tts专题

使用Python实现文本转语音(TTS)并播放音频
《使用Python实现文本转语音(TTS)并播放音频》在开发涉及语音交互或需要语音提示的应用时,文本转语音(TTS)技术是一个非常实用的工具,下面我们来看看如何使用gTTS和playsound库将文本... 目录什么是 gTTS 和 playsound安装依赖库实现步骤 1. 导入库2. 定义文本和语言 3

AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出
AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出 在数字化时代,文本到语音(Text-to-Speech, TTS)技术已成为人机交互的关键桥梁,无论是为视障人士提供辅助阅读,还是为智能助手注入声音的灵魂,TTS 技术都扮演着至关重要的角色。从最初的拼接式方法到参数化技术,再到现今的深度学习解决方案,TTS 技术经历了一段长足的进步。这篇文章将带您穿越时

调用火山云的语音生成TTS和语音识别STT
首先需要去火山云的控制台开通TTS和STT服务语音技术 (volcengine.com) 火山这里都提供了免费的额度可以使用 我这里是使用了java来调用API 目前我还了解到阿里的开源项目SenseVoice(STT)和CosyVoice(TTS)非常的不错,但是都是使用Python开发的。可以做到说话情绪的识别,感兴趣可以去github上了解一下。 TTS(首先需要导入它给的类) p
强大的EmotiVoice:易魔声 : 多音色提示控制TTS
EmotiVoice是一个强大的开源TTS引擎,完全免费,支持中英文双语,包含2000多种不同的音色,以及特色的情感合成功能,支持合成包含快乐、兴奋、悲伤、愤怒等广泛情感的语音。 EmotiVoice提供一个易于使用的web界面,还有用于批量生成结果的脚本接口。 gitee镜像:https://gitee.com/mirrors/EmotiVoice MAC下有一键安装包 可以用doc

深度学习系列69:tts技术原理
tts为text-to-speech,asr为Automatic Speech Recognition,即speech-to-text。 1. 常用基础模型 下面介绍的deep voice是端到端生成语音的模型,后面两个是生成Mel谱,然后再使用vocoder生成语音的模型。 1.1 Deep voice 目前端到端的是主流,其整体流程如下图: 步骤1:语素转音素 用的比较多的是语
【原创】edge-tts与基于mpv的edge-playback,使命令行和Python的Text To Speech唾手可得
最近想用Python脚本写一个TTS的小工具。一顿查找下来,发现AI时代手机端上这么普遍的TTS功能,居然在Web上这么稀有。估计都是被云API厂商拿去赚钱了。幸好Edge浏览器还是比较良心地提供了这个功能,不过又是和浏览器紧密结合的。 最终功夫不负有心人,发现了edge-tts与edge-playback,使命令行和Python脚本的Text To Speech唾手可得。先记录下来,找时间再丰
Android Studio开发安卓app TTS文字转语音功能 android11系统无法调用TTS问题记录
Android Studio开发安卓app TTS文字转语音功能 android11系统无法调用TTS问题记录 同样的apk,android9可以叫号,android11无法叫号 排查代码发现textToSpeech.speak 函数返回了 -1, 说明调用安卓的 文字转语音方法失败 textToSpeech.speak(text, TextToSpeech.QUEUE_FLUSH, n

腾讯tts获取文件blob推流解析
方案1,获取推流拼接到数据,播放时将 Blob 转换为 URL,把audioUrl赋值给 ws.onmessage((res) => {// console.log('onmessage res.data',res.data)if (typeof res.data == "object") {blobs.value.push(res.data);const newBolb = new Blob
9个最流行的文本转语音引擎【TTS 2024】
在快速发展的技术世界中,文本转语音 (TTS) 引擎正在取得显著进步。从增强各种应用程序中的用户体验到创建逼真且引起情感共鸣的语音输出,TTS 引擎正变得不可或缺。在这里,我们介绍了 2024 年为行业树立新标准的九款最佳 TTS 引擎。 NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D

