本文主要是介绍Tortoise-tts Better speech synthesis through scaling——TTS论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
笔记地址:https://flowus.cn/share/a79f6286-b48f-42be-8425-2b5d0880c648
【FlowUs 息流】tortoise
论文地址:
Better speech synthesis through scaling
Abstract:
自回归变换器和DDPM:自回归变换器(autoregressive transformers)是一种基于变换器架构的模型,能够处理序列数据,例如图像的像素。DDPM(深度概率模型,Deep Diffusion Probabilistic Models)是一种基于深度学习的概率模型,用于生成高质量的图像。 自回归变换器和DDPM被广泛应用于图像生成,它们利用大量的计算资源和数据来学习图像的分布,这意味着模型通过分析和学习大量图像数据来理解和复现图像的概率分布。
技术迁移:该方法论不仅限于图像生成,还可以应用于其他领域,如语音合成。
TorToise系统:这篇论文描述了一种将图像生成领域的进步应用于语音合成的方法。其结果是TorToise,这是一个富有表现力的多声音文本到语音合成系统。
所有的模型代码和训练好的权重都已在GitHub上开源,网址为:
GitHub - neonbjb/tortoise-tts: A multi-voice TTS system trained with an emphasis on quality
1.Background
1.1Text-to-speech
文本到语音研究领域主要集中于开发高效的模型,这些模型通常基于相对较小的数据集进行训练。这种选择主要受以下因素的驱动:
高效模型的需求:为了能够大规模部署,需要构建高效的语音生成模型,这些模型必须具有高采样率。
大型转录语音数据集的缺乏:很难获得大型、经过转录的语音数据集。
扩展传统TTS中使用的编解码器模型架构的挑战:传统的TTS技术在扩展时面临许多挑战。
1.1.1Neural MEL Invertes
神经MEL反转器,就是vocoder,声码器
MEL频谱编码:大多数现代文本到语音系统操作的是编码为MEL频谱的语音数据。MEL编码的一个主要优点是它高度空间压缩,意味着它可以在保留大部分信息的同时大幅度减小数据大小。例如,Tacotron使用的MEL配置相对于以22kHz采样的原始音频波形数据实现了256倍的压缩。
MEL频谱解码研究:由于MEL频谱的这些特性,一个专门的研究领域致力于找到高质量的方法,将MEL频谱再转换回音频波形。执行这一任务的合成器通常称为“声码器”,但在这篇论文中,作者更普遍地将其称为“MEL反转器”。
基于神经网络的MEL反转器:现代基于神经网络的MEL反转器非常复杂,它们产生的波形几乎与人类耳朵听到的录音波形无法区分,并且在训练集之外具有很高的泛化能力。作者利用这些研究成果,使用了Univnet(Kim, 2021)的实现作为其文本到语音系统的最终阶段。
1.2Image generation
与TTS系统主要关注延迟不同,图像生成领域更多地关注于训练能生成高质量结果的模型,而不太关心采样时间的长短。
1.2.1DALL-E
自回归解码器在图像生成中的应用:DALL-E(Ramesh等人,2021年)展示了如何将自回归解码器应用于文本到图像的生成。这一点特别吸引人,因为在NLP领域,已经有大量研究专注于扩展仅解码器模型。
DALL-E的问题:首先,DALL-E依赖于全序列自注意力,这带来了O(N²)的计算和存储成本,其中N是序列长度。其次,传统的自回归方法需要在离散域中操作。DALL-E使用量化自编码器将图像编码成离散的标记序列,然后使用自回归先验模型来模拟这些标记序列。这在表现力方面是DALL-E的一个优势,但它需要一个解码器将这些图像标记转换回实际组成图像的像素值。
