本文主要是介绍Chat-TTS:windows本地部署实践【有手就行】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近Chat-TTS模型很火,生成的语音以假乱真,几乎听不出AI的味道。我自己在本地部署玩了一下,记录一下其中遇到的问题。
环境:
系统:windows 11
GPU: Nvidia 4060
Cuda:12.1(建议安装12.1版本,最新的12.4需要自己编程pyotrch包)
cudnn: 9.2
注意:在windows x86平台上建议使用conda虚拟环境来管理python包,很重要的一点是项目依赖的pynini不能在windows x86平台上编译安装,但是可以通过conda提供的二进制包来安装,省去了很多麻烦。
下载文件:
-
下载项目代码:
git clone https://github.com/2noise/ChatTTS.git -
下载模型权重文件,我使用的是阿里的modelscope,国内下载比较快。 https://modelscope.cn/models/pzc163/chatTTS/summary
(有条件可以连接huggingface的,也可以不用自己提前下载,直接运行代码等待自动下载。)
使用modelscope,可以手动在页面下载,或者通过其提供的SDK下载,使用SDK下载会将模型保存在C:\Users\<你的用户名>\.cache\modelscope路径下。因为是本地加载模型,我将下载模型文件复制到了当前模型工作路径下F:\Chat-TTS\ChatTTS\model\chatTTS,方便使用。
