seed专题

微软发布 Phi-3.5 系列模型,涵盖端侧、多模态、MOE;字节 Seed-ASR:自动识别多语言丨 RTE 开发者日报
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。 本期编辑:@SSN,@鲍勃 01 有话题的新闻

豆包高质量声音有望复现-Seed-TTS
我们介绍了 Seed-TTS,这是一个大规模自回归文本转语音 (TTS) 模型系列,能够生成与人类语音几乎没有区别的语音。Seed-TTS 作为语音生成的基础模型,在语音上下文学习方面表现出色,在说话人的相似性和自然性方面取得了与客观和主观评估中基本人类语音相匹配的表现。通过微调,我们在这些指标上获得了更高的主观分数。Seed-TTS 对各种语音属性(如情感)具有卓越的可控性,并且能够为野外的说话
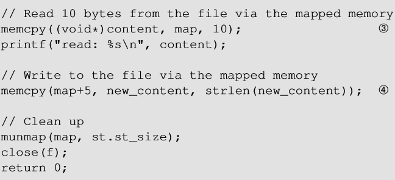
seed-labs (脏牛竞态攻击)
软件安全-脏牛竞态攻击 概要mmap() 函数进行内存映射MAP_SHARED MAP_PRIVATE 写时拷贝映射只读文件脏牛漏洞problems 概要 该漏洞存在于linux内核的写时复制代码中,攻击者可以通过该漏洞获取root权限 mmap() 函数进行内存映射 mmap():将文件或设备映射到内存的系统调用。默认的映射类型是文件备份映射,它将进程的虚拟内存区域映射到

seed-labs 竞态条件漏洞
软件安全-竞态条件漏洞 竞态条件漏洞概述一个常见的漏洞实验 防御手段原子化重复检查和使用粘滞符号链接保护最小权限原则 problems 竞态条件漏洞 概述 竞态条件是指一个系统或程序的输出结果取决于其他不可控制事件执行的时间顺序 一个常见的漏洞 当一个程序的两个并发线程同时访问共享资源时,如果执行时间和顺序不同,会产生影响,这时就称作发生了竞态条件 检查时间和使用时间。如

seed-labs(return-to-libc)
软件安全-return-to-libc 概要攻击环境攻击阶段找到system()函数的地址找到字符串/bin/sh的地址 第二部分 return-to-libc函数的序言 返回导向编程problems 概要 缓冲区溢出漏洞是把恶意代码注入到目标程序栈中发动攻击。为了抵御这种攻击,操作系统采用一个称为不可执行栈 的防御措施。这种防御措施能被另一种无须在栈中运行代码的攻击方法绕过,这
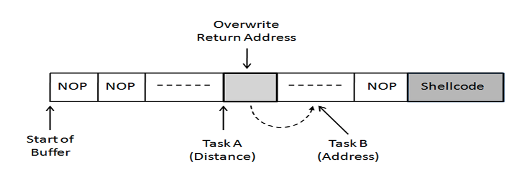
seed-labs (软件安全-缓冲区溢出攻击)
软件安全-缓冲区溢出攻击 缓冲区溢出程序的内存分别栈与函数调用栈的内存布局帧指针 栈的缓冲区溢出攻击将数据复制到缓冲区缓冲区溢出 环境准备构造输入文件 构造shellcodeC语言编写恶意代码构造shellcode的核心方法shellcode 实例 防御措施概述 problem 缓冲区溢出 了解堆栈布局 易受攻击的代码 开发方面的挑战 外壳代码 对策 程序的内存分别 为了深

seed-labs 软件部分-shellshock
seed-labs 软件部分- shellshock shellshock背景shellshock 漏洞定义漏洞bash源码中的错误shellshock漏洞利用 利用shellshock攻击CGI程序web服务器调用CGI程序反向shell problems shellshock 背景 Shell程序是操作系统中的命令行解释器 提供用户和操作系统之间的接口 不同类型的shel

