本文主要是介绍AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出
在数字化时代,文本到语音(Text-to-Speech, TTS)技术已成为人机交互的关键桥梁,无论是为视障人士提供辅助阅读,还是为智能助手注入声音的灵魂,TTS 技术都扮演着至关重要的角色。从最初的拼接式方法到参数化技术,再到现今的深度学习解决方案,TTS 技术经历了一段长足的进步。这篇文章将带您穿越时间,探究 TTS 技术的演变历程,重点关注如何通过先进的算法和计算模型,实现从一段静态文本到仿若真人般自然流畅语音的转化。我们将深入了解深度学习的革命性影响,如何推动着 TTS 技术向着更高的自然度和理解力迈进,特别是谷歌的 Tacotron 和 DeepMind 的 WaveNet 如何在这个领域设定了新的标准。随着技术的不断成熟,未来的 TTS 系统将更加智能、灵活,并且能够在更广泛的应用场景中提供个性化和情感丰富的语音交互体验。
1.TTS before End-to-end
1.1 Concatenative Approach(拼接式方法)
Concatenative Approach(拼接式方法)是传统的文本到语音(Text-to-Speech,TTS)合成技术之一。这种方法主要特点是 speeches from a large database,即通过拼接已经录制好的语音片段来合成语音。这些语音片段可以是单个的音素(语音的基本单位)、音节、词或者短语等,录制时覆盖了不同的发音、语调和情感。

拼接式方法的优点是合成的语音通常听起来非常自然,因为它们是基于真实的人声录制的。然而,这种方法也有一些局限性和缺点:
- 资源消耗大:因为需要维护一个庞大的语音单元库,这会占用大量的存储空间。
- 灵活性有限:如果遇到数据库中没有包含的新词或特别的发音,系统可能无法合成出自然的语音。
- 制作成本高:语音单元库的制作需要专业的录音设备和环境,以及大量的时间来录制和处理语音,因此制作成本相对较高。
1.2 Parametric Approach(参数化方法)
