语音专题

使用Python实现文本转语音(TTS)并播放音频
《使用Python实现文本转语音(TTS)并播放音频》在开发涉及语音交互或需要语音提示的应用时,文本转语音(TTS)技术是一个非常实用的工具,下面我们来看看如何使用gTTS和playsound库将文本... 目录什么是 gTTS 和 playsound安装依赖库实现步骤 1. 导入库2. 定义文本和语言 3

讯飞webapi语音识别接口调用示例代码(python)
《讯飞webapi语音识别接口调用示例代码(python)》:本文主要介绍如何使用Python3调用讯飞WebAPI语音识别接口,重点解决了在处理语音识别结果时判断是否为最后一帧的问题,通过运行代... 目录前言一、环境二、引入库三、代码实例四、运行结果五、总结前言基于python3 讯飞webAPI语音

阿里开源语音识别SenseVoiceWindows环境部署
SenseVoice介绍 SenseVoice 专注于高精度多语言语音识别、情感辨识和音频事件检测多语言识别: 采用超过 40 万小时数据训练,支持超过 50 种语言,识别效果上优于 Whisper 模型。富文本识别:具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。高效推

让树莓派智能语音助手实现定时提醒功能
最初的时候是想直接在rasa 的chatbot上实现,因为rasa本身是带有remindschedule模块的。不过经过一番折腾后,忽然发现,chatbot上实现的定时,语音助手不一定会有响应。因为,我目前语音助手的代码设置了长时间无应答会结束对话,这样一来,chatbot定时提醒的触发就不会被语音助手获悉。那怎么让语音助手也具有定时提醒功能呢? 我最后选择的方法是用threading.Time

AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出
AI(文生语音)-TTS 技术线路探索学习:从拼接式参数化方法到Tacotron端到端输出 在数字化时代,文本到语音(Text-to-Speech, TTS)技术已成为人机交互的关键桥梁,无论是为视障人士提供辅助阅读,还是为智能助手注入声音的灵魂,TTS 技术都扮演着至关重要的角色。从最初的拼接式方法到参数化技术,再到现今的深度学习解决方案,TTS 技术经历了一段长足的进步。这篇文章将带您穿越时

基于人工智能的智能家居语音控制系统
目录 引言项目背景环境准备 硬件要求软件安装与配置系统设计 系统架构关键技术代码示例 数据预处理模型训练模型预测应用场景结论 1. 引言 随着物联网(IoT)和人工智能技术的发展,智能家居语音控制系统已经成为现代家庭的一部分。通过语音控制设备,用户可以轻松实现对灯光、空调、门锁等家电的控制,提升生活的便捷性和舒适性。本文将介绍如何构建一个基于人工智能的智能家居语音控制系统,包括环境准备

LLM系列 | 38:解读阿里开源语音多模态模型Qwen2-Audio
引言 模型概述 模型架构 训练方法 性能评估 实战演示 总结 引言 金山挂月窥禅径,沙鸟听经恋法门。 小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖铁观音的小男孩,今天这篇小作文主要是介绍阿里巴巴的语音多模态大模型Qwen2-Audio。近日,阿里巴巴Qwen团队发布了最新的大规模音频-语言模型Qwen2-Audio及其技术报告。该模型在音频理解和多模态交互
【阅读文献】一个使用大语言模型的端到端语音概要
摘要 ssum框架(Speech Summarization)为了 从说话人的语音提出对应的文本二题出。 ssum面临的挑战: 控制长语音的输入捕捉 the intricate cross-mdoel mapping 在长语音输入和短文本之间。 ssum端到端模型框架 使用 Q-Former 作为 语音和文本的中介连接 ,并且使用LLMs去从语音特征正确地产生文本。 采取 multi-st

