本文主要是介绍豆包高质量声音有望复现-Seed-TTS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们介绍了 Seed-TTS,这是一个大规模自回归文本转语音 (TTS) 模型系列,能够生成与人类语音几乎没有区别的语音。Seed-TTS 作为语音生成的基础模型,在语音上下文学习方面表现出色,在说话人的相似性和自然性方面取得了与客观和主观评估中基本人类语音相匹配的表现。通过微调,我们在这些指标上获得了更高的主观分数。Seed-TTS 对各种语音属性(如情感)具有卓越的可控性,并且能够为野外的说话者生成高度富有表现力和多样化的语音。此外,我们提出了一种用于语音分解的自蒸馏方法,以及一种增强模型鲁棒性、说话人相似性和可控性的强化学习方法。我们还提出了 Seed-TTS 模型的非自回归 (NAR) 变体,称为 Seed-TTS DiT ,它利用完全基于扩散的架构。与以前基于NAR的TTS系统不同,Seed-TTS DiT 不依赖于预先估计的音素持续时间,而是通过端到端处理来执行语音生成。我们证明了该变体在客观和主观评估中都实现了与基于语言模型的变体相当的性能,并展示了其在语音编辑中的有效性。
项目地址:https://bytedancespeech.github.io/seedtts_tech_report
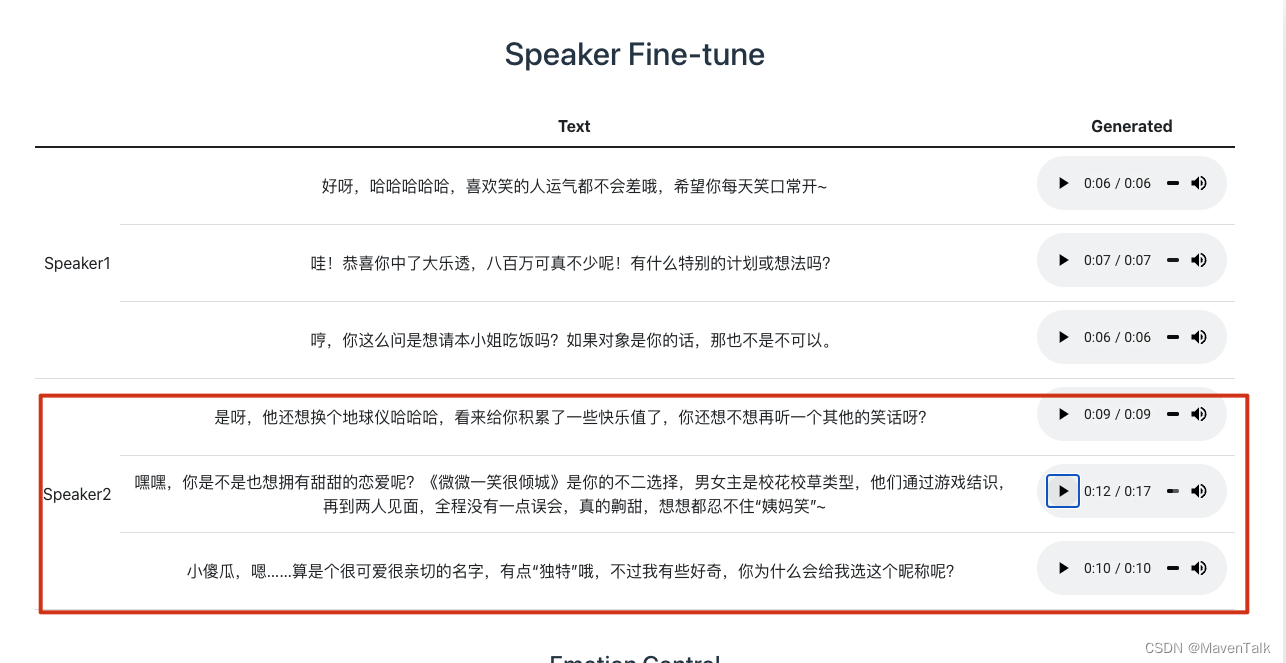
特别是Speaker2的发间,几乎与豆包里面【温柔桃子】的声音近似,期待好声音早些面世,科技引领生活。
跨语言部分更是惊艳
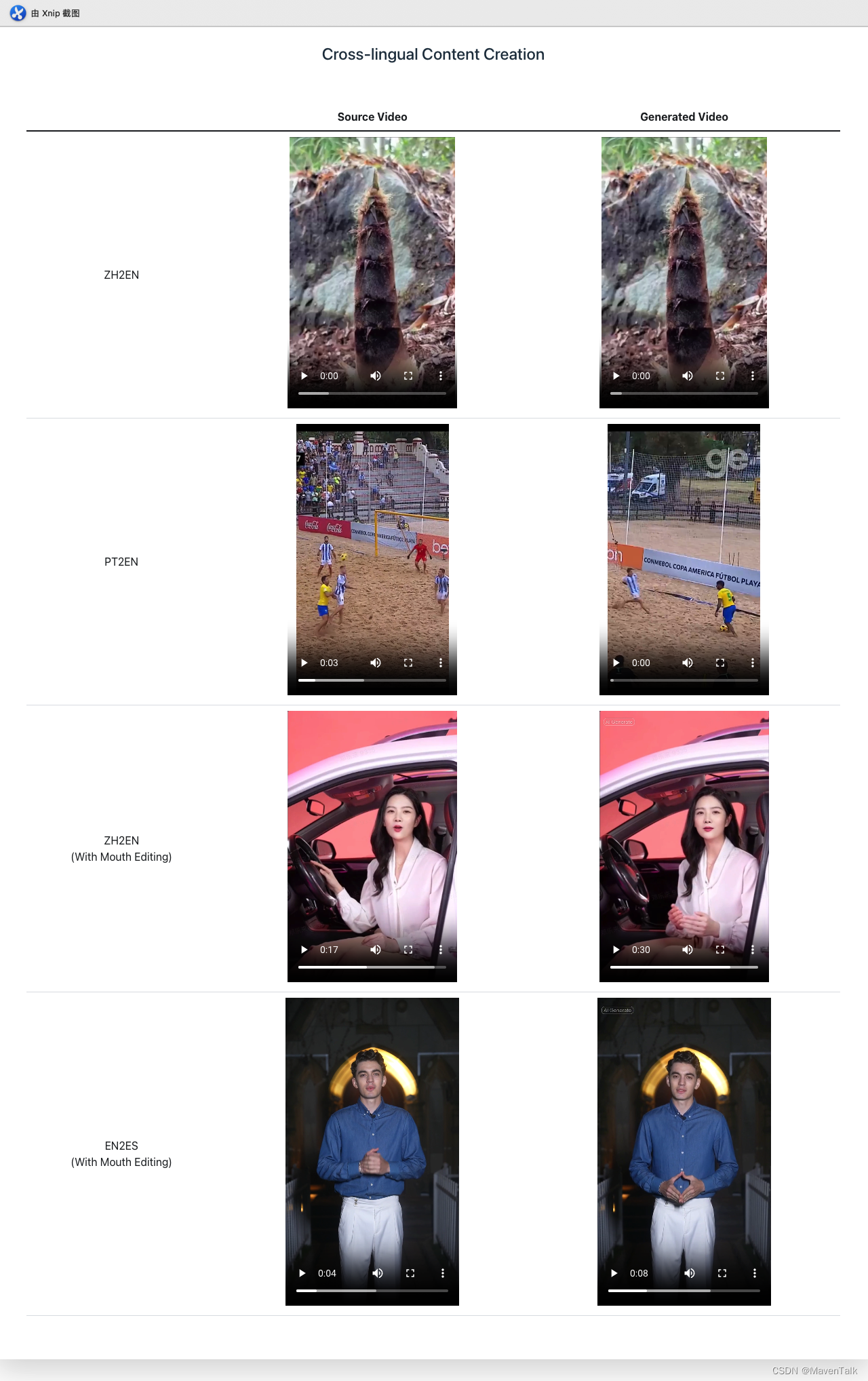
这篇关于豆包高质量声音有望复现-Seed-TTS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![好用的AI编程助手MarsCode[豆包]](https://i-blog.csdnimg.cn/direct/093df079c92845e1acbfe12cbafe4f49.png)