在文本到语音(Text-to-Speech,TTS)合成中,参数化方法(Parametric Approach)是一种模型合成语音的技术。与拼接式方法(Concatenative Approach)直接使用录制的语音片段不同,参数化方法使用数学模型来模拟人声的特性,并根据这些模型合成语音。以下是参数化 TTS 系统的基本工作流程:
- 文本分析:输入的文本首先经过分析,包括文本规范化、词汇分析和句法分析,然后,文本被转换成音素序列,音素是语音的基本发音单位;
- 语音建模:
- 特征提取:首先,从大量的人类语音记录中提取声学特征,这些特征代表了语音的基本属性,包括基频(音高)、共振峰(代表声带和口腔形状)、音素时长、能量等。
- 声学模型训练:使用提取的特征来训练声学模型,这些模型旨在学习文本特征(如音素、音调标记)和声学特征之间的关系。
- 参数生成:使用声学模型根据音素序列预测声学参数,包括基频(音高)、共振峰(代表声带和口腔形状)、音素时长、能量等;
- 声音合成:将预测的声学参数输入到声码器,声码器根据这些参数生成合成语音的数字信号。
- 语音合成:最终的数字信号被转换为听得见的语音,输出给用户。下图描述了参数化方法 HTS(HMM/DNN-based Speech Synthesis System,HTS 通常指的是 HMM-based Speech Synthesis)的工作流程
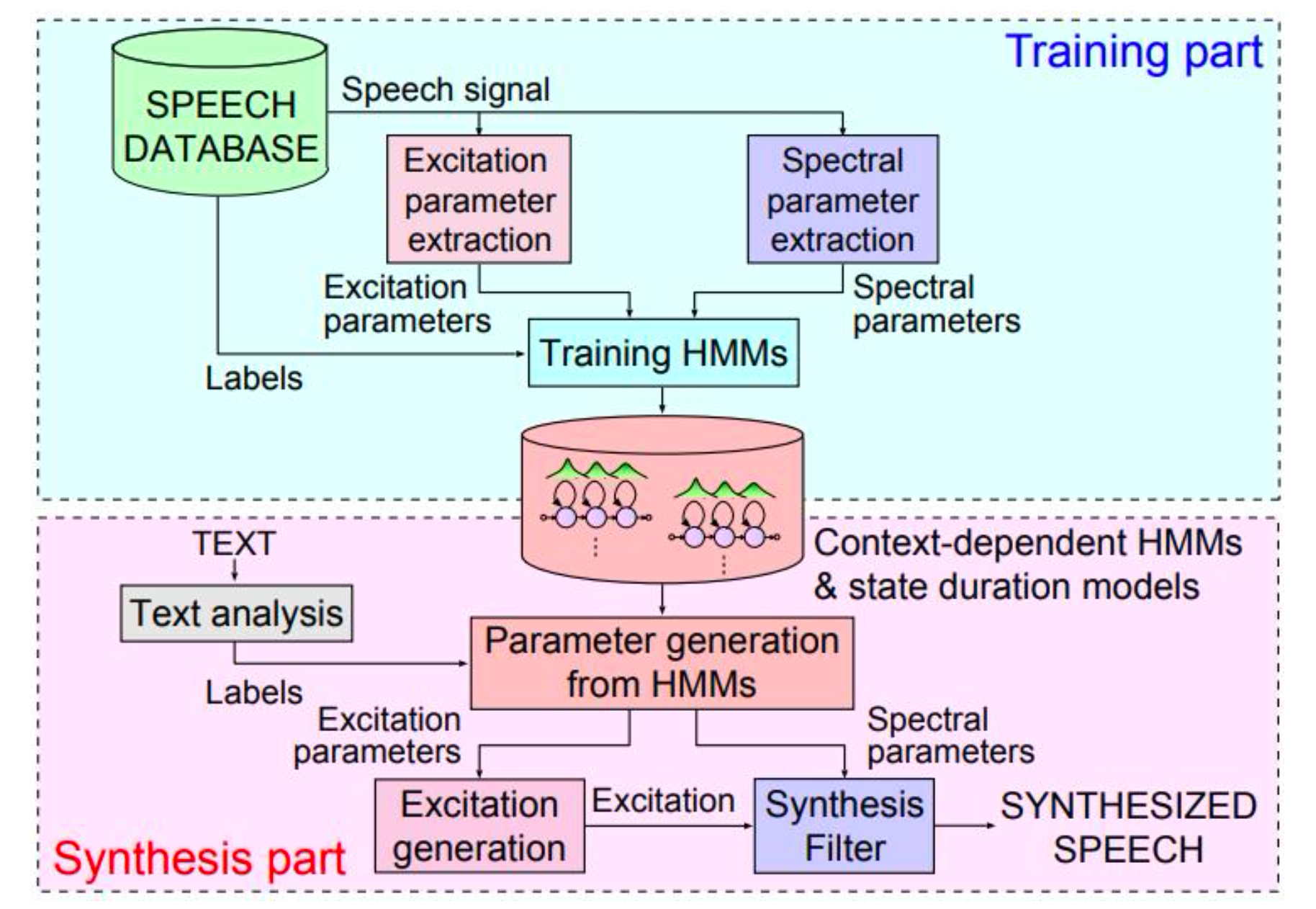
参数化方法的主要优势在于:
- 资源占用小:不需要存储大量的语音录音片段,模型参数通常占用的存储空间相对较小。
- 高度可控制:通过调整模型参数,可以改变合成语音的各种特性,如语调、语速和情感等。
- 灵活性:理论上可以合成任何文本,包括新词和非标准词汇,而不受预录语音片段的限制。
- 声码器依赖:输出的音质很大程度上取决于声码器的性能,一些传统声码器可能造成音质损失。然而,参数化方法也有一些挑战:
- 自然度:传统的参数化 TTS 系统通常比基于拼接的方法或最新的深度学习方法合成的语音听起来更机械和不自然。
- 模型复杂性:构建一个准确模拟人类语音行为的声学模型非常复杂,对于特定的语言和语音特性可能需要大量的调整和优化。