AI 音频/文本对话机器人:Whisper+Edge TTS+OpenAI API构建语音与文本交互系统(简易版)
文章目录 前言思路:环境配置代码1. 加载Whisper模型2. 使用Whisper语音转文本3. 使用OpenAI API生成文本进行智能问答4. 实现文本转语音功能5. 合并音频文件6. 构建Gradio界面注意 总结 前言 在本篇博客中,我将分享如何利用Whisper模型进行语音转文本(ASR),通过Edge TTS实现文本转语音(TTS),并结合OpenAI AP
![Edge-TTS:微软推出的,免费、开源、支持多种中文语音语色的AI工具[Python代码]](https://i-blog.csdnimg.cn/direct/6acbb6eb2f7649e697772f387d5511d9.png)
Edge-TTS:微软推出的,免费、开源、支持多种中文语音语色的AI工具[Python代码]
Edge-TTS,由微软推出的这款免费、开源的AI工具,为用户带来了丰富多样的中文语音体验。它不仅支持多种中文语音语色,还能实现流畅自然的语音合成。Edge-TTS凭借其高度可定制化的特点,广泛应用于智能助手、语音播报、教育培训等领域。这款工具的操作简便,兼容性强,让开发者能够轻松集成到各种应用中。最重要的是,Edge-TTS始终保持免费开源,为中文语音合成技术的研究与发展提供了有力支持,助力我国
探索Edge-TTS与WebSocket集成:打造实时语音交互系统
本文为实现 WebSocket 将文本转换为语音并返回 Base64 数据给 Vue 客户端【干货】 在本文中,我们将构建一个简单的系统,该系统能够接收文本输入,通过 Microsoft Edge 的文本到语音服务(Edge TTS)转换为语音,并将生成的语音数据以 Base64 编码的形式通过 WebSocket 传输给 Vue 客户端。 后端: Python 3.10 WebSocket:

最新轻量级文本转语音,parler-tts模型部署
Parler-TTS是一个由 Hugging Face 推出的开源文本转语音的模型。 Parler-TTS能够根据文本提示生成高质量、自然听起来的语音,并且能够模仿特定说话者的风格,如性别、音调和说话风格等。 Parler-TTS的架构基于MusicGen,包含文本编码器、解码器和音频编解码器,通过集成文本描述和添加嵌入层优化了声音生成。 Parler-TTS发布了两个模型,一个是参数量为
TTS 文本 vs SSML
给个例子: MRCP/2.0 246 SPEAK 1 Channel-Identifier: b227c392d70b478e@speechsynth Content-Type: text/plain Voice-Name: xx Content-Length: 11 How are you 其中 Content-Type 是文本 那么 FreeSWITCH 能不能让 Content

AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱,突破性 OCR 技术:支持多种语言识别,媲美顶级云服务
AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱,突破性 OCR 技术:支持多种语言识别,媲美顶级云服务。 AI文本转语音:Toucan TTS 支持 7000 多种语言的语音合成工具箱 Toucan TTS是由德国斯图加特大学自然语言处理研究所(MS)精心打造的文本转语音(TTS)工具箱,它支持超过7000种语言,包括多样的方言和语言变体。这款工具箱建立在P

