采样后的x1的高度之差diff_x = x2.size()[3] - x2.size()[3] # x2的宽度与上采样后的x1的宽度之差# padding_left、padding_right、padding_top、padding_bottomx1 = F.pad(x1,[diff_x//2, diff_x-diff_x//2, diff_y//2, diff_y-diff_y//2])# 上采样后的x1与x2进行catx = torch.cat([x2,x1],dim=1)# x1和x2进行cat之后进行doubleconvx = self.conv(x)return x
1.3.1 Upsample
上采样率scale_factor

双线性插值bilinear


角像素对齐align_corners
下图来自:[PyTorch]Upsample

1.4 OutConv

class OutConv(nn.Sequential):def __init__(self, in_channels, num_classes):super(OutConv,self).__init__(nn.Conv2d(in_channels,num_classes,kernel_size=1) #输出分类类别的数量num_classes)
1.5 Unet
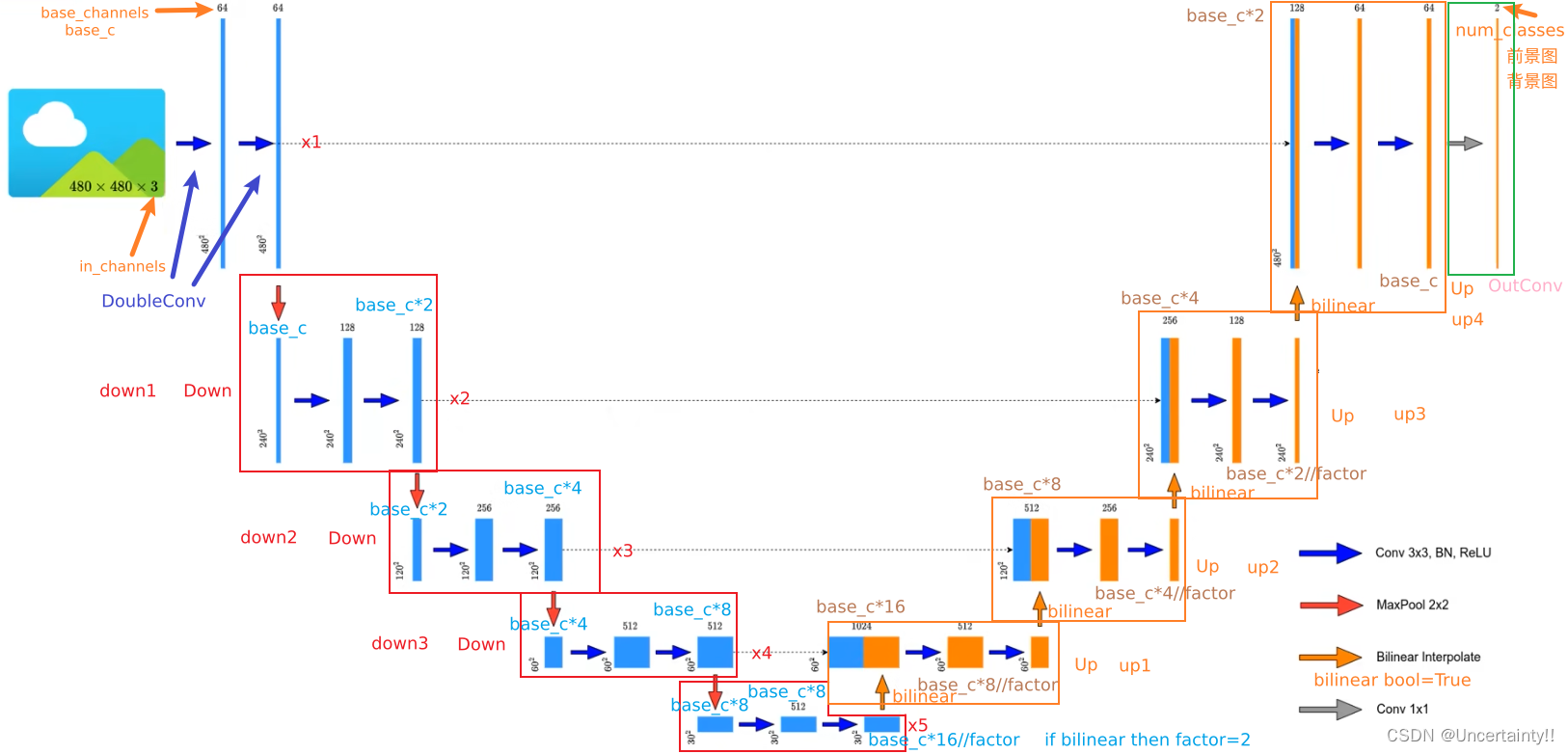
class UNet(nn.Module):def __init__(self,in_channels: int = 1, # 网络输入图片的通道数num_classes: int = 2, # 网络输出分类类别数bilinear: bool = True, # 上采样时使用双线性插值base_c: int = 64): # 基础通道数,网络中其他层的通道数均为该基础通道数的倍数super(UNet,self).__init__()self.in_channels = in_channelsself.num_classes = num_classesself.bilinear = bilinearself.in_conv = DoubleConv(in_channels,base_c) # in_channels、out_channels、mid_channels=noneself.down1 = Down(base_c,base_c*2) # in_channels、out_channels self.down2 = Down(base_c*2,base_c*4)self.down3 = Down(base_c*4,base_c*8)factor = 2 if bilinear else 1 #如果上采样使用双线性插值则factor=2,若使用转置卷积则factor=1self.down4 = Down(base_c*8,base_c*16//factor)self.up1 = Up(base_c*16, base_c*8//factor, bilinear) # in_channels、out_channels、bilinear=Trueself.up2 = Up(base_c*8, base_c*4//factor, bilinear)self.up3 = Up(base_c*4, base_c*2//factor, bilinear)self.up4 = Up(base_c*2, base_c, bilinear)self.out_conv = OutConv(base_c, num_classes) # in_channels, num_classesdef forward(self,x):x1 = self.in_conv(x)x2 = self.down1(x1)x3 = self.down2(x2)x4 = self.down3(x3)x5 = self.down4(x4)x = self.up1(x5,x4) # 对x5进行上采样,将上采样后的x5与x4进行catx = self.up2(x,x3)x = self.up3(x,x2)x = self.up4(x,x1)logits = self.out_conv(x)return {"out": logits} # 以字典形式返回
为何没有调用forward方法却能直接使用?
nn.Module类是所有神经网络模块的基类,需要重载__init__和forward函数
self.up1 = Up(base_c*16, base_c*8//factor, bilinear) //实例化Up
....
x = self.up1(x5,x4) //调用 Up() 中的 forward(self,x1,x2) 函数
up1调用父类nn.Module中的__call__方法,__call__方法又调用UP()中的forward方法

这篇关于U-Net for Image Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