随着技术的发展,深度学习技术已被应用于 TTS 系统,如端到端的神经网络模型 Tacotron 和 WaveNet,它们可以直接从文本生成语音,不再依赖于预先录制的语音片段,解决了拼接式方法的一些局限性。HTS 主要基于传统的统计模型和声学理论,而 Tacotron 则更多地依赖深度学习和大数据。HTS 系统在计算效率和资源需求方面具有优势,但 Tacotron 能够生成更自然的语音输出。随着技术的不断进步,Tacotron 及其变体正在逐渐成为业界新标准,特别是在追求高质量语音合成的场景中。
1.3 Deep Voice
Deep Voice 是由 Baidu Research 开发的一系列文本到语音(TTS)合成系统。Deep Voice 项目标志着基于深度学习的 TTS 技术的重大进步,它旨在通过使用深度神经网络来生成更加自然和高效的语音输出。Deep Voice 的第一个版本,即 Deep Voice 1,于 2017 年发布,它是一个端到端的系统,采用多个深度学习模型来处理不同的 TTS 任务,如文本分析、音素持续时间预测、基频预测和音频合成。与传统的参数化 TTS 系统相比,Deep Voice 1 的一个显著改进是使用深度神经网络生成声码器参数,这提高了合成语音的自然度。随后,Baidu Research 进一步发布了 Deep Voice 2 和 Deep Voice 3(end to end)。每一个新版本都在模型架构、训练速度、语音质量和系统灵活性方面带来了改进。
-
Deep Voice 2 开始引入了多说话人支持,允许模型学习和合成不同说话人的声音。
-
Deep Voice 3 集成了改进的 WaveNet 模型作为其声码器,用以生成最终的语音波形,增强了语音的自然度。

2. Tacotron: End-to-end TTS
2.1 Before Tacotron
在讲解 Tacotron 模型架构之前,先理解一下 RNN 和 Seq2Seq 架构的基本概念,帮助我们更好理解 Tacotron 模型
2.1.1 循环神经网络
RNN 是一种拥有短期记忆力的神经网络,在处理序列数据方面有很好的效果,广泛应用于语音识别、语言翻译、tts 等任务。RNN 的基本工作原理:想象一下你在看电影,当你观看当前的画面时,你的理解不仅仅基于当前的场景,还基于你对电影之前情节的记忆。RNN 正是在这个原理上工作的:每处理一个新的输入(比如一个新的单词或者时间点上的数据),它都会考虑之前处理过的信息, 让神经网络有一个短期的记忆力,那么神经网络就可以像人脑一样去分析识别。