Android Monkey测试入门-5-Monkey高级参数之seed
前面一篇我们学习了Monkey的高级参数之throttle,主要是用来控住执行速度。这篇,介绍另外一个高级参数seed。seed是什么意思呢,神奇的种子吗?先来,思考这么一个场景,我们用monkey做随机操作,结果发现了一个bug。如果我们用之前学过的命令,由于monkey是随机产生事件,所以,我们是没有办法去重复当时出现bug的步骤的。如果你学习了seed之后呢,这个问题就很好解决

王炸级产品:字节跳动的Seed-TTS
在人工智能的快速发展中,文本到语音(TTS)技术已成为连接数字世界与人类沟通的重要桥梁。而字节跳动推出的Seed-TTS模型,无疑是这一领域的一个突破性进展,它以其卓越的性能和高度的自然度,被誉为TTS模型中的“王炸级产品”。 接近完美的语音生成 Seed-TTS模型之所以能够引起业界的广泛关注,是因为它在生成语音的自然度和相似度上几乎达到了完美的水平。它能够无需经过长时间的训练,仅通过一

字节跳动Seed-TTS文本到语音模型家族
字节跳动的SEED TTS(Seed-TTS)是一系列大规模自回归文本转语音(TTS)模型,能够生成与人类语音几乎没有区别的高质量语音。该模型在语音上下文学习方面表现出色,尤其在说话者相似度和自然度方面的表现,与真实人类语音相匹配。 1 模型架构 1.1 模型架构组成 Seed-TTS 模型主要由语音分词器、语言模型、扩散模型、 语音合成器组成。 1.1.1 语音分词器

ZOJ 2100 seed
挺简单的深搜题。。但是因为粗心,跑完一个test case后没有正确地更新field数组(开始时为求精简竟然在格子(i,j)为 false时不令field[i][j] = false,原因是我以为field[6][6]是全局变量,默认情况是初始化为false,所以想当然地以为如果格子(i,j)是false就不用多次一举。。可是我忘了每次运行一个test case后field会改的。

tf.nn.conv2,cross_entropy,loss,sklearn.preprocessing,next_batch,truncated_normal,seed,shuffle,argmax
tf.truncated_normal https://www.tensorflow.org/api_docs/python/tf/random/truncated_normal truncated_normal( shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None ) seed: 随机种子,若 seed 赋值
random.seed()
random.seed(seed) 是 Python 标准 random 模块中的一个函数调用,它用于确保随机数生成器产生可重复的结果。这在科学计算和机器学习中非常重要,因为它允许研究者和开发者重现实验结果。 seed 通常是一个整数,用作随机数生成器的种子值。当你在脚本或程序中使用 random.seed() 并传入一个特定的种子值时,随机数生成器将从一个已知的状态开始,因此每次运行代
Java random随机数/ seed 种子 / System.nanoTime() 的理解 与 使用
伪随机(preundorandom):通过算法产生的随机数都是伪随机!! 只有通过真实的随机事件产生的随机数才是真随机!!比如,通过机器的硬件噪声产生随机数、通过大气噪声产生随机数 Random生成的随机数都是伪随机数!!! 是由可确定的函数(常用线性同余),通过一个种子(常用时钟),产生的伪随机数。这意味着:如果知道了种子,或者已经产生的随机数,都可能获得接下来随机数序列的信息(可预
shuffle_seed: 0 # 数据打散的种子 干嘛用的
https://blog.csdn.net/u010589524/article/details/89371919 TRAIN: # 训练配置batch_size: 32 # 训练的batch sizenum_workers: 4 # 每个trainer(1块GPU上可以视为1个trainer)的进程数量file_list: "./dataset/flowers102/train_list

深度学习如炼丹,你有哪些迷信做法?网友:Random seed=42结果好
来源:机器之心本文约2200字,建议阅读9分钟调参的苦与泪,还有哪些“迷信的做法”? 每个机器学习领域的研究者都会面临调参过程的考验,当往往说来容易做来难。调参的背后往往是通宵达旦的论文研究与 GitHub 查阅,并需要做大量的实验,不仅耗时也耗费大量算力,更深深地伤害了广大工程师的头发。 有人不禁要问:调参是门玄学吗?为什么模型明明调教得很好了,可是效果离我的想象总有些偏差。 近日,re

nump中的为随机数产生器的seed
在python的程序中,发现了如下的伪随机数产生的代码 rng = numpy.random.RandomState(23355)arrayA = rng.uniform(0,1,(2,3)) 该段代码的目的是产生一个2行3列的assarray,其中的每个元素都是[0,1]区间的均匀分布的随机数 这里看以看到,有一个23355这个数字,其实,它是伪随机数产生器的种子,也

