本文主要是介绍SEED:基于SEED数据集的理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明:本文章内容,仅个人理解,如有看法,欢迎评论区讨论或私信。
文章目录
- SEED数据集
- 一、官网地址
- 二、SEED详细内容
- 论文1,文章信息:
- (一)摘要
- (二)引言
- (三)贡献
- (四)相关工作
- (五)方法
- (六)实验
- (七)结果
- (八)总结
- 论文2,文章信息:
- (一)摘要
- (二)引言
- (三)贡献
- (四)相关工作
- (五)实验设计
- (六)方法
- (七)实验结果
- (八)总结
- 三、数据集展示
- 1.Preprocessed_EEG
- 2.查看mat文件内容
SEED数据集
一、官网地址
1.SEED数据集
二、SEED详细内容
论文1,文章信息:
Investigating Critical Frequency Bands and Channels for EEG-Based Emotion Recognition with Deep Neural Networks
题目:利用深度神经网络研究基于脑电图的情绪识别的关键频段和信道
作者:Bao-Liang Lu、Wei-Long Zheng
期刊:IEEE Transactions on Autonomous Mental Development
单位:上海交通大学
时间:2015
(一)摘要
研究影响情绪关键频段和信道,选择了4、6、9、12个通道进行实验。
(二)引言
用于EEG信号分析的特征选择方法:主成分分析、Fisher投影;
特征选择方法的缺点:无法保留原始的领域信息(通道和频率带)。
1.情感研究的领域以及实例;
2.情感识别的方法,说明了EEG的优势,难度以及方法;
3.前人基于脑电图的情绪识别的关键频段和通道的研究方法及结果;
4.简要概述了深度架构模型的发展及优势;
5.本文的重点:研究基于脑电图的高效情绪识别的关键频段和关键通道。
(三)贡献
1.考虑到深度神经网络的特征学习和特征选择性,将深度学习方法引入基于多通道脑电数据的情绪识别中。
2.通过分析从经过训练的深度置信网络中学到的权重分布,研究了不同的电极组减少,并定义了最佳电极位置。
3.从脑电数据中提取的微分熵特征具有准确、稳定的情绪识别信息。
(四)相关工作
概述了使用脑电图进行情绪识别的相关研究,以及深度学习方法对生理信号的应用。
(五)方法
1.预处理:
(1)将原始脑电图数据下采样到200HZ采样率;
(2)手动去除被EMG和EOG严重污染的记录;
(3)使用0.3至50HZ的带通滤波器处理EEG数据,消除伪影。
2.特征提取:
(1)提取五个频段的微分熵特征(delta: 1-3 Hz,theta: 4-7 Hz,alpha: 8-13 Hz,beta: 14-30 Hz,gamma: 31-50 Hz);
(2)验证不对称的大脑活动,计算了微分不对称(DASM)、有理不对称(RASM)、DCAU(差分头尾性);
(3)将传统的功率谱密度(PSD)作为基线;应用线性动态系统(LSD)方法进一步过滤掉不相关的成分,并考虑情绪状态的时间动态。
3.使用深度置信网络进行分类:
(1)一种具有深度架构的概率生成模型;
(2)由多个RBM块(下图)(受限玻尔兹曼机)组成;
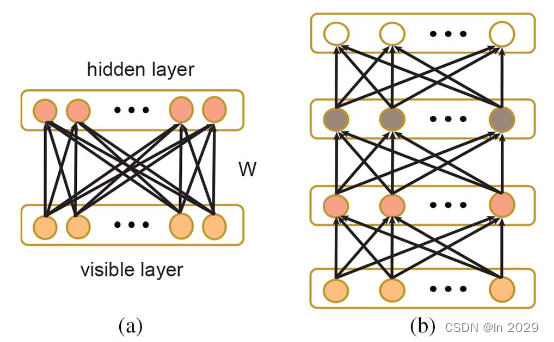
(六)实验
1.刺激:
(1)情感电影;
(2)优点:既包括场景,也包含音频,可以让接触到更真实的场景,并引起强烈的主观和生理变化;
(3)15个电影视频,每个视频4分钟,评估三类情绪(积极、中性、消极),每类情绪对应五个相应的电影片段。