1.2.2DDPMs
解决模糊性和模式崩溃问题:DDPM(Ho等人,2020年)最近作为一种能够产生清晰、连贯和多样化图像的生成模型而出现。这些模型非常有效地使用低质量的引导信号来重建这些信号来源的高维空间。换句话说,它们在超分辨率方面表现出色。
DDPM的局限性:传统的DDPM方法依赖于在采样开始前已知的固定输出形状。此外,DDPM的采样过程需要多次迭代,并且消耗大量计算资源,意味着总是会有显著的延迟成本。
1.2.3Re-ranking
自回归模型的输出过程:DALL-E引入了“重新排序”自回归模型输出的过程。这一过程从自回归模型中随机采样,并从k个输出中挑选最高质量的输出用于下游应用。
强大的鉴别器的需求:这种方法需要一个强大的鉴别器,即能够区分好的和不好的文本/图像配对的模型。DALL-E使用了CLIP(Radford等人,2021年),这是一个以对比文本和图像配对目标进行训练的模型。
2.Method
2.1Joining Autoregressive Decoders and DDPMs
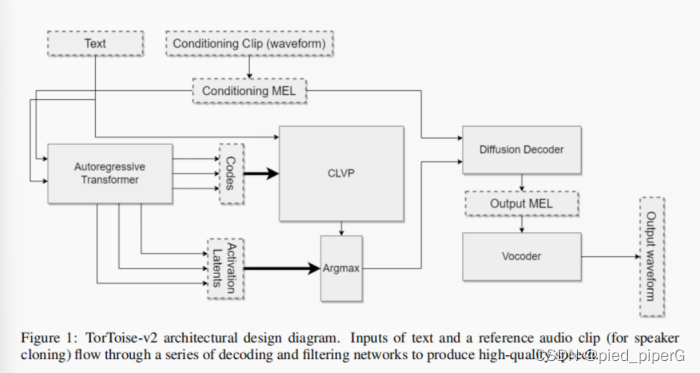
将自回归解码器和DDPM结合起来
首先回顾一下二者的优势:
自回归模型的优势:
- 自回归模型擅长在视觉、文本和语音等未对齐的领域之间进行转换。
- 它们通过将输入数据(如文本)转换成一系列的输出标记(如图像或语音的代表性标记)来工作。
DDPM的优势:
- DDPM在连续域中操作,使它们能够模拟表达性模态,如图像或语音的细微变化。
- DDPMs通过处理这些输出标记,将它们转换成高质量的连续数据表示,例如语音谱图或图像。
结合二者优两种模型类型都已经展示了随着计算和数据的增加而提升性能的能力。当面对像生成语音谱图或图像这样的连续数据问题时,结合这两种方法可能会带来独特的优势。
- 在推理过程中,首先使用自回归模型将一系列文本标记转换成代表输出空间的一系列标记(在这个案例中是语音标记)。
- 然后,使用DDPM将这些标记解码成高质量的语音表示。
2.2Applying Autoregression+DDPMs to TTS
为了构建之前提出的系统,需要训练以下几种神经网络:
自回归解码器:
- 预测基于文本的语音标记的概率分布。
- 这个解码器将文本转换成一系列代表语音的标记。
对比模型(类似于CLIP):
- 用于对自回归解码器的输出进行排序。
- 类似于CLIP的模型,用于评估和选择最佳的生成输出。
DDPM:
- 将语音标记转换回语音谱图。
- 这一步骤负责将标记转化为可以听到的语音。
2.2.1Conditinoing Input
- TorToise的独特设计选择:一个额外的输入被提供给自回归生成器和DDPM,被称为语音条件输入。
- 语音条件输入的处理:从一个或多个与目标相同说话者的音频剪辑开始,这些剪辑被转换为MEL谱图,并通过一个由自注意力层组成的编码器进行处理。
- 编码器的输出:这些层的输出被平均以产生单个向量。所有编码的条件剪辑的向量然后再次被平均,然后作为输入传递给自回归或条件网络。
2.2.2 The “TorToise Trick”
- 训练过程:在大部分训练过程中,DDPM被训练为将离散的语音代码转换成MEL谱图。在这一过程收敛后,对DDPM进行微调,使其基于从自回归模型输出中提取的潜在空间,而不是语音代码。
- 逻辑:自回归潜在空间比离散标记在语义上更丰富。通过在这个潜在空间上进行微调,可以提高下游扩散模型的效率。这种微调是提高模型输出质量的最大贡献者之一。
2.3CLVP
- 重新排序的策略:正如之前提到的,从生成模型中获取表达性输出的一个好策略是使用定性鉴别器重新排序多个输出,然后只选择最佳的。DALL-E使用CLIP来实现这一点。