【语音告警】博灵智能语音报警灯JavaScript循环播报场景实例-语音报警灯|声光报警器|网络信号灯
功能说明 本文将以JavaScript代码为实例,讲解如何通过JavaScript代码调用博灵语音通知终端 A4实现声光语音告警。主要博灵语音通知终端如何实现无线循环播报或者周期播报的功能。 本代码实现HTTP接口的声光语音播报,并指定循环次数、播报内容。由于通知终端采用TTS语音合成技术,所以本次案例中无需预先录制音频。 代码实战 为了通过JavaScript调用博灵语音通知终端,实现HT

讯飞XFS5152 语音模块在RK3288 上的应用
公司产品使用XFS5152语音模块作为语音提示应用在RK3288 平台上,这里记录一下驱动调试过程。 XFS5152 支持 UART、I2C 、SPI 三种通讯方式,将收到的中文、英文文本进行语音合成。 产品中RK3288 使用I2C连接该模块,但存在一个问题该模块只支持低速率的I2C,速度最大只能到15KHz, 但RK3288 支持的标准I2C速率为100KHz,实际测试发现虽然可以设置到
java把文字转MP3语音案例
一 工具下载: https://download.csdn.net/download/jinhuding/89723540 二代码 <dependency><groupId>com.hynnet</groupId><artifactId>jacob</artifactId><version>1.18</version></dependency> import com.jacob.acti

Windows 一键定时自动化任务神器 zTasker,支持语音报时+多项定时计划执行
简介 zTasker(详情请戳 官网)是一款完全免费支持定时、热键或条件触发的方式执行多种自动化任务的小工具,支持win7-11。其支持超过100种任务类型,50+种定时/条件执行方法,而且任务列表可以随意编辑、排列、移动、更改类型,支持任务执行日志,可覆盖win自带的热键,同时支持任务列表等数据的备份及自动更新等。 简言之,比微软系统自带的任务计划要强好几倍,至少灵活性高多了,能大幅提高电脑使