2.受试者:
(1)15名受试者(7男、8女,平均年龄23.27),视力与听力正常,所有人都是右撇子;
(2)使用了森克人格问卷(EPQ)选择受试者,筛选出外向并且情绪稳定的受试者参加情绪实验; 艾森克人格问卷问卷

(3)事先受试者被告知了实验流程,受试者要舒适地坐着,专心观看电影视频,并尽量避免过多的动作(面部表情也尽量静止,防止有肌肉伪迹的干扰)。
3.步骤:
(1)在上午或下午安静的环境中进行实验;
(2)使用了 NuroScan 62通道电极帽按照国际10-20系统以1000Hz的采样率记录脑电图;
(3)眼电图的记录,为了消除伪迹;
(4)每个实验中包含15个session。每个会话的每个视频前面都有5秒提示,后面都有45秒自我评估时间以及15秒休息时间;
(5)自我评估:1)在观看电影片段时实际感受到了什么;2)是否曾看过这部电影;3)是否理解了电影片段。
(七)结果
1.神经模式:
(1)积极情绪:β 和 γ 频段的能量增加;
(2)中性和消极情绪:β 和 γ 频段的能量较低;
(3)中性情绪:更高的α能量;
(4)α波段反映了注意力处理;β波段反映了大脑中的情绪和认知过程;γ段适用于以情绪图像为刺激的情绪分类。
2.分类器训练:
比较了KNN、逻辑回归(LR)、支持向量机(SVM)、深度置信念网络(DBN)。
3.分类性能:
(1)DE特征在γ和β频段优于其他频段;
(2)在非对称特征(DASM、RASM、DCAU),虽然维度少,但是可以达到了相当的精度,这证明了不对称的大脑活动在情绪处理中是有意义的;
(3)DBN模型的精度高、标准差低;
(4)混淆矩阵
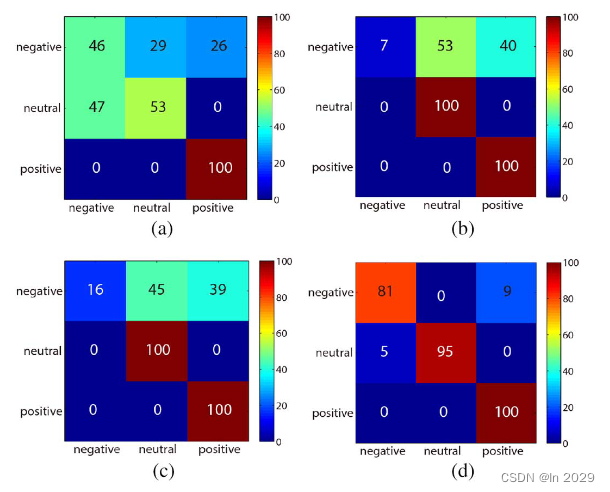
行表示目标分类;列表示分类器输出的预测分类;
从图中可以看出积极情绪容易识别,而消极情绪最难识别,kNN、LR和SVM将负性情绪与中性情绪和积极情绪混为一谈。DBN可以显著提高负面情绪的分类精度。
4.电极数量减少
(1)4、6、12通道的电极位于侧颞区,而9通道添加了3个额叶的电极。
4通道:FT7,FT8,T7,T8;
6通道:FT7,FT8,T7,T8,TP7,TP7;
9通道:FP1,FPZ,FP2,FT7,FT8,T7,T8,TP7,TP8;
12通道:FT7,FT8,T7,T8,C5,C6,TP7,TP8,CP5,CP6,CP7,P7,P8。
(2)用SVM作为分类器,将四组电极组合与完整的62个电极进行比较,因为所选的电极集合被降低到了相对较低的维度作为输入,并且这些关键通道是在训练后由深度神经网络选择的,且SVM没有显式的特征选择属性。
(3)6、9、12通道的配置与SVM实现了比62个通道与SVM更好的性能。
(4)虽然12通道达到了较高的平均准确率,高于SVM的原始62个通道,但不能说明其他50个通道‘无用’。
(八)总结
1.与积极、中性和消极情绪相关的神经特征确实存在,并且他们在不同个体之间存在共性。
2.30次实验,即在两次不同的时间进行实验。
论文2,文章信息:
Identifying Stable Patterns over Time for Emotion Recognition from EEG
题目:从脑电图中识别随时间稳定的情绪模式
作者:Wei-Long Zheng , Student Member, IEEE, Jia-Yi Zhu, and Bao-Liang Lu , Senior Member, IEEE
期刊:IEEE Transactions on Affective Computing
单位:上海交通大学
时间:2019
(一)摘要
研究情绪识别中的脑电图稳定性。
(二)引言
1.情感计算的研究;
2.情感脑机接口的挑战;
