本文主要是介绍VideoComposer: Compositional Video Synthesis with Motion Controllability,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
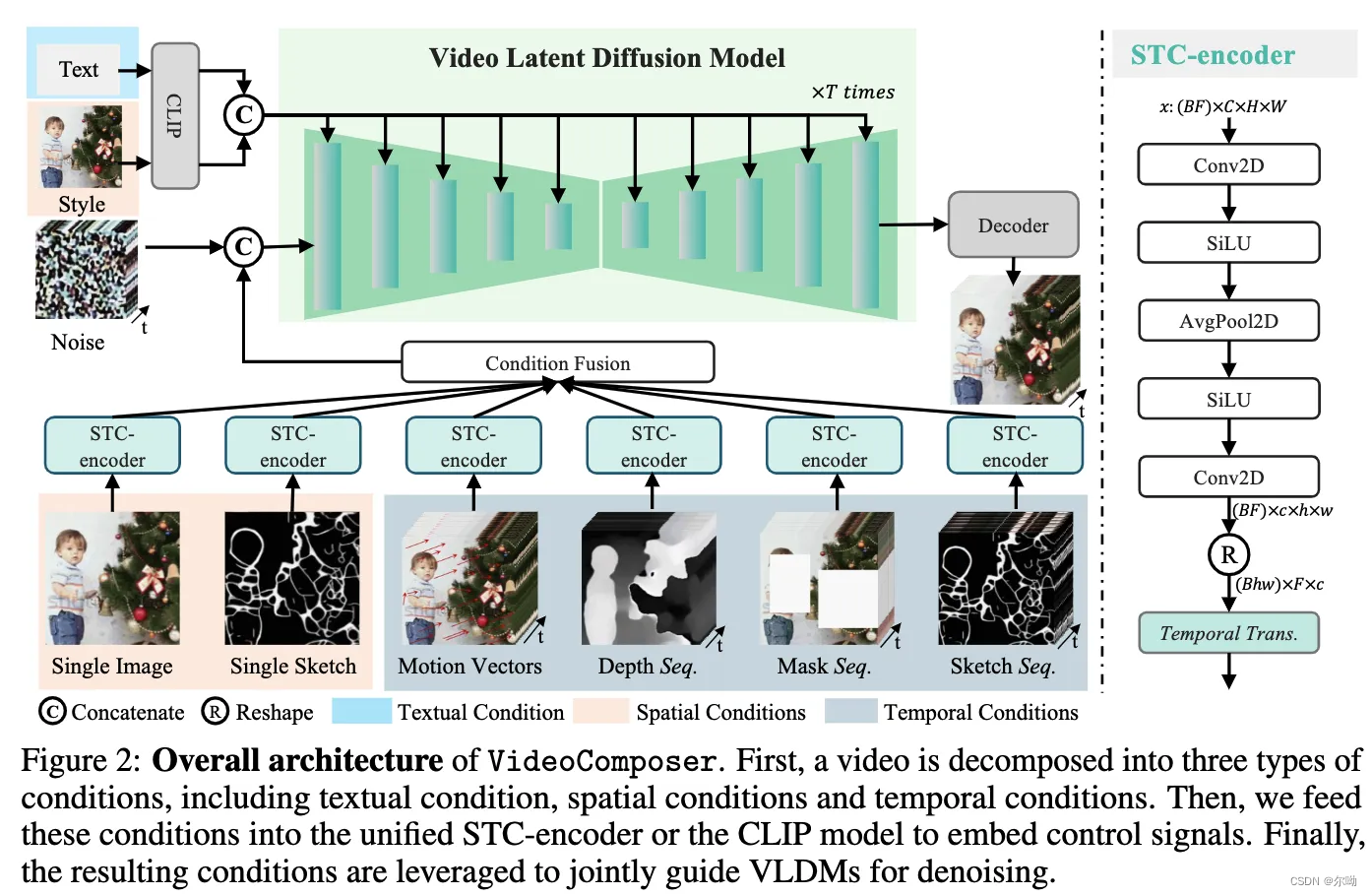
decompose videos into three distinct types of conditions: textual conditions, spatial conditions, temperal conditions
- 条件的内容:
a. textual condition: coarse grained visual content and motions, 使用openclip vit-H/14的text encoder
b. spatial condition: the goal is to achieve fine-grained spatial control
ⅰ. single image: a single image reveal the content and structure of this video, 使用视频的第一帧作为图生视频的spatial条件
ⅱ. single sketch: 使用PiDiNet提取第一帧的sketch
ⅲ. style: 为了将一张图片的风格迁移到视频,以图片的embedding作为条件,使用OpenCLIP ViT-H/14的image encoder
c. temporal conditions:
ⅰ. motion vector: 光流图
ⅱ. depth sequence: 使用预训练的深度估计模型来提取深度
ⅲ. mask sequence:为了editing和inpaint任务
ⅳ. sketch sequence - 条件的处理:所有的condition根据是否经过STC-encoder分为两类,一类是text和style(image embedding),通过cross attention来进行交互,另一类经过STC-encoder的condition,处理后的尺寸和视频的latent一样,所有的condition先首先element-wise add操作,之后和 x t x_t xt进行拼接输入到网络当中;
- 训练策略:两阶段训练,首先是预训练阶段,然后是带条件的视频生成训练;
- 推理:使用classifier free guidance ϵ ^ θ ( z t , c , t ) = ϵ θ ( z t , c 1 , t ) + w ( ϵ θ ( z t , c 2 , t ) − ϵ θ ( z t , c 1 , t ) ) \widehat\epsilon_\theta(z_t,c,t) = \epsilon_\theta(z_t,c_1,t) + w(\epsilon_\theta(z_t,c_2,t)-\epsilon_\theta(z_t,c_1,t)) ϵ θ(zt,c,t)=ϵθ(zt,c1,t)+w(ϵθ(zt,c2,t)−ϵθ(zt,c1,t))其中 c 1 c_1 c1和 c 2 c_2 c2是两组条件,强调 c 2 − c 1 c_2-c_1 c2−c1的条件,例如在text-driven video inpainting当中, c 2 c_2 c2表示caption+masked video, c 1 c_1 c1表示masked video;
- 实验:
a. 数据:使用了两个数据集webvid10M和LAION-400M
b. 评价指标:
ⅰ. 帧间一致性指标:计算相邻两帧的CLIP cosine similarity
ⅱ. motion control: 计算像素的预测光流和GT的欧式距离;
c. 首先展示了模型在组合控制条件来控制视频生成上面的能力,包括图生视频(+text)和视频inpainting以及根据sketch生成视频的能力,并展示相应的可视化效果;
d. 展示motion control的能力:
e. 消融实验:验证STC-encoder的有效性
这篇关于VideoComposer: Compositional Video Synthesis with Motion Controllability的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