微软TTS最新模型,发布9种更真实的AI语音
很高兴与大家分享 Azure AI 语音翻译产品套件的两个重大更新: 视频翻译和增强的实时语音翻译 API。 视频翻译(批量) 今天,我们宣布推出视频翻译预览版,这是一项突破性的服务,旨在改变企业本地化视频内容的方式。随着全球市场对可访问且引人入胜的视频内容的需求不断增长,视频翻译提供了一种无缝解决方案来克服语言障碍。此次发布包括 Azure Speech,客户可以使用自己的视频资产进行试用
AI大模型的TTS评测
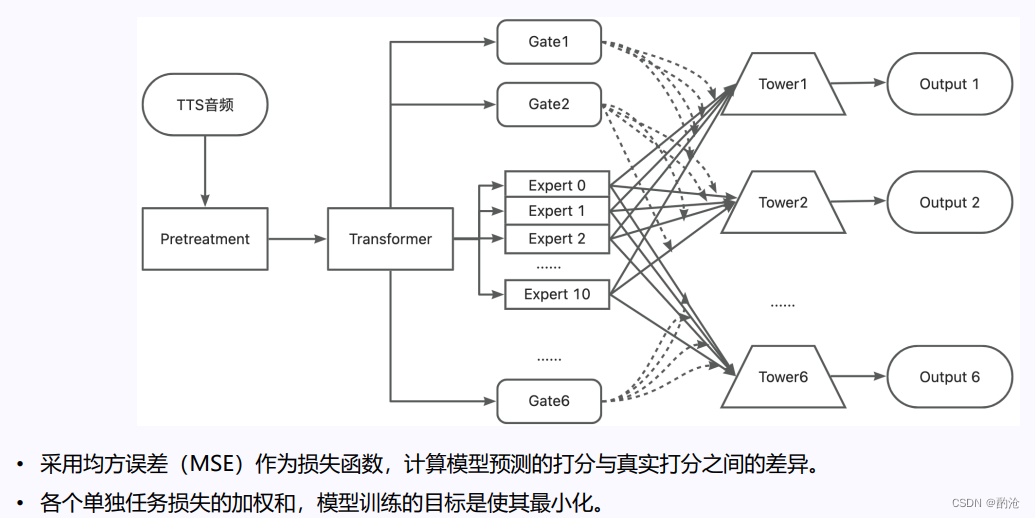
L-MTL(Large Multi-Task Learning)Models 是一种大规模多任务学习模型,通过结合 Mixture of Experts(MMoE)框架与 Transformer 模型,实现对 TTS(Text-to-Speech)系统中多个评估指标的全面平衡评价。 1 L-MTL Models 的基本架构和工作机制 说明了 L-MTL 的评价指标如何构建,通过减少模型复杂
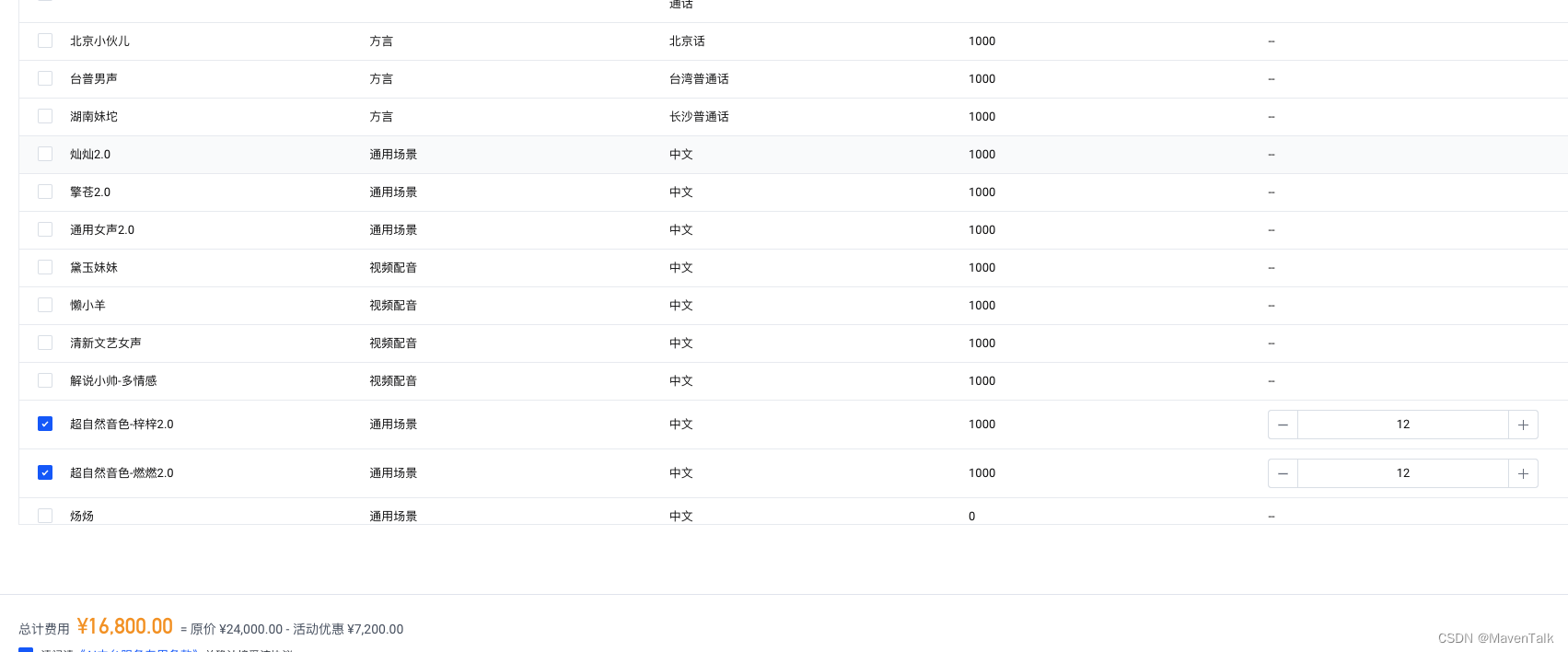
AI产品组件——TTS产品
语音合成TTS 序列猴子TTS,每个发音人付费标准不同,通过序列猴子开放平台使用。 微软TTS,采用信用卡后付费模式。Speech Studio,付费模式采用统一付费的形式,音效有一款女声效果逼真。 女声:晓晓,多语言版,针对中文发音时,某些数字如条目里的数字项,会进行英语发音,需要加语言限制zh-CN。能正常发音。流式语音切分时,SSE模式,“1.顺”要切分成“1,顺”才能正常阅读,否则