3.引出研究同一参与者在不同时间的情绪变化是否稳定;
(三)贡献
1.开发了SEED数据集;
2.在DEAP、SEED数据集上,对不同的特征提取、特征选择、特征平滑和模式分类方法进行了系统比较和定性评估;
3.采用判别式图正则化极限学习(GELM)来识别随时间变化的稳定模式,并通过跨会话(时间)方案评估GELM情绪识别的稳定性;
4.证明了三种情绪(积极、中性和消极)的神经特征确实存在,并且关键频带和脑区域的脑电图模式在会话内和会话间相对稳定。
(四)相关工作
1.概述了用脑机接口对情感识别的研究;
2.提出当前局限:目前没有对随时间稳定的激活模式进行系统评估;
3.提出对不同时间段的特定情绪状态。
(五)实验设计
1.同一参与者进行三次实验,间隔一周或更长时间;
2.刺激:
(1)中国电影片段(20名参与者选定电影片段);
(2)整个实验的时长不应太长,以免使参与者产生视觉疲劳;
(3)电影片段应能够不经解释就能理解;
(4)电影片段引发单一的目标情绪;
(5)每种情绪在一个实验中有五个电影片段,每个电影片段的时长约为4分钟。
3.参与者(参与实验):
15名(7男8女)、年龄:19-28岁(平均23.27岁)、上交本地学生、视力正常或矫正正常、听力正常。
4.在实验开始之前,参与者被告知实验内容,并要求舒适地坐着,专心观看电影片段,尽量不分散注意力,并尽量避免明显的动作。
5.面部视频和脑电数据同时录制:
(1)脑电数据使用NeuroScan以1000Hz的采样率,每个电极的阻抗必须低于5千欧;处理脑电信号:将原始脑电数据采样到200Hz的采样率。使用0.5至70Hz的带通滤波器处理脑电数据,滤除噪声和去除伪迹。并将严重受EMG和EOG污染的记录将从数据集中手动删除。
(2)面部视频是从安装在参与者前方的摄像头录制的。面部视频以AVI格式编码,帧率为30帧每秒,分辨率为160 X 120。
6.每个实验有15个试验,在每个片段之前有15秒的开始提示和每个片段之后10秒的反馈时间。
反馈:参与值被告知要立即在观看每个片段后通过完成问卷,报告他们对每个电影片段的情感反应;
问题:
(1)观看电影片段的实际感受;
(2)观看电影片段的特定时间内,感受如何;
(3)之前是否看过这个电影;
(4)否理解电影片段。
(六)方法
1.特征提取:
功率谱密度(PSD)、差分熵(DE)、差分不对称性(DASM)、有理不对称性(RASM)、不对称性(ASM)和差分头尾性(DCAU)特征;
2.特征平滑:
为了让研究情绪是动态变化的,采用线性动态系统(LDS)方法来平滑特征,过滤与情绪无关的成分。
3.降维:
(1)提取的脑电特征可能与情绪状态不相关,导致分类器性能下降;
(2)优势:可以帮助提高分类器的速度和稳定性;
(3)PCA(主成成分分析):可以降低特征的维度,但不能保留转换后的原始领域信息,如通道和频率等。当维度降低到210时,精度从91.07%下降到88.46%,在维度160时达到局部最大值89.57%。
(4)MRMR(最小冗余最大相关性):
a.使用互信息作为相关性度量,并采用最大相关和最小冗余标准。用于从给定的特征集中选择最具信息量的特征,以提高模型的性能和泛化能力。 既要保证特征之间的相关性尽可能小(最小冗余),又要保证选出的特征与目标变量之间的相关性尽可能大(最大相关性)。
b.20个顶级特征:
α:FT8;β:AF4、F6、F8、FT7、FC5、FC6、FT8、T7和TP7;γ:FP2、AF4、F4、F6、F8、FT7、FC5、FC6、T7和C5
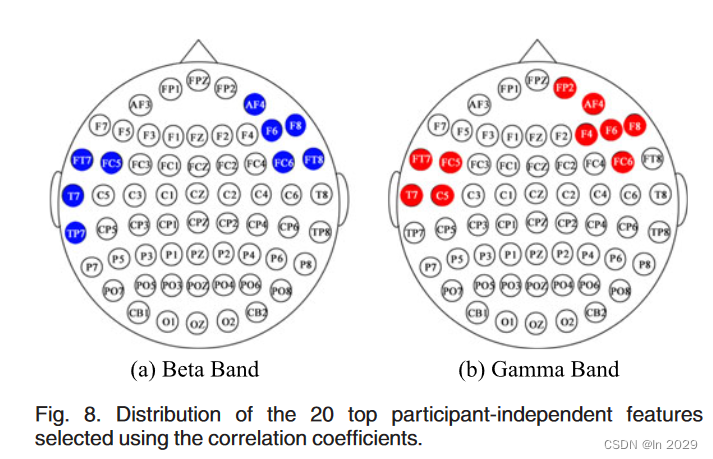
(5)分类:
使用判别图正则化极限学习机(GELM)作为分类器。在GELM中,对输出权重施加的约束,强制使来自同一类别的样本输出相似。
