本文主要是介绍如何有效使用Tacotron系列语音合成模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
谷歌开发的Tacotron系列,主要用于文本到语音(TTS)的转换。模型基于端到端的序列到序列(Seq2Seq)架构,能够直接从文本中生成自然听起来的语音。Tacotron系列是基于神经网络的自回归语音合成模型,通过编码器-解码器结构,将文本转化为语音波形。Tacotron2引入了WaveNet作为解码器,提高了语音的自然度和质量。
1、技术原理及架构图
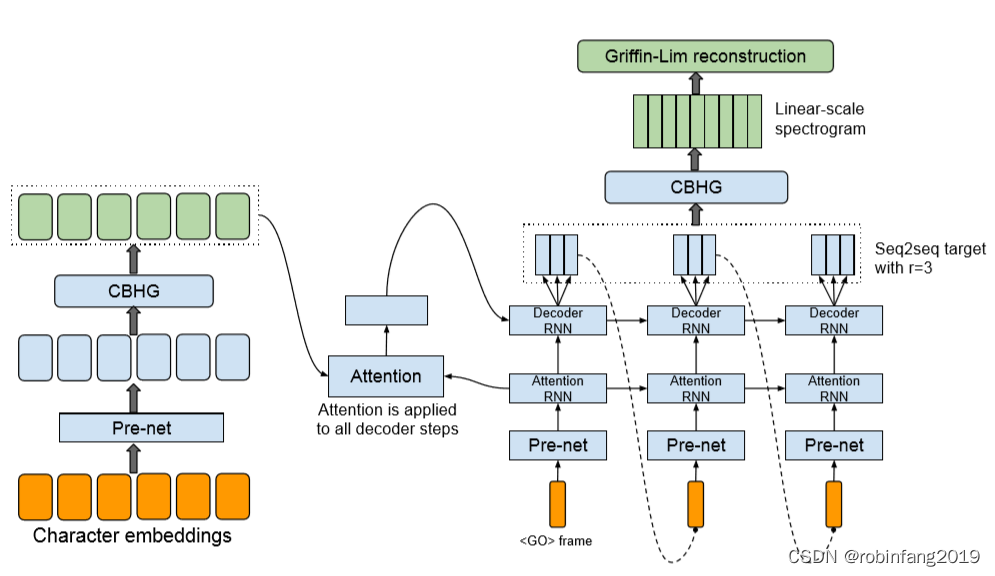
- Tacotron模型的核心是一个带有注意力机制的seq2seq模型。这意味着它可以处理输入的文本序列,并生成对应的语音特征,如声谱图。
- 在Tacotron模型中,首先使用一个编码器(encoder)来理解输入的文本数据,然后通过一个基于注意力的解码器(decoder)来预测或生成语音的声谱图。最后,通过后处理网络(post-processing network)进一步优化生成的声谱图,以便更好地反映实际的语音特征。
- Tacotron2引入了改进的WaveNet作为声码器,用于从预测的声谱图中生成时域波形样本,这使得模型在语音质量上有所提升。
2、在中文语音合成中的应用效果
Tacotron系列模型在中文语音合成中的应用效果表现出色,尤其是在处理方言和非标准发音方面。根据最新的研究成果,Tacotron2已经被成功应用于中国方言的语音合成中,尽管面临着中文表意文字与拉丁文表音文字的差异,以及缺乏针对特定方言的发音字典等挑战。
WFSC-Tacotron2和CSPCoding-Tacotron2两个模型,这些模型能够在小样本及缺乏发音字典的条件下合成高质量包括粤语、湖南话和合肥话在内的多种方言。此外,这些模型的MOS评分超过3.5分,显示出较高的语音质量。
2.1 WFSC-Tacotron2
WFSC-Tacotron2(Waveform-Spectrogram Correspondence Tacotron 2)是一种改进的Tacotron2模型,它旨在增强原始Tacotron2模型生成的语音波形与频谱图之间的对应关系。
- Word Frame Speech Similarity Coding:WFSC-Tacotron2通过引入字框语音相似性编码技术,增强了模型对中文方言中特有的音韵和声调特征的捕捉能力。
- 中文方言的适应性:WFSC-Tacotron2特别针对中文方言进行优化,使其能够更好地处理方言中的音调变化和发音特点,这对于中文方言的语音合成尤为重要。
- 数据准备和处理:在实现WFSC-Tacotron2时,需要收集和准备充足的中文语音数据和相应的文本信息,这可能包括对方言语音的特别标注和处理。
- 模型训练和优化:WFSC-Tacotron2的训练可能涉及到使用特定的方言数据集,以及可能的迁移学习技术,以便模型更好地学习和模拟目标方言的语音特征。
- 注意力机制的优化:WFSC-Tacotron2会对注意力机制进行优化,以更好地处理方言中的韵律和强度变化,从而提高合成语音的自然度和表现力。
2.2 CSPCoding-Tacotron2
CSPCoding-Tacotron2结合了循环谱峰编码(Cyclic Spectrum Peak Coding)技术的Tacotron2模型,基于Tacotron2进行中文语音合成的开源项目,用于改进中文语音合成。
3、优化模型适应实时输入的文本并生成高质量的语音输出
优化Tacotron模型适应实时输入的文本并生成高质量的语音输出,可以采取以下几种策略:
- 采用非自回归架构:非自回归架构可以在不需要外部对齐器的情况下,通过稳定的端到端训练程序优化所有参数,从而快速高效地合成高质量的语音。这表明,将Tacotron模型转换为非自回归架构可能是一个有效的优化方向。