深度学习中的随机种子random_seed
解释 由于模型中的参数初始化例如权重参数如下图,就是随机初始化的,为了能够更好的得到论文中提到效果,可以设置随机种子,从而减少算法结果的随机性,使其接近于原始结果。 设置了随机种子,产生的随机数都是相同的。 值得注意的是:“随机种子和神经网络训练没有直接关系,随机种子的作用就是产生权重为初始条件的随机数。神经网络效果的好坏直接取决于学习率和迭代次数”。 pytorch查看和调整种子 学会查

SEED:基于SEED数据集的理解
声明:本文章内容,仅个人理解,如有看法,欢迎评论区讨论或私信。 文章目录 SEED数据集一、官网地址二、SEED详细内容论文1,文章信息:(一)摘要(二)引言(三)贡献(四)相关工作(五)方法(六)实验(七)结果(八)总结 论文2,文章信息:(一)摘要(二)引言(三)贡献(四)相关工作(五)实验设计(六)方法(七)实验结果(八)总结 三、数据集展示1.Preprocessed_EEG2.查
关于R语言中set.seed()
在r中取sample时候,经常会有set.seed(某数),经常看见取值很大,其实这里无论括号里取值是多少,想要上下两次取值一样,都需要在每次取值前输入同样的set.seed(某数),才能保证两次取值相同。 set.seed(1)x<-rnorm(5)set.seed(1)y<-rnorm(5) 这样,x和y的值能保持一致
numpy.random.seed()函数的思考
转自:https://blog.csdn.net/weixin_31270811/article/details/80287015 numpy中有可以用来产生随机数的函数,这里主要就其中的seed()函数进行一些简单的介绍。 贴一个官方的链接:https://docs.scipy.org/doc/numpy/reference/generated/numpy.random.seed.html#
R语言【base】——.Random.seed(),RNGkind(),RNGversion(),set.seed():随机数生成器
Package base version 4.2.0 Description .Random.seed是一个整数向量,包含R中生成随机数的随机数生成器(RNG)状态。它可以保存和恢复,但不应该被用户更改。 RNGkind是一个更友好的接口,用于查询或设置正在使用的RNG类型。 RNGversion在早期的R版本中可以用来设置随机生成器(为了再现性)。 set.seed 是设置随
torch.manual_seed(233333)
torch.manual_seed(233333) 介绍报错信息解决问题总结 介绍 这是在使用GPT-SoVITS时运行缺失pytorch导致报的错 报错信息 Traceback (most recent call last): File “D:\vits\GPT-SoVITS-beta\GPT-SoVITS-beta0217\webui.py”, line 10, in

安装 SEED-XDS560v2 Driver.exe
安装 SEED-XDS560v2 Driver.exe References CCS 5.5.0.00077 安装目录 D:\ti\ccsv5\ SEED-XDS560v2 Driver.exe 安装目录 D:\ti\ccsv5\ccs_base References [1] Yongqiang Cheng, https://yongqiang.blog.csdn
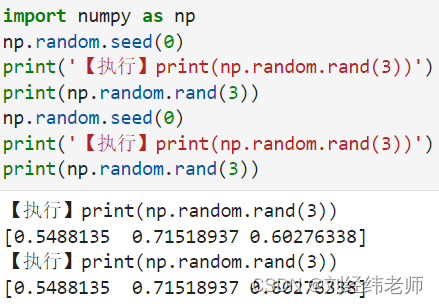
让每次生成的随机数都相同np.random.seed()
【小白从小学Python、C、Java】 【计算机等考+500强证书+考研】 【Python-数据分析】 让每次生成的随机数都相同 np.random.seed() 选择题 关于以下代码输出的结果说法正确的是? import numpy as np np.random.seed(0) print('【执行】print(np.random.rand(3))') print(np.random.ra