(七)实验结果
1.DEAP数据集
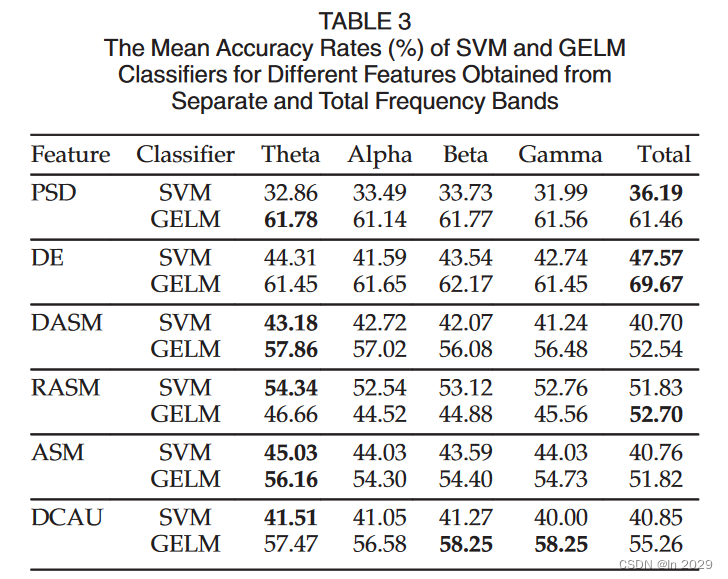
(1)DE(差分熵)特征优于PSD(功率谱密度)特征;
(2)在DEAP数据中,不同频段的分类精度差异并不显著;
(3)GELM的性能优于SVM的性能。
2.SEED数据集
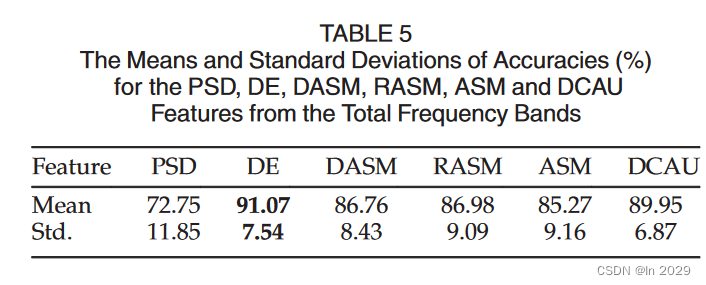
(1)DE特征比传统的PSD特征具有更高的准确率和更低的标准差;
(2)特征平滑算法:LDS(线性动态系统)方法明显优于移动平均方法;
(3)从γ和β频段获得的特征比其他频段的特征表现更好;
(4)从γ和β频段获得的特征比其他频段的特征表现更好;
(5)与积极、中性和消极情绪相关的神经特征确实存在;
(6)跨会话(时间)的稳定脑电图模式在同一参与者的重复脑电图测量中表现出一致性。
(八)总结
1.调查了三种情绪的稳定神经模式。
2.在研究情绪识别任务中,还应该考虑性别、年龄和种族等重要因素。
三、数据集展示

1.Preprocessed_EEG
包含了15名受试者在3个session中的数据,以及label.bat
2.查看mat文件内容
(1)查看受试者mat文件
import scipy.io as siodef read_one_file(path, file_name):# 读取单个.mat文件data = sio.loadmat(path + file_name)
# print(data)print("---------------------")#代表15个电影片段print(data.keys())print("---------------------")#(通道,数据点)print(data['djc_eeg1'].shape)print("---------------------")print(data['djc_eeg1'])read_one_file("D:/graduate/datasets/EEG/SEED/SEED_EEG/Preprocessed_EEG/", "1_20131027.mat")

极)X 一定数量的数据点。
电极:FP1 FPZ FP2 AF3 AF4 F7 F5 F3 F1 FZ F2 F4 F6 F8 FT7 FC5 FC3 FC1 FCZ FC2 FC4 FC6 FT8 T7 C5 C3 C1 CZ C2 C4 C6 T8 TP7 CP5 CP3 CP1 CPZ CP2 CP4 CP6 TP8 P7 P5 P3 P1 PZ P2 P4 P6 P8 PO7 PO5 PO3 POZ PO4 PO6 PO8 CB1 O1 OZ O2 CB2
(2)查看label.mat
import scipy.io as siodef read_one_label(path, file_name):data = sio.loadmat(path + file_name)print("---------------------")print(data.values())print("---------------------")print(data)read_one_label("D:/graduate/datasets/EEG/SEED/SEED_EEG/Preprocessed_EEG/", "label.mat")

可以看到label文件是一个列表,key是’label’,values是标签,对应15个实验的标签,其中-1表示消极,0表示中立,1表示积极。
这篇关于SEED:基于SEED数据集的理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