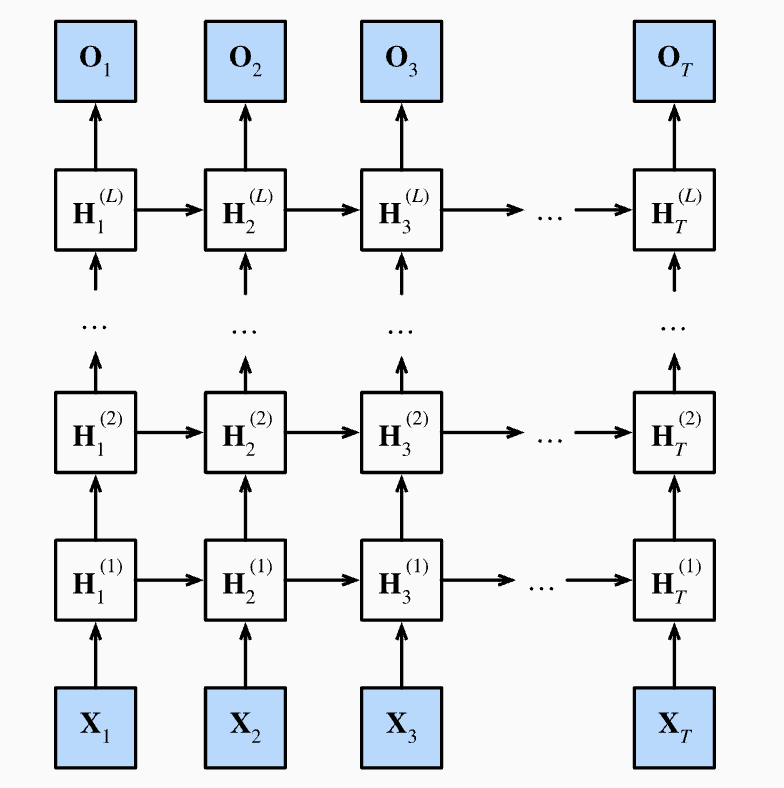
2.1.2 序列到序列架构(seq2seq)
是一种特殊的神经网络设计,用于处理那些输入和输出都是序列形式的问题。这类问题在自然语言处理(NLP)中非常常见,例如机器翻译(将一种语言的句子转换成另一种语言),文本摘要(缩短长文章为摘要),语音识别(将语音转换为文本)等。Seq2seq 架构通常包含两个主要部分:
-
编码器(Encoder): 编码器的任务是读取和理解输入序列。想象一下你正在阅读一句话。当你读到句尾时,你已经理解了整句话的含义。编码器也是如此,它 “读取” 整个输入序列(例如,一句话),然后将理解到的信息压缩成一个固定大小的“上下文向量”(Context Vector),这个向量是编码器对整个输入序列理解的表示。
-
解码器(Decoder): 解码器的任务是使用编码器提供的上下文向量生成输出序列。继续上面的比喻,如果你被要求用另一种语言复述你刚才读到的那句话,你将使用你的理解来表达相同的意思。同样,解码器也会 “翻译” 这个上下文向量,逐步构建输出序列(例如,另一种语言的句子)。
为了在每个步骤中保持信息,编码器和解码器通常使用循环神经网络(RNN)或其改进版本(如 LSTM 或 GRU)。这些网络类型能够处理序列数据并记住之前的信息,这对于序列任务至关重要。
2.1.3 注意力机制(Attention Mechanism)
在早期的 seq2seq 模型中,编码器将整个输入序列压缩成一个单一的上下文向量。然而,这样做会导致一些信息丢失,尤其是在处理长序列时。注意力机制是作为一个解决方案被引入的。它允许解码器在生成输出时 “关注” 输入序列的不同部分。这样,解码器可以更有效地利用输入信息,尤其在模型需要处理较长输入时。想象一下你正在做一个语音识别的任务,你要把一段语音转换成文本。这段语音对应的是一句话:“I am learning about artificial intelligence.”(我正在学习人工智能。)在没有注意力机制的 seq2seq 模型中,情况可能是这样的:
-
编码器一次性听完整句话,并试图记住它,然后生成一个代表整句话内容的固定向量(一长串数字)。
-
解码器根据这个向量,一次性写下整句话的翻译或转录。然而,句子可能很长,编码器很难记住每个细节,而解码器在没有额外信息的情况下翻译或者转录也可能会出错。
如果我们加入了注意力机制,工作方式将发生变化:
- 编码器还是听完整句话,但它会为句子中的每一个单词创建一个向量,这样就形成了一个向量序列,每个向量代表句子中的一个单词。
- 解码器开始工作时,并不是一次性写下整个句子。相反,它会一步步地进行,每写一个单词就停一下。在写下每个单词时,注意力机制会计算编码器生成的每个向量的重要性,并将焦点放在最相关的那些向量上。
比如,在写下 “I”(我)这个词时,注意力可能主要集中在 “I am learning” 这个片段上;而到了 “artificial”(人工)这个词时,注意力会集中在 “about artificial intelligence” 这一部分。通过这种方式,解码器在写下每个单词时都能 “回顾” 语音中最相关的部分,就像是有一个指导者在提示它:“听,现在我们要写下’artificial’,请专注于那段提到’artificial intelligence’的语音片段。” 这使得最终的文本更加准确,减少了错误和遗漏。
2.2 Tacotron 模型(2017)
Tacotron 是由 Google 的研究团队开发的文本到语音(TTS)合成系统。它首先在 2017 年通过一篇名为《Tacotron: Towards End-to-End Speech Synthesis》的论文被公开介绍。它的特点如下:
- 端到端架构:Tacotron 是一个端到端的 TTS 模型,它采用序列到序列(seq2seq)架构,其中包含编码器、注意力机制和解码器组件,直接将输入的字符序列转换为声学特征,由此生成语音波形。
- 注意力机制:Tacotron 使用注意力机制来处理文本和语音之间的时间对齐问题,这个机制可以自动学习文本的哪些部分应该对应语音的哪些部分。
- WaveNet 集成:在 Tacotron 2 中,集成了 WaveNet 声码器,这使得生成的语音在自然度上有了显著提升。