三文带你轻松上手鸿蒙的AI语音03-文本合成声音
三文带你轻松上手鸿蒙的AI语音03-文本合成声音 前言 接上文 三文带你轻松上手鸿蒙的AI语音02-声音文件转文本 HarmonyOS NEXT 提供的AI 文本合并语音功能,可以将一段不超过10000字符的文本合成为语音并进行播报。 场景举例 手机在无网状态下,系统应用无障碍(屏幕朗读)接入文本转语音能力,为视障人士提供播报能力。类似微信读书,可以实现将文章内容通过语音朗读,可以
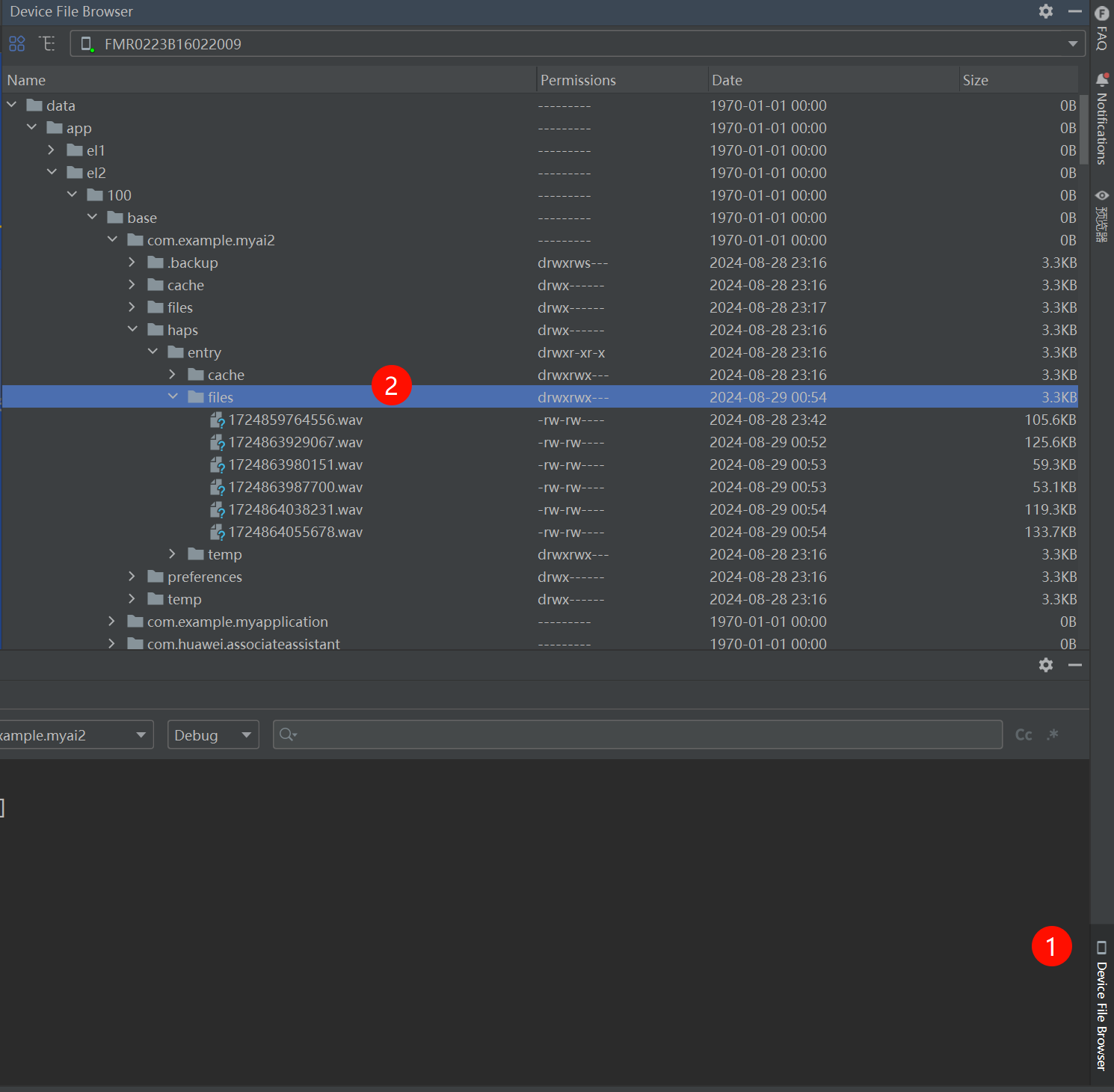
三文带你轻松上手鸿蒙的AI语音02-声音文件转文本
三文带你轻松上手鸿蒙的AI语音02-声音文件转文本 接上一文 前言 本文主要实现 使用鸿蒙的AI语音功能将声音文件识别并转换成文本 实现流程 利用AudioCapturer 录制声音,生成录音文件利用AI语音功能,实现识别 两个录音库介绍 在HarmonyOS NEXT 应用开中,实现录音的两个核心库分别为 AudioCapturerAVRecorder AVRecorder
人工智能,语音识别,机器视觉等相关网址
###Tensorflow https://tensorflow.google.cn/ ###SoundPi http://www.soundpi.org/

三文带你轻松上手鸿蒙的AI语音01-实时语音识别
三文带你轻松上手鸿蒙的AI语音01-实时语音识别 前言 HarmonyOSNext中集成了强大的AI功能。Core Speech Kit(基础语音服务)是它提供的众多AI功能中的一种。 Core Speech Kit(基础语音服务)集成了语音类基础AI能力,包括文本转语音(TextToSpeech)及语音识别(SpeechRecognizer)能 力,便于用户与设备进行互动,实现将实时输入
WhatsApp的AI语音模式:你需要了解的一切
WhatsApp的发展历程成功转换了用户需求,并通过创新和更快的技术改善了用户体验。其新发布的功能集——AI语音模式——可能成为与应用交互的转折点。本文重点介绍WhatsApp的AI语音模式,分析其工作原理及优缺点,并展望其未来发展。 鉴于人工智能日益普及,这一新的功能增加了免提通信,为人们生活带来了便利,同时结合了技术的使用。 AI语音模式解析 移动消息平台WhatsApp目前正在测试一个
解密FSMN-Monophone VAD模型:语音活动检测的未来
在现代语音处理领域,语音活动检测(Voice Activity Detection, VAD)是一个关键技术,广泛应用于语音识别、语音编码和语音增强等任务。随着深度学习的快速发展,传统的VAD方法逐渐被更为先进的模型所取代。本文将深入探讨FSMN-Monophone VAD模型的原理、优势及其实际应用案例,帮助读者更好地理解这一前沿技术。 一、什么是FSMN-Monophone VAD? FS