- CLVP的应用:用于CLIP的这种方法同样可以应用于语音:大多数TTS数据集只是音频剪辑和文本的配对。通过在对比设置中对这些配对进行模型训练,模型成为了语音的有效鉴别器。
- TorToise中的CLVP:训练了Contrastive Language-Voice Pretrained Transformer(CLVP)。它具有CLIP的许多相同属性,但显著地用作在重新排序TTS输出中的评分模型。
- 高效推理:为了在推理中高效运作,CLVP被训练为将离散的语音标记与文本标记配对,这样CLVP可以在不调用昂贵的扩散模型的情况下重新排序多个自回归输出。
3.Training
- 训练环境:这些模型在8台NVIDIA RTX-3090显卡组成的小型集群上训练了一年时间。(一年...突然理解了为什么叫tortoise)

- 训练细节:关于这些模型的具体训练方法可以在论文文档的附录B中找到。
4.Inference Process
一旦框架的四个模型全部训练完成,推理过程如下:
输入条件和文本:将条件输入和文本输入到自回归模型,并解码出大量的输出候选项。
使用CLVP评分:使用CLVP为每个语音候选项和文本之间的相关性打分。
选择顶级候选项:选择排名最高的k个语音候选项,然后对每个候选项:
使用DDPM解码:使用DDPM解码成MEL谱图。
转换为波形:使用传统的声码器将其转换为波形。
自回归模型解码设置:在解码自回归模型时,使用核采样(nucleus sampling),设置P=0.8,重复惩罚=2,Softmax温度=0.8。
- DDPMs采样:采样自DDPMs是一个高度研究且快速变化的领域。在TorToise设计时,发现最佳平衡质量和推理速度的采样配置如下:
算法:DDIM(Song等人,2022年)
调度:线性
采样步骤:64
无条件引导常数:2
5.The Dataset
- 数据需求:由于目标是训练一个大型语言模型,因此需要大量数据。
- 初始数据集:开始使用的是LibriTTS(Zen等人,2019年)和HiFiTTS(Bakhturina等人,2021年)数据集,这两个数据集合计包含896小时的转录语音。
- 扩展数据集:构建了一个额外的“扩展”数据集,包含从互联网上抓取的有声书和播客的49,000小时语音音频。关于这个数据集是如何构建的细节在附录I中。
- 验证用数据集:使用官方的LibriTTS测试分割作为验证目的。
6.Experiments
- TTS系统的比较挑战:由于许多最先进的TTS系统是闭源的,且可比较样本较少,因此实验性比较TTS系统具有挑战性。
- 评估套件:为此,作者构建了自己的评估套件,使用CLVP生成实际样本和生成样本之间的距离度量,类似于用于图像的FID分数。
- “可理解性”度量:此外,还使用开源的wav2vec模型来表征语音片段的“可理解性”。
- 开源工作:作者已将这些工作开源。
- TorToise样本与其他论文样本的比较:可以在提供的链接中找到TorToise生成的样本与其他论文生成的样本之间的比较。
7.Conclusion
- TorToise的地位:TorToise是最近使用通用模型架构的一系列最新突破性成果中的最新成果之一。
- 对音频处理的应用:尽管TorToise几乎没有专门为音频处理设计的部分,但它在真实感方面超越了所有以前的TTS模型。
- 成功因素:TorToise的成功归因于以下几点:
采用通用架构:比如变换器层堆栈。
利用大型高质量数据集。
在较大规模和高批量大小下训练。
- 项目的主要启示:作者从这个项目中主要认识到,遵循上述三点可以获得非常强大的结果。作者认为,任何数字化的模态都可能适用于使用这个框架的生成建模。
这篇关于Tortoise-tts Better speech synthesis through scaling——TTS论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)