- 自然听感的语音:与传统的参数化或拼接式 TTS 模型相比,Tacotron 能够生成听起来更为自然和连贯的语音。
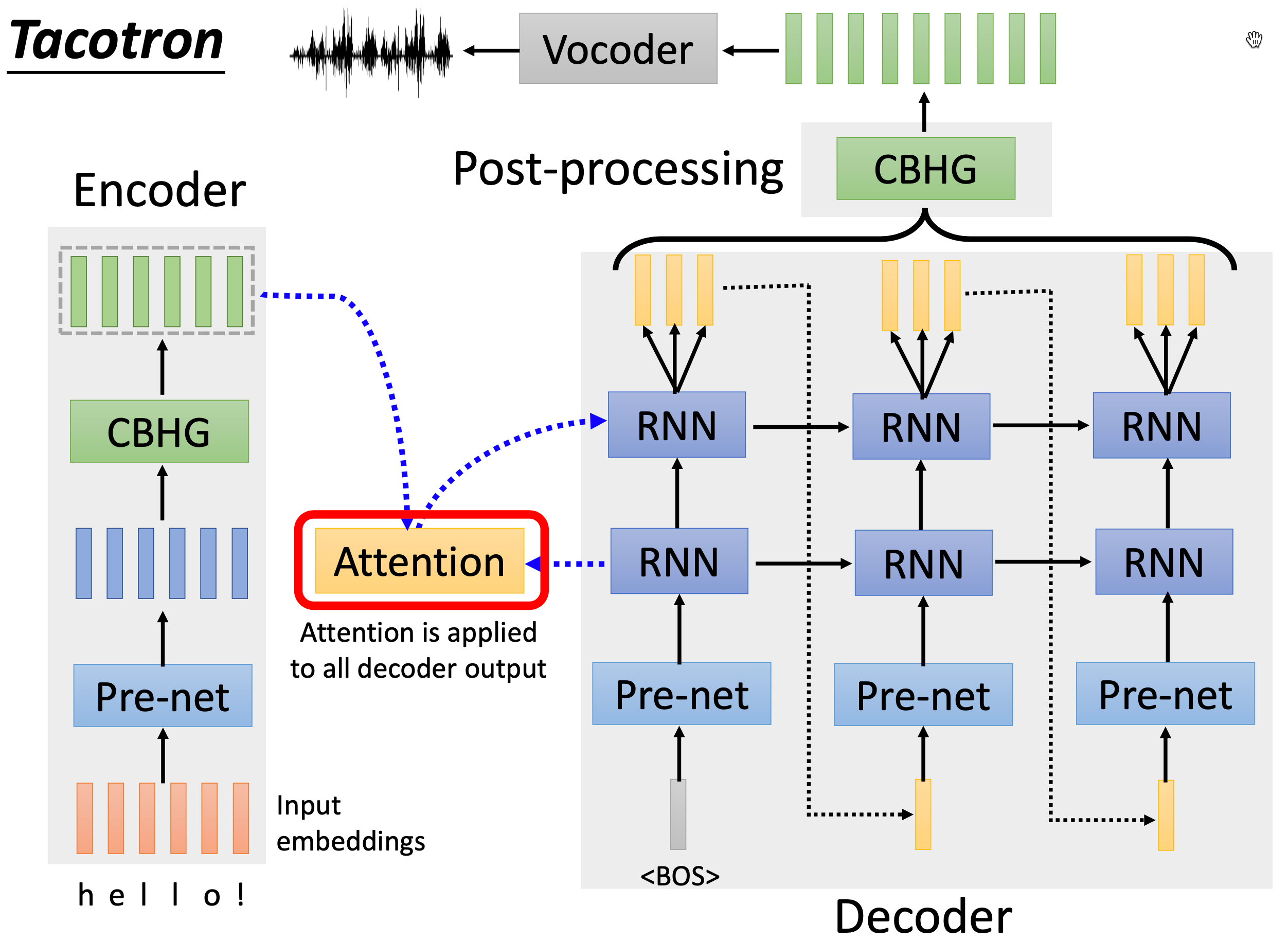
Encoder
Grapheme-to-phoneme 编码器的角色和作用:想象一下你想对电脑说一句话,并希望电脑用语音说出来。你写下了这句话,然后电脑需要理解它并准备发声。Tacotron 系统中的编码器就扮演了这个 “理解” 的角色。编码器的工作是接收你写的文本,并将它转换成电脑能理解的格式。它做了几件事情:
- 解析文本:编码器首先查看你写的每个字母或单词,并将它们转换成数学上的向量。这个过程就像是给每个字母或单词赋予一个特殊的代码,电脑可以通过这些代码来识别和处理它们。
- 考虑顺序:然后编码器会考虑这些字母或单词的顺序。在语言中,顺序很重要,比如,“猫追狗”和 “狗追猫” 意思完全不同。编码器使用一种特殊的模式(通常是循环神经网络,简称 RNN)来保持这个顺序的信息。
- 准备好输出:编码器处理完文本后,会产生一个新的数学向量序列,这个序列包含了整个句子的信息。这些向量包括了关于句子的所有重要信息,比如单词是如何组合在一起的,哪个单词更重要等等。
简而言之,编码器的作用就是把你写的文本转换成电脑可以理解并准备发声的一种数学形式。完成这一步之后,编码器就会把这些信息传递给解码器,解码器随后会用这些信息来实际生成语音。
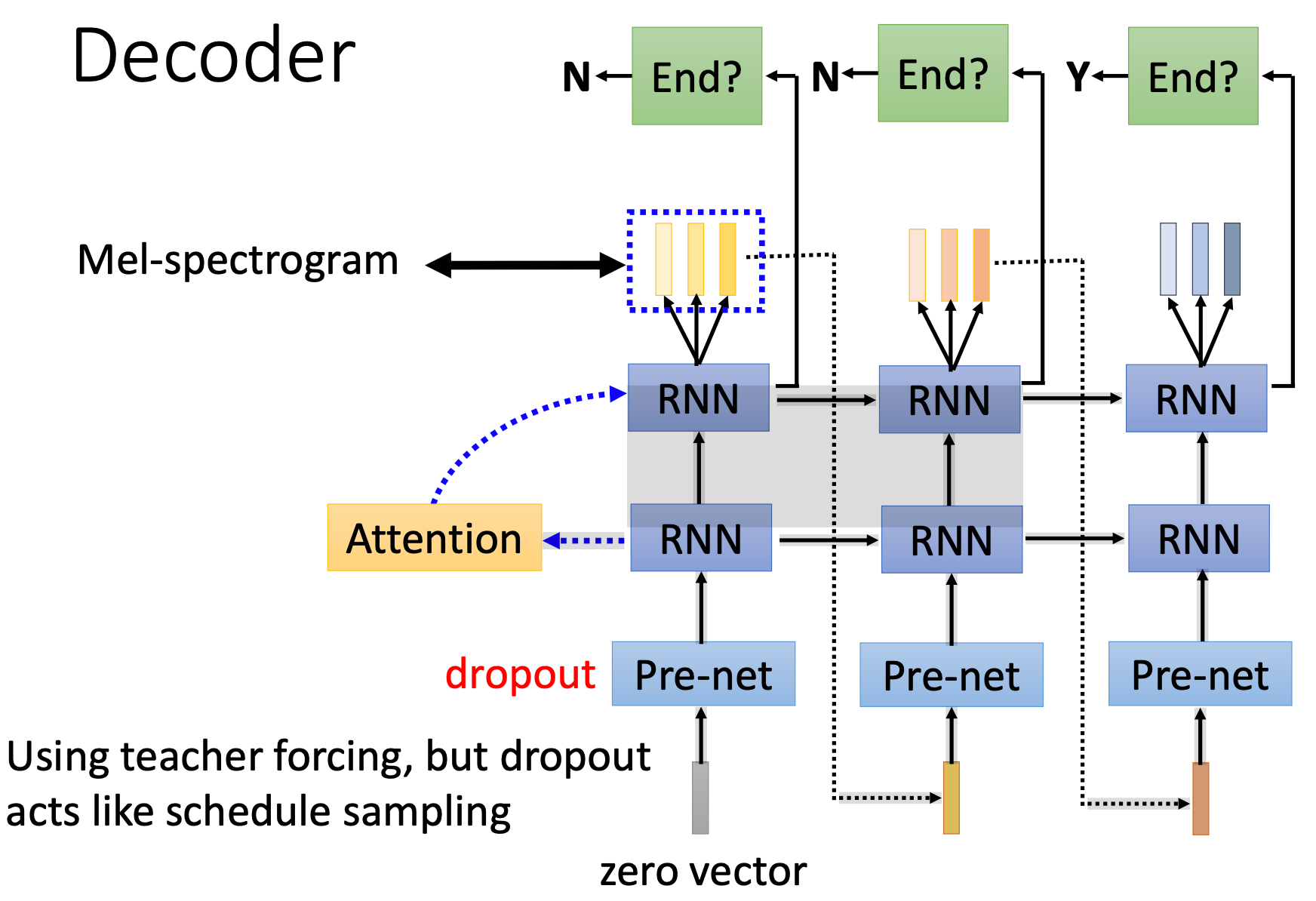
Decoder
想象一下如果你是一个演讲者,你的大脑就像是解码器,你的演讲稿就像是编码器处理过的文本。当你开始演讲时,你会一段一段地讲,每次只关注一小部分内容,并决定应该如何使用你的声音来传达这些内容。这正是 Tacotron 中解码器的作用
- 语音生成:解码器逐步生成语音,每一步产生的可能是一个音节的声音,直到整个句子的语音都生成完成。它像是一个有经验的朗读者,可以根据已经理解的文本内容,决定每一个音节应该是什么声音。
- 时间控制:解码器负责确定每个音节或单词的持续时间,也就是说它控制说话的节奏和速度。它确保语音听起来自然,而不是机械地一个音接一个音。
