本文主要是介绍深度学习(生成式模型)——ADM:Diffusion Models Beat GANs on Image Synthesis,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 基础模型结构
- UNet结构
- Timestep Embedding
- 关于为什么需要timestep embedding
- global attention layer
- 如何提升diffusion model生成图像的质量
- Classifier guidance
- 实验结果
前言
在前几篇博文中,我们已经介绍了DDPM、DDIM、Classifier guidance等相关的扩散模型基础,从本节博客开始,将介绍一些经典偏应用类的文章。
《Diffusion Models Beat GANs on Image Synthesis》是openAI在2020年发表的一篇文章。文章从模型结构入手,通过扩大模型容量,在图像生成任务上击败了当时的SOTA Big GAN。
此外还提出了Classifier guidance,用于控制扩散模型生成指定类型的图像,具体推导流程可以查阅前文。
本节博客将重点总结模型结构,相应的代码可在此处查阅。
基础模型结构
Unet结构+timestep embedding+global attention layer是扩散模型常用的backbone。本节将对上述三个结构做个简单介绍。
UNet结构
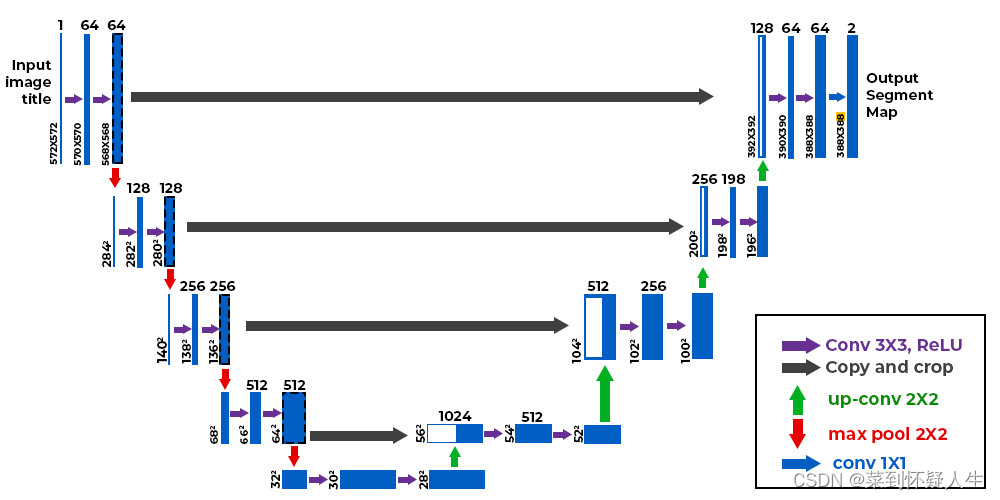
UNet结构由encoder和decoder两个神经网络组成。如下图所示,encoder对图像进行downsample,deocder对图像进行upsample,encoder和decoder之间存在skip connection。encoder和decoder均由residual layers堆叠而成。
Timestep Embedding
在扩散模型中,通常需要进行 T T T次迭代。类似于位置编码,扩散模型的每次迭代都有一个timestep embedding,用于告知模型目前是第几次迭代,其形式通常为一个常数vector,不同迭代次数的timestep embedding通常不桶。添加timestep embedding的方式有很多,可以通过concat的方式嵌入到每一个residual layers中,也可以通过add的方式嵌入到每一个residual layers的输出中。
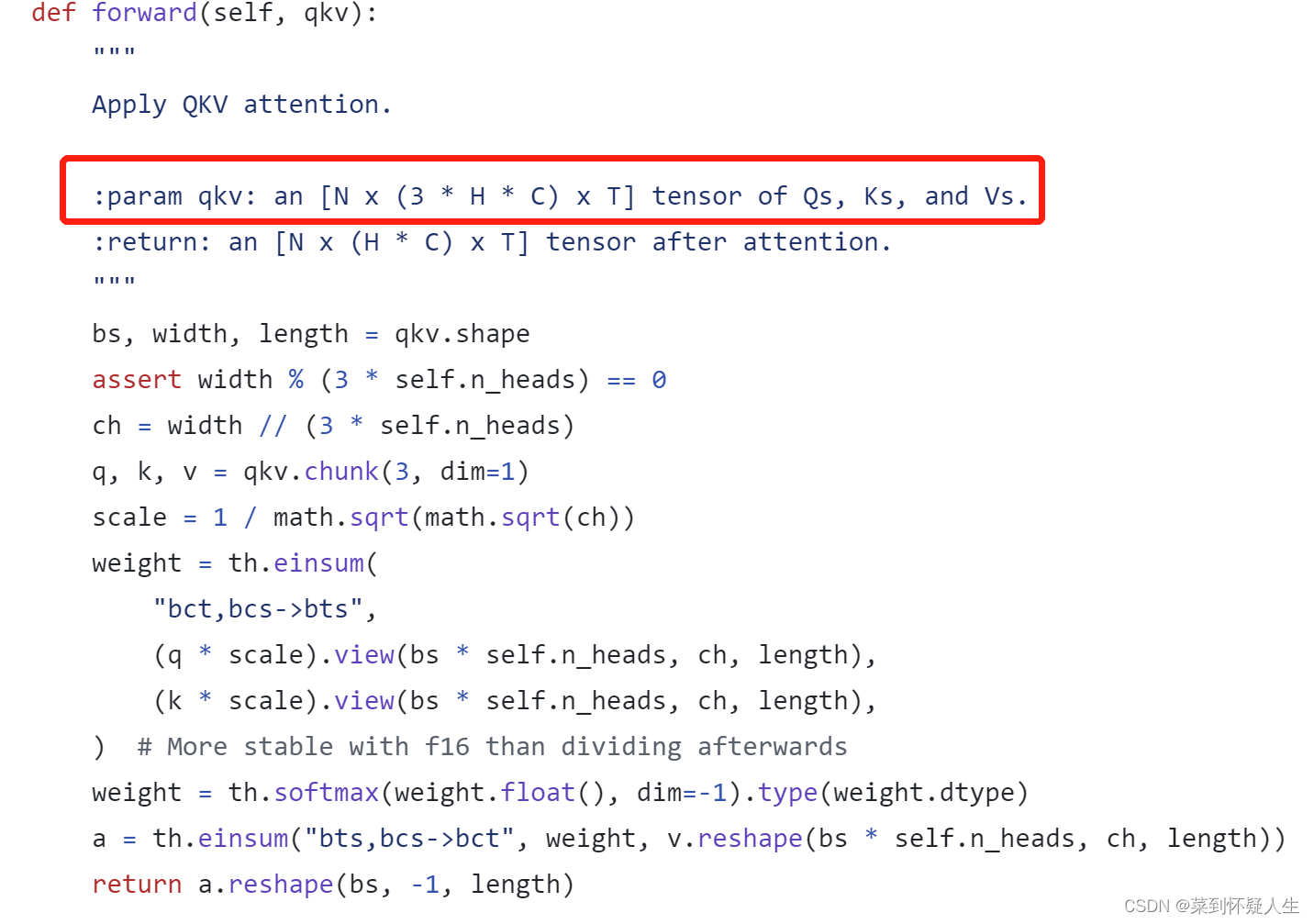
如下代码所示,在ADM中,timestep embedding在经过一层learning层处理后,通过add的方式嵌入到每个residual layers中。

关于为什么需要timestep embedding