AI工具-基于funasr打造离线语音转写工具
【说在前面】 该用例基于魔塔社区中发布的预训练模型和funasr构建。仅支持单声道、16KHz、16位采样wav语音文件的离线转写。过程中没有用到onnx模型不支持多线程的并发,但是可以基于多进程实现并发asr工具构建过程中一定要加载vad,否则推理过程中内存会被撑爆 【预训练模型】 所有预训练模型均可在魔塔社区下载 asr:iic/speech_paraformer-large_a

语音特征提取方法 (二)MFCC
下面总结的是第四个知识点:MFCC。因为花的时间不多,所以可能会有不少说的不妥的地方,还望大家指正。谢谢。 在任意一个Automatic speech recognition 系统中,第一步就是提取特征。换句话说,我们需要把音频信号中具有辨识性的成分提取出来,然后把其他的乱七八糟的信息扔掉,例如背景噪声啊,情绪啊等等。 搞清语音是怎么产生的对于我们理解语音有很大
本地搭建 Whisper 语音识别模型
Whisper 是由 OpenAI 开发的一款强大的语音识别模型,具有出色的多语言处理能力。搭建和使用 Whisper 模型可以帮助您将音频内容转换为文本,这在语音转写、语音助手、字幕生成等应用中都具有广泛的用途。本指南将对如何在本地环境中搭建 Whisper 语音识别模型进行详细的说明,并通过实例演示使您更容易理解和应用。 2. 准备工作 2.1 硬件要求 处理器:最低双核 CPU,推荐四

附送试听地址!OpenAI ChatGPT被曝将新增8种语音!英特尔酷睿Ultra 200V正式发布|AI日报
文章推荐 如人类交流一样丝滑!讯飞星火版「Her」正式上线!成立仅16月的无问芯穹完成近5亿元A轮融资|AI日报 8款国内外免费AI生成视频工具对比实测!我们真的可以做到“一人搞定一部影视作品“吗? 今日热点 Sam Altman等OpenAI高管与投资者会面,以推进在美国建设人工智能基础设施 OpenAI Sam Altman今年早些时候一直在寻求美国政府对该项目的支持,该项目旨在组建

使用Cloudflare构建RAG应用;端到端语音开源大模型;AI幻灯片生成器,等六个开源项目
✨ 1: Cloudflare RAG 如何使用Cloudflare构建一个完整的RAG应用,结合多种搜索技术和AI服务。 Cloudflare RAG(Retrieval Augmented Generation)是一个全栈示例,展示如何使用 Cloudflare 构建 RAG 应用程序。该项目结合了 Cloudflare Workers、Pages、D1、KV、R2、AI Gate
调用火山云的语音生成TTS和语音识别STT
首先需要去火山云的控制台开通TTS和STT服务语音技术 (volcengine.com) 火山这里都提供了免费的额度可以使用 我这里是使用了java来调用API 目前我还了解到阿里的开源项目SenseVoice(STT)和CosyVoice(TTS)非常的不错,但是都是使用Python开发的。可以做到说话情绪的识别,感兴趣可以去github上了解一下。 TTS(首先需要导入它给的类) p

Easy Voice Toolkit - 简易语音工具箱,一款强大的语音识别、转录、转换工具 本地一键整合包下载
Easy Voice Toolkit 是一个基于开源语音项目实现的简易语音工具箱,提供了包括语音模型训练在内的多种自动化音频工具,集成了GUI,无需配置,解压即用。 工具箱包括 audio-slicer、VoiceprintRecognition、whisper、SRT - to - CSV - and - audio - split、vits 和 GPT - SoVITS 等。这些优秀