- 音调和语调:解码器还负责语音的音调,可以让语音听起来更像是在问问题、表示惊讶或是其他情感,而不是单调的声音。
- 工作配合注意力机制:注意力机制非常像是你在读书时用手指指着你正在读的那一行。当你的眼睛移动到下一行时,你的手指也跟着移动,这样你不会丢失位置,也能保持阅读的连贯性,同样地,Tacotron 中的注意力机制保证在产生语音的过程中,模型能够跟踪正在转换成语音的文本的正确位置。
Pre-net
Pre-net 在解码器接收到编码器输出的信息之前对信息做一些预处理。简单来说,pre-net 帮助准备和改进了这些信息,让后面生成语音的过程能够更顺利进行。应用在 pre-net 中的 dropout 是一种用在神经网络训练中的技巧,目的是防止网络对训练数据 “学得太过头了”。这种过度学习叫做 “过拟合”,就像是一个学生只会做课本上的题目,但是一遇到新题就不会做了。Dropout 通过在训练时随机关闭(或 “丢弃”)网络中的一些连接(想象成神经网络中的神经元间的连线),迫使网络不要过分依赖任何一个部分,这样网络就能更好地泛化,也就是对新情况的适应力更强。
Post processing
想象一下你拍了一张照片,想要分享到社交媒体上。你可能直接上传原图,但你也可能会先对照片进行编辑,比如调整亮度、对比度,或者加上滤镜,使得照片看起来更加美观或者有特定的风格,然后再上传。这个编辑照片的过程,就是一种后处理。在 Tacotron 这样的文本到语音(TTS)系统中,后处理模块的作用与此类似。Tacotron 的主要任务是将文本转换为语音,但生成的语音在最初可能还不够完美,可能会有一些机械的感觉,或者声音的质量还不够自然。这时候,后处理模块就发挥了作用,它对初步生成的语音进行额外的处理和改进,来提升最终语音的质量。这些处理可能包括:
-
调整音频特性:比如调整音量、音高,确保语音在整个句子中听起来平衡一致。
-
去除噪音:消除生成过程中可能产生的任何静电噪音或杂音,使得语音更加清晰。
-
加强自然感:通过添加呼吸声、口腔和喉咙的微小动作声音,使得机器生成的声音听起来更像是真人发出的声音。
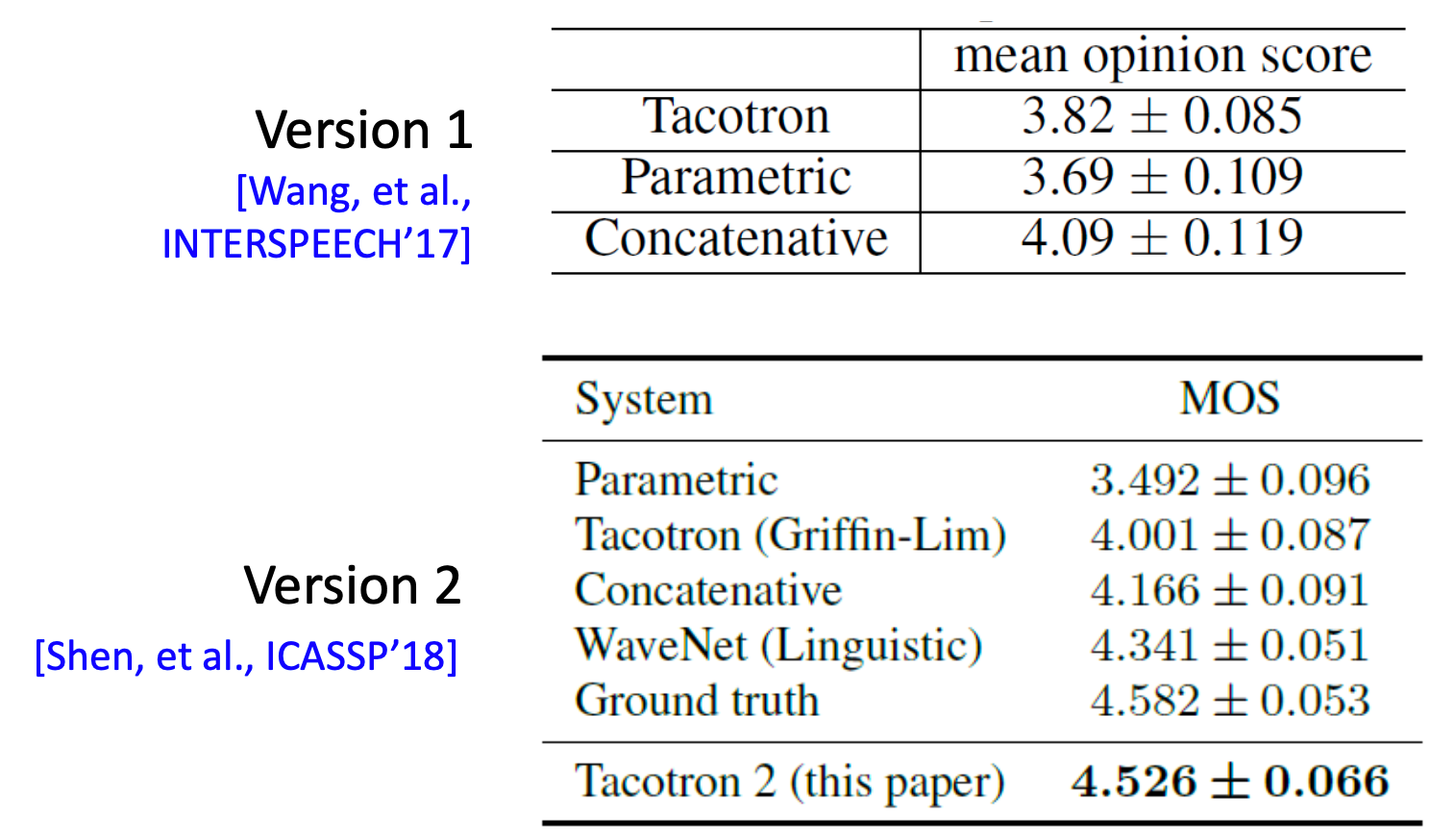
How good is Tacotron

WaveNet(2016)