扩散模型每轮迭代的输入图像所属的输入分布类型是不一致的,针对不同的输入分布,扩散模型的输出分布也会不同。但是模型要意识到当前图像处于哪种输入分布是件很难的事情,当两个输入分布近似时,模型的输出可能也会近似,这将很大程度影响生成图像的质量。例如生成一双手,在迭代初期,模型的输出应该是手指的轮廓等粗粒度信息,而迭代后期,模型的输出应该是手指指甲的光泽度的细粒度信息,如果迭代前后期的输入分布近似,那么在迭代的后期模型将无法输出指甲光泽度等细粒度的信息,生成的图像将不够逼真。
而timestep embedding的引入相当于把不同步骤的输入分布做了个区分。模型在学习的过程中,这种强烈的信号是不会被忽视的,输出分布的形式大概率会与timestep embedding强烈关联。当timestep取值较小时,模型输出的将是一些粗粒度信息,而随着timestep的取值逐渐变大,模型的输出也会逐渐变细。
global attention layer
global attention layer在ADM中其实就是self attention。假设第N层有 T T T个大小为 H ∗ C H*C H∗Cfeature map,将一个feature map看成一个token,则对应的矩阵大小为 ( H ∗ C ) ∗ T (H*C)*T (H∗C)∗T,在该矩阵上使用self attention,具体的代码如下:
如何提升diffusion model生成图像的质量
