tacotron专题

AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出
AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出 在数字化时代,文本到语音(Text-to-Speech, TTS)技术已成为人机交互的关键桥梁,无论是为视障人士提供辅助阅读,还是为智能助手注入声音的灵魂,TTS 技术都扮演着至关重要的角色。从最初的拼接式方法到参数化技术,再到现今的深度学习解决方案,TTS 技术经历了一段长足的进步。这篇文章将带您穿越时

2024-05-15 问AI: 介绍一下 , Tacotron系列
文心一言 Tacotron系列是由谷歌开发的,主要用于文本到语音(TTS)转换的模型。该系列模型基于端到端的序列到序列(Seq2Seq)架构,能够直接从文本中生成听起来自然的语音。 Tacotron模型是首个端到端的TTS深度神经网络模型,它采用了一种基于注意力的Seq2Seq结构。该模型包括编码器(encoder)、基于注意力的解码器(decoder)和后处理网络。编码器用于理解输入的文本数
如何有效使用Tacotron系列语音合成模型
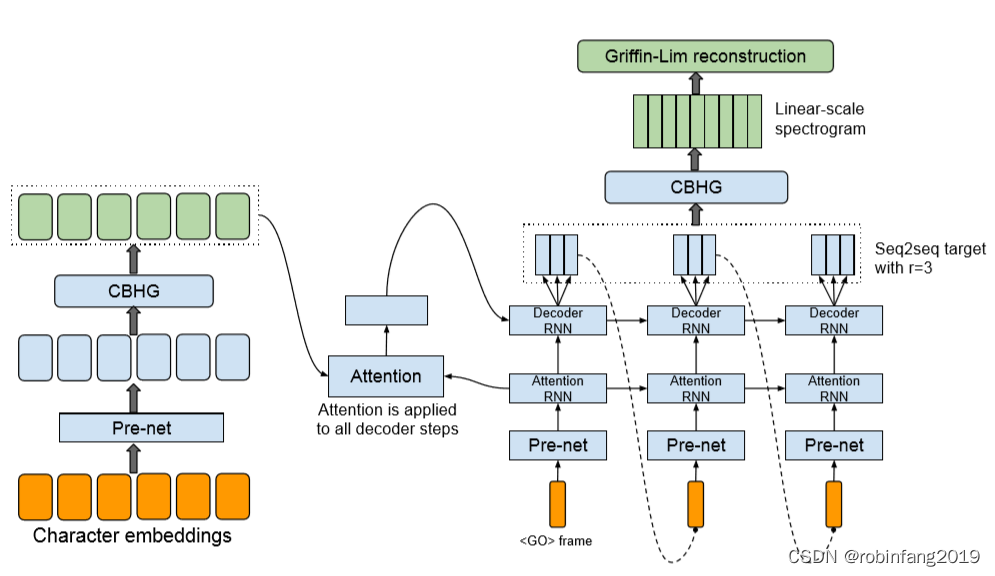
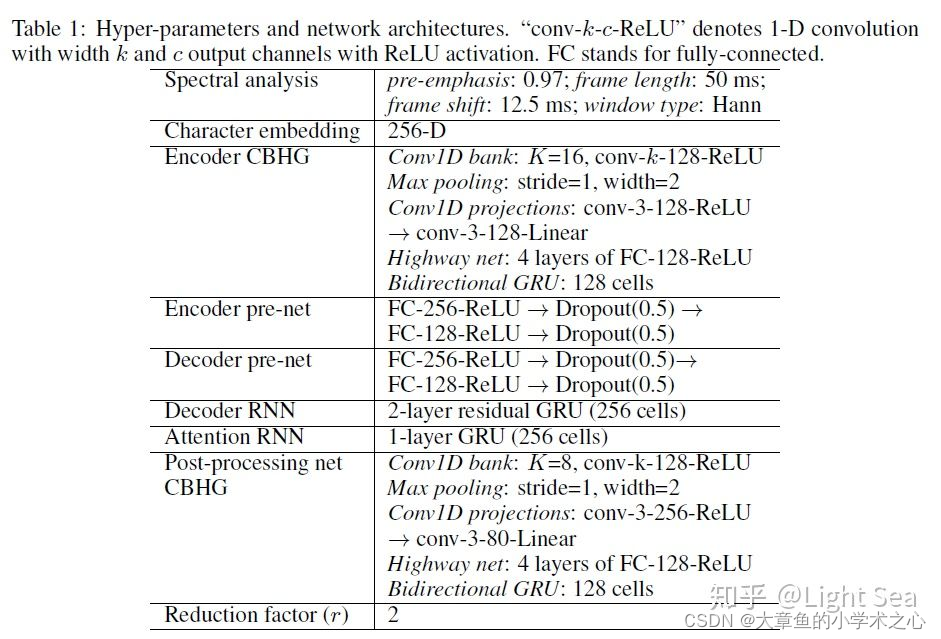
谷歌开发的Tacotron系列,主要用于文本到语音(TTS)的转换。模型基于端到端的序列到序列(Seq2Seq)架构,能够直接从文本中生成自然听起来的语音。Tacotron系列是基于神经网络的自回归语音合成模型,通过编码器-解码器结构,将文本转化为语音波形。Tacotron2引入了WaveNet作为解码器,提高了语音的自然度和质量。 1、技术原理及架构图 Tacotron
解决Tacotron中的“ValueError: operands could not be broadcast together with shapes (1,1025) (0,)”
解决Tacotron中的“ValueError: operands could not be broadcast together with shapes (1,1025) (0,)” 今天在Tacotron数据预处理中,无脑使用python preprocess.py,结果报错如下: ValueError: operands could not be broadcast together w
tacotron之二——具体函数分析
看到了很多不友好的函数,这些函数可能,而且极大可能在转换tflite时出现问题。 甚至有的函数还是用的很旧的函数:我的版本tf1.14.0 from tensorflow.contrib.rnn import OutputProjectionWrapperfrom tensorflow.contrib.seq2seq import BasicDecoder, BahdanauAttentio
tacotron论文解读
tacotron论文解读 参考链接 https://zhuanlan.zhihu.com/p/101064153 tacotron是第一个端到端TTS模型 输入:raw text 输出:mel-spectrogram图(梅尔频谱图) 利用Grilffin-Lim声码器将mel-spectrogram转为wav 名词解释 1. mel-spectrogram 梅尔倒谱图 在音频、

Parallel Tacotron 12
单位:google作者:Isaac Elias时间:2020 & 2021 interspeech 文章目录 1. Parallel Tacotron总结abstractintroductionmethodInput EncoderVariationalResidualEncoderGlobal VAE per SpeakerPhoneme-Level Fine-Grained VAE D

Fantasy Mix-Lingual Tacotron Version 4: Google-ZYX-Phoneme-HCSI-DBMIX 调整LID
0. 说明 VAE + LID效果目前是最好的, 将LID调整下, 不在decoder拼接LID, 在encoder_output处拼接 1. 枚举方案 有以下方案 speaker emb和residual仍然在decoder拼接, 只LID在前面speaker emb和residual放在前面与否, 仅仅是被query的内容不同; 而根据query为声学特征, memory为文本特征,