- 引入显式持续时间预测器:Non-Attentive Tacotron通过替换原有的注意力机制为一个显式的持续时间预测器,显著提高了系统的鲁棒性。这种方法不仅提高了自然度,还允许在推理时对整个话语和每个音素的持续时间进行控制。此外,如果训练数据中缺乏准确的目标持续时间,可以使用细粒度变分自编码器在半监督或无监督方式下训练持续时间预测器,以达到与有监督训练几乎相同的效果。
- 多任务学习以模拟韵律短语:通过将Tacotron扩展到明确模拟韵律短语断裂的框架,并提出一种多任务学习方案来同时预测Mel谱和短语断裂,可以显著改善合成语音中的韵律表达。这种方法特别适用于长句子,其中韵律短语错误可能频繁发生。
- 改进注意力机制:针对Tacotron 2中存在的问题,如注意力模型学习慢、合成语音不够鲁棒以及合成语音速度较慢等问题,可以采取以下措施:使用音素嵌入作为输入以减少错误发音问题;引入一种注意力损失来指导注意力模型的学习,以实现其快速、准确的学习能力;采用WaveGlow模型作为声码器,以加快语音生成的速度。这些改进措施已在实验中显示出提高注意力学习的速度和精度,降低合成语音的错误率,并显著提升合成语音的速度和质量。
4、使用注意力机制来提高模型对文本中重要信息的捕捉能力
- 增强注意力机制的解释性和可视化:根据AtMan方法,可以通过修改Transformer的注意力机制来生成输入与输出预测相关性的图。这种方法不依赖于反向传播,而是使用基于余弦相似度的嵌入空间搜索,这有助于在大型模型部署中节省内存资源。
- 利用强化学习优化注意力机制:AttExplainer提出了一种基于强化学习的框架,用于解释Transformer模型中的注意力矩阵。通过观察注意力矩阵的变化,RL代理学习逐步掩蔽操作,以此来揭示哪些部分对模型的决策影响最大。
- 结合认知增强学习:参考CRL-CBAM方法,可以在Tacotron模型中加入注意力模块,如卷积块注意力模块,以增强模型对重要特征的关注并抑制不必要的特征。这可以通过在两个主要维度(通道和空间轴)上强调有意义的特征来有效地帮助信息流动。
- 改进注意力权重的保真度和合理性:根据最新研究,通过在神经网络训练过程中引入词级目标,可以提高注意力权重的保真度和解释的合理性。这有助于更准确地理解模型如何处理输入数据中的关键信息。
- 多注意力机制的结合使用:根据证据表明,在联想学习中,两个注意力机制的结合效果显著。Tacotron模型可以考虑引入类似的双重注意力机制,以便在不同的学习阶段或任务中分别关注不同类型的信息,从而提高整体的预测性能和信息处理效率
5、相关资源
- NVIDIA/tacotron2: GitHub仓库提供了Tacotron 2的PyTorch实现,支持比实时更快的推理速度。它使用LJSpeech数据集,并依赖于NVIDIA的Apex和AMP。您可以从GitHub克隆这个仓库,并按照提供的步骤进行设置和训练,下载链接:GitHub - NVIDIA/tacotron2: Tacotron 2 - PyTorch implementation with faster-than-realtime inference
- Tacotron-2-Chinese: 这个GitHub仓库提供了Tacotron 2的中文语音合成版本。它使用标贝数据集进行训练,并且支持Tensorflow 1.10。您可以从GitHub克隆这个仓库,并按照提供的步骤进行数据预处理、模型训练和语音合成。下载链接:https://github.com/GoodPaas/Tacotron-2-Chinese
这篇关于如何有效使用Tacotron系列语音合成模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