在上一节中,我们已经总结了ADM的基础模型结构,在本节中,我们将总结论文中提到能有效提升diffusion model生成图像质量的方法。
论文在五个方面进行了消融实验

在128*128分辨率的imagenet图像上训练,batch size设置为256,采样时的迭代轮数为250,对应的结果如下:
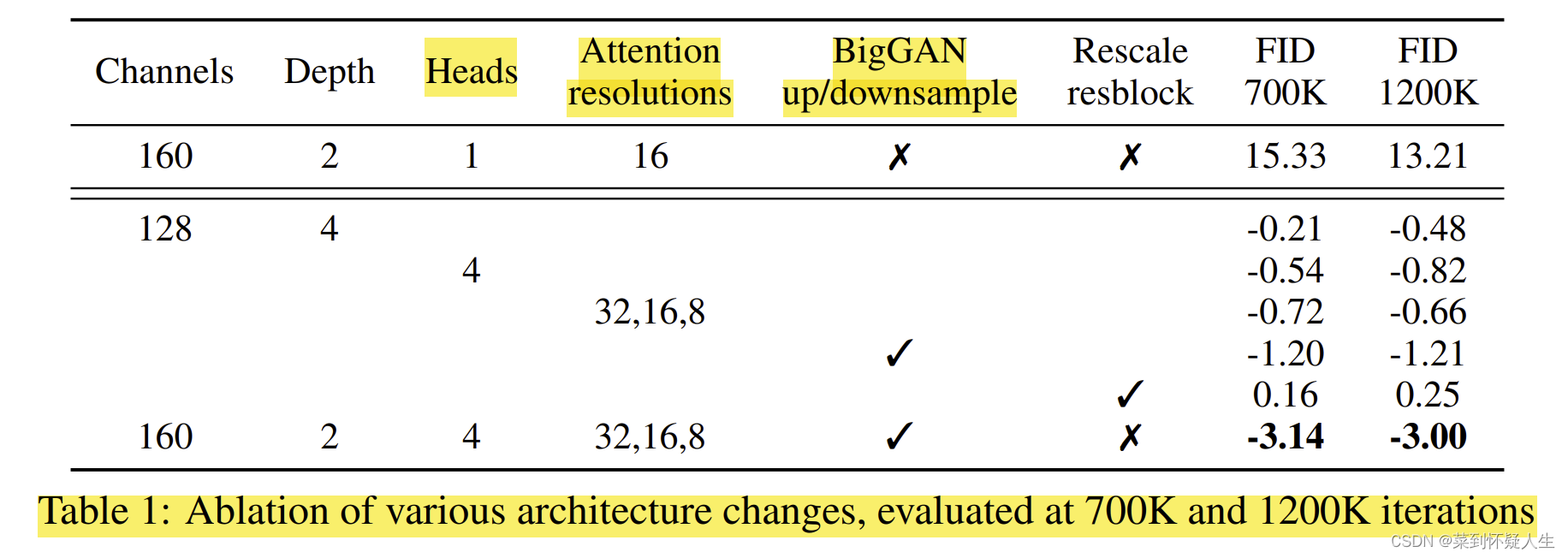
可以看到单独加深网络、或添加更多的self attention head、或在更多层使用self attention、或使用big gan的残差模块都可以提升diffusion model生成图像的质量。
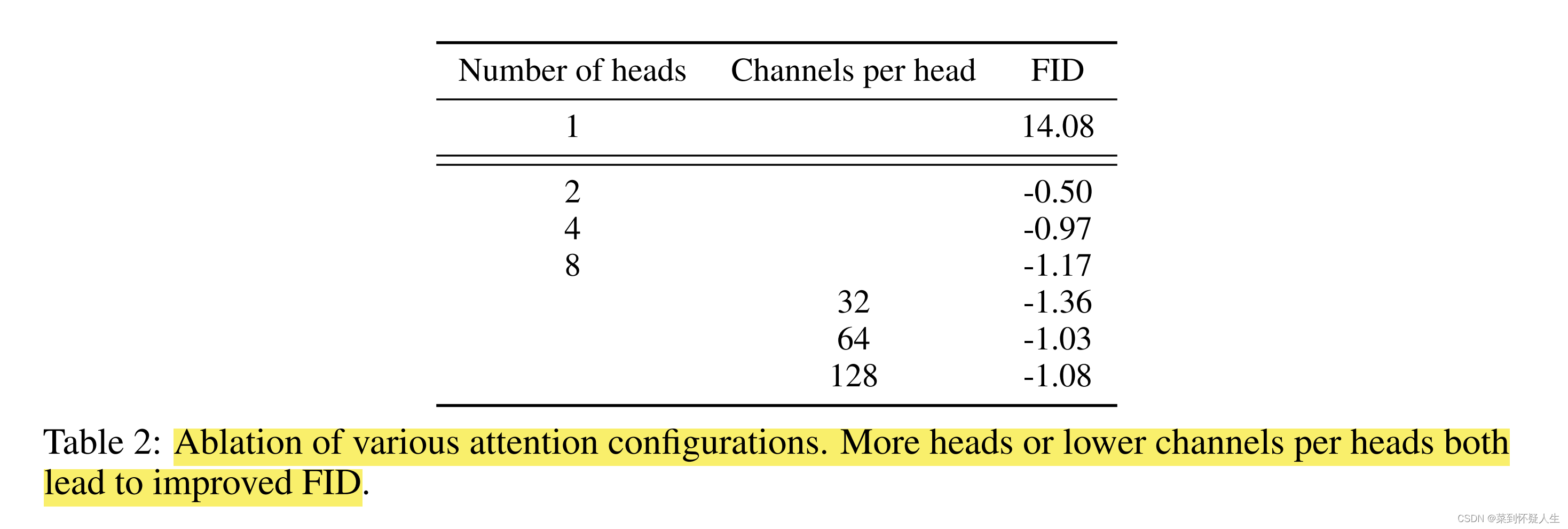
此外,作者探究了local attention和global attention对性能提升的影响。不论是local attention还是global attention,都是使用self attention作为注意力策略,但是进行注意力计算的feature map的个数不同。例如某一层共有256个特征图,特征图分辨率为4*4=16,将一个特征图看成一个token,则该层的特征图可转换为16*256大小的矩阵,global attention将在16*256大小的矩阵上进行self attention计算,而local attention则可将16*256大小的矩阵划分为4个4*256大小的矩阵,接着分别在4*256大小的矩阵上进行self attention操作。