安装依赖包:
-
进入下载的ChatTTS项目目录,创建一个新的conda环境
conda create -n tts python==3.11.8.我使用了python3.11版本,这个根据自己喜好随意选择。 -
创建好环境后激活
conda activate tts. -
安装环境依赖
pip install -r requirements.txt, 开始根据项目提供的依赖进行安装第三方库。 -
其中安装pytorch2.1.2的cuda版本从pytorch的官方源下载比较慢,可以使用阿里的镜像仓库地址:https://mirrors.aliyun.com/pytorch-wheels/cu121/ 从其中下载和自己cuda、python版本匹配的包,如我这里使用的是 pytorch2.1.2, py11,cuda12.1的
torch-2.1.2+cu121-cp311-cp311-win_amd64.whl. -
另外,模型运行的时候还要额外安装几个依赖库,这我我一并列出,不在下面赘述:
conda install -c conda-forge pynini=2.1.5 pip install nemo_text_processing pip install WeTextProcessing
尝试运行项目:
-
在项目目录下打开
example.ipynb, 尝试修改并运行官方给的示例

-
首先修改模型加载方式为本地加载:
注释掉原来代码,然后改为本地加载并指定模型的存放路径。如果电脑有gpu可以设置device为
cuda来提高模型推理速度,最后因为是在win平台,pytorch的dynamo图模式,不支持compile,所以将compile参数设置为False.