WaveNet 是一种深度学习模型,并由 DeepMind 于 2016 年开发。WaveNet 的核心是一个深度卷积神经网络,它可以生成连贯且逼真的语音波形。这种技术标志着文本到语音 (TTS) 系统的一个重要进步,因为它产生的语音比以前的技术更加自然。在 Tacotron 2 中,WaveNet 的作用是将 Tacotron 生成的梅尔频谱图(Mel-spectrogram)转换成可以听到的语音波形。在语音合成中,这个步骤被称为声码器(vocoder)操作。声码器的任务是把一种较为抽象的表示(如梅尔频谱图)转换成原始的音频信号。
想象一下,你有一张描绘风景的草图。这张草图虽然描绘了山川、树木和天空,但它没有颜色,也缺乏细节,你只能从轮廓大致识别出各个元素。Tacotron 模型生成的梅尔频谱图,就有点像这张草图——它包含了语音信号的基本结构,但它还不是可以听到的声音。现在,假设你有一位艺术家(WaveNet 声码器),他能够看着这张草图,然后画出一幅生动、充满颜色和细节的画作。艺术家的作品不仅忠实于原始的草图,而且还加入了精细的纹理和色彩,让整个画面栩栩如生。WaveNet 声码器就是这样一个艺术家,它将 Tacotron 生成的梅尔频谱图转换成细腻、连贯的音频波形。在 Tacotron 2 中,这个过程是这样的:
-
Tacotron 部分接收文本输入,并生成对应的梅尔频谱图。这个频谱图大致表示了应该生成的语音的内容和特征,但它还不是最终的音频形式。
-
WaveNet 声码器接管这个过程,它查看梅尔频谱图,然后生成一系列的音频样本(即波形)。WaveNet 通过(自回归模型)自回归的方式,每次生成一个样本,并使用之前生成的样本来帮助预测下一个样本。
-
通过这种方式,WaveNet 逐步构建起完整的音频信号,这些信号在人耳听起来就像是连续自然的语音。
WaveNet 的引入大大提高了 Tacotron2 生成语音的自然度和质量。它能够捕捉人类语音中的细微差别,并准确地生成各种语音波动和声调变化。这就是为什么它被用作 Tacotron2 中的声码器的原因。
这篇关于AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