作者探究了单独添加更多的global attention head,或者使用local attention head对生成图像质量的影响,最终发现两者均可以提升生成图像的质量,结果如下:
Classifier guidance
Classifier guidance用于控制扩散模型生成指定类型的图像,具体推导流程可以查阅前文
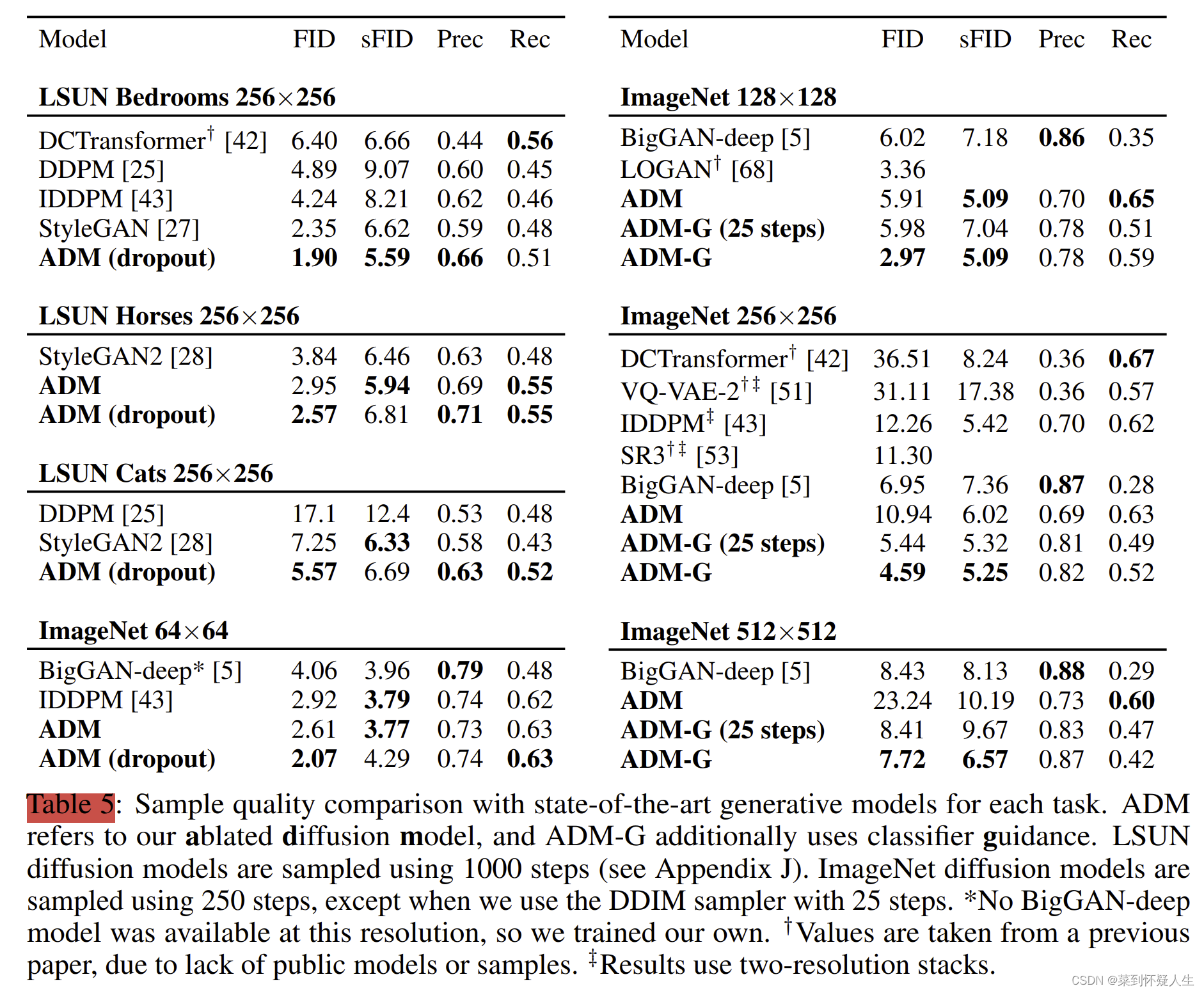
实验结果
ADM模型最终采取的配置为
For the rest of the architecture, we use 128 base channels, 2 residual blocks per resolution, multi-resolution attention, and BigGAN up/downsampling, and we train the models for 700K iterations.We opt to use 64 channels per head as our default.
实验结果
这篇关于深度学习(生成式模型)——ADM:Diffusion Models Beat GANs on Image Synthesis的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