-
执行推理:
模型加载完成后,即可开始执行推理,点击当前的运行按钮,gpu开行执行推理并将结果保存为音频文件。
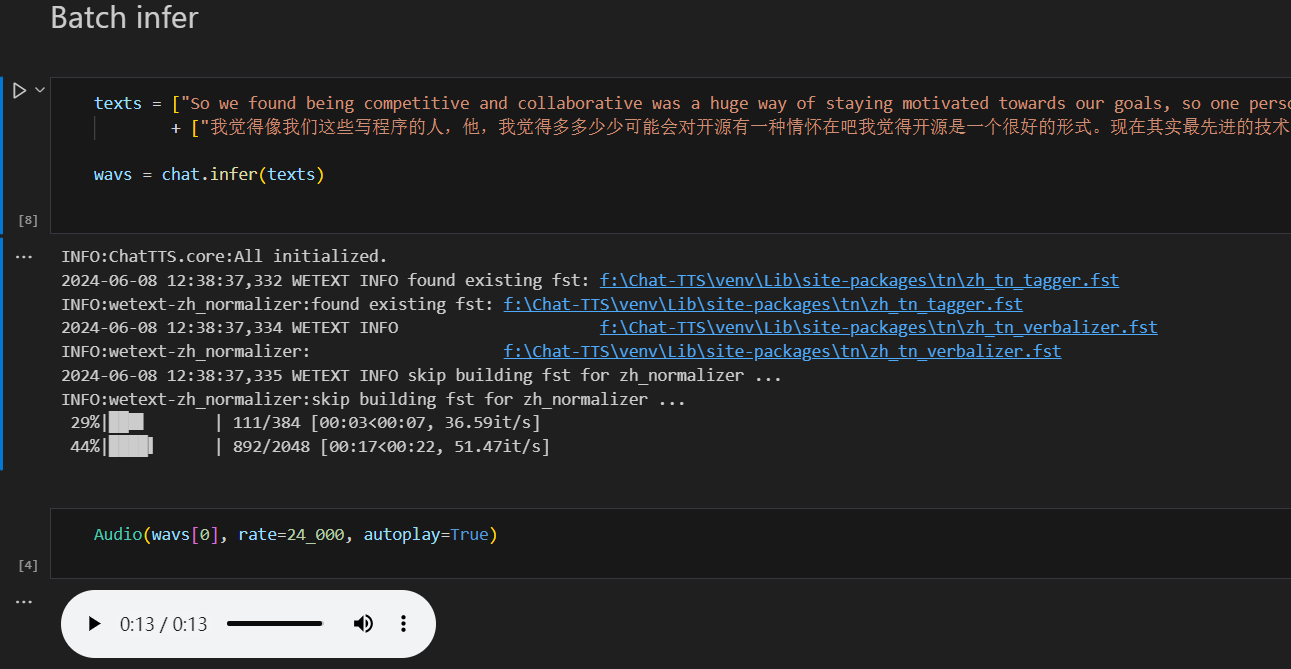 到这里成功的话就说明模型的推理流程已经通了。
到这里成功的话就说明模型的推理流程已经通了。
但是通过代码的方式运行起来还是比较麻烦,不过项目还提供了webui来使用,这样调节语音生成的参数也更直观方便。
运行webui:
-
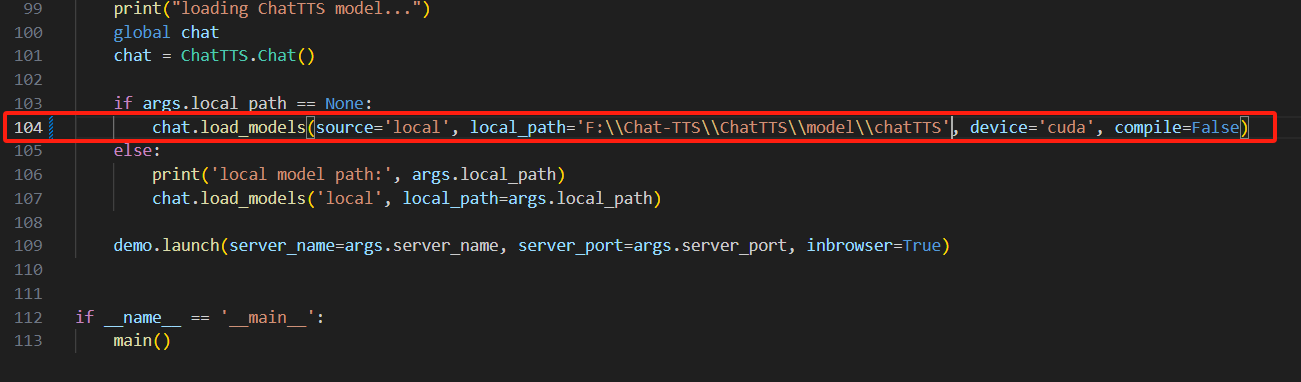
和上面一样,修改模型的加载参数为本地:
其实本地加载参数可以通过在启动时添加参数传入的,但是为了方便,这里我就讲默认的参数直接改为本地启动:
-
执行webui.py文件:执行后浏览器会自动打开webui页面,或者自己输入http://localhost:8080/来打开。
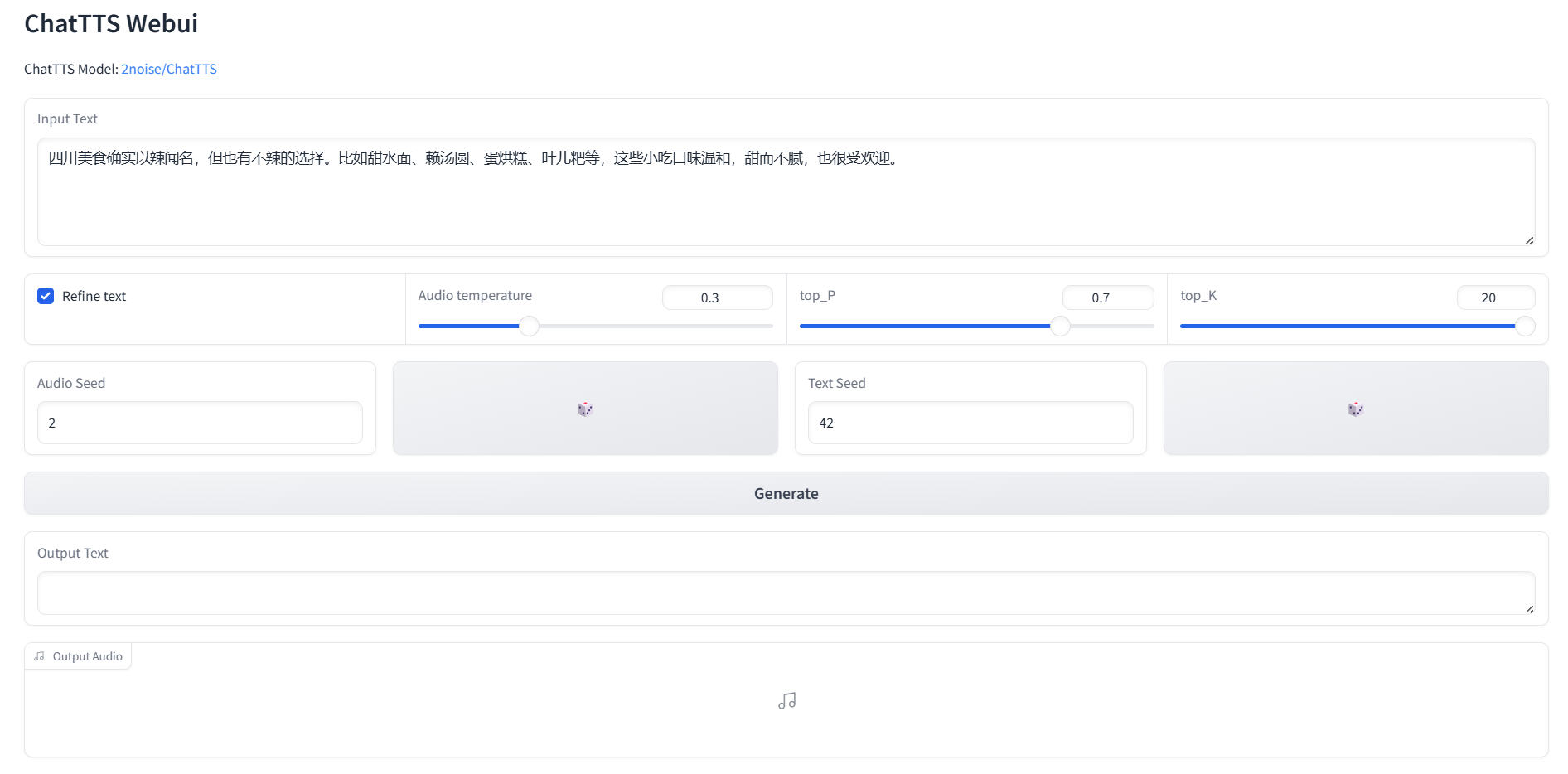
接下来的使用就是抽卡了,我们可以自行修改音频生成的种子数,和文本种子,个人感觉这个生成音色的随机性比较大,没什么规律可言,想抽到自己喜欢的音色只能不停的尝试。
生成过程中,模型会自动给文本插入一下语气词、连接词之类的,让文本读起来更自然。

好了,总体来说模型部署还是比较简单的,希望大家也能一次性跑起来。
这篇关于Chat-TTS:windows本地部署实践【有手就行】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