一个轻量级的TTS模型实现
1.环境 python 版本 3.9 2.训练数据集 本次采用LJSpeech数据集,百度网盘下载地址 链接:https://pan.baidu.com/s/1DDFmPpHQrTR_NvjAfwX-QA 提取码:1234 3.安装依赖 pip install TTS 4.工程结构 5代码部分 decoder.py import torchfrom torch impor
豆包高质量声音有望复现-Seed-TTS
我们介绍了 Seed-TTS,这是一个大规模自回归文本转语音 (TTS) 模型系列,能够生成与人类语音几乎没有区别的语音。Seed-TTS 作为语音生成的基础模型,在语音上下文学习方面表现出色,在说话人的相似性和自然性方面取得了与客观和主观评估中基本人类语音相匹配的表现。通过微调,我们在这些指标上获得了更高的主观分数。Seed-TTS 对各种语音属性(如情感)具有卓越的可控性,并且能够为野外的说话
手把手教学!新一代 Kaldi: TTS Runtime ASR 实时本地语音识别 语音合成来啦
简介 本文向大家介绍如何在新一代 Kaldi的部署框架 **sherpa-onnx**中使用 TTS。 注:sherpa-onnx 提供的是一个TTS runtime, 即部署环境。它并不支持模型训练。 本文使用的测试模型,都是来源于网上开源的 VITS 预训练模型。 我们提供了 ONNX 导出的支持。如果你也有 VITS 预训练模型,欢迎尝试使用 sherpa-onnx 进行部署。

Chat-TTS:windows本地部署实践【有手就行】
最近Chat-TTS模型很火,生成的语音以假乱真,几乎听不出AI的味道。我自己在本地部署玩了一下,记录一下其中遇到的问题。 环境: 系统:windows 11 GPU: Nvidia 4060 Cuda:12.1(建议安装12.1版本,最新的12.4需要自己编程pyotrch包) cudnn: 9.2 注意:在windows x86平台上建议使用conda虚拟环境来管理python

王炸级产品:字节跳动的Seed-TTS
在人工智能的快速发展中,文本到语音(TTS)技术已成为连接数字世界与人类沟通的重要桥梁。而字节跳动推出的Seed-TTS模型,无疑是这一领域的一个突破性进展,它以其卓越的性能和高度的自然度,被誉为TTS模型中的“王炸级产品”。 接近完美的语音生成 Seed-TTS模型之所以能够引起业界的广泛关注,是因为它在生成语音的自然度和相似度上几乎达到了完美的水平。它能够无需经过长时间的训练,仅通过一

字节跳动Seed-TTS文本到语音模型家族
字节跳动的SEED TTS(Seed-TTS)是一系列大规模自回归文本转语音(TTS)模型,能够生成与人类语音几乎没有区别的高质量语音。该模型在语音上下文学习方面表现出色,尤其在说话者相似度和自然度方面的表现,与真实人类语音相匹配。 1 模型架构 1.1 模型架构组成 Seed-TTS 模型主要由语音分词器、语言模型、扩散模型、 语音合成器组成。 1.1.1 语音分词器
Microsoft Edge TTS引擎实现文字转语音小工具
Microsoft Edge TTS引擎实现文字转语音小工具 看了一篇文章关于使用Microsoft Edge TTS引擎进行文本转语音的介绍。正好单位工作上经常用到音视频的制作和转换。但是文字变成音频一直都是播音员口播实现。现在到了AI时代,各种功能强大的AI大模型已经应用到各个领域,大大提高了工作、生产和学习的效率。受到此文启发,根据自己的实际需要,进行定制,实现文本转成音频。 功能介

ChatTTS改良版 - 高度逼真的人类情感文本生成语音工具(TTS)本地一键整合包下
先介绍下ChatTTS 和之前发布的 Fish Speech 类似,都是免费开源的文本生成语音的AI软件,但不同的是,ChatTTS测试下来,对于人类情感语调的模仿,应该是目前开源项目做的最好的,是一款高度接近人类情感、音色、语调的文本语音合成项目。不像其他的语音合成项目,出来的音调很生硬,一听就知道是合成的。ChatTTS的合成效果,高度模仿人类情感,不仔细听,根本分不清是真人还是合成。关键是开