本文主要是介绍tacotron论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
tacotron论文解读
参考链接
https://zhuanlan.zhihu.com/p/101064153
tacotron是第一个端到端TTS模型
输入:raw text
输出:mel-spectrogram图(梅尔频谱图)
利用Grilffin-Lim声码器将mel-spectrogram转为wav
名词解释
1. mel-spectrogram 梅尔倒谱图
在音频、语音信号处理领域们需要将信号转换成对应的语谱图(spectrogram),将语谱图上的数据作为信号的特征。语谱图的横轴x为时间,纵轴y为频率,(x,y)对应的数值代表在时间x时频率y的幅值。
通常的语谱图其频率是线性分布的,但是人耳对频率的感受是对数的(logarithmic),即对低频段的变化敏感,对高频段的变化迟钝,所以线性分布的语谱图显然在特征提取上会出现“特征不够有用的情况”,因此梅尔语谱图应运而生。
梅尔语谱图的纵轴频率和原频率经过如下公式转换,其中f代表原本的频率,m代表转换后的梅尔频率,显然,当f很大时,m的变化趋于平缓。梅尔倒频系数(MFCCs)是在得到梅尔语谱图之后进行余弦变换(DCT,一种类似于傅里叶变换的线性变换),然后取其中一部分系数即可。
m = 2595 ∗ l o g 10 ( 1 + f 700 ) m = 2595 * log_{10} (1+\frac{f}{700}) m=2595∗log10(1+700f)
引用:https://blog.csdn.net/weixin_50547200/article/details/117294164
2. Grilffin-Lim声码器
算法思想
griffin-lim重建语音信号需要使用到幅度谱和相位谱。而MEL谱图当中是不含相位信息的,因此griffin-lim在重建语音博形的时候只有MEL谱可以利用,但是通过一些运算,我们可以利用帧与帧之间的关系估计出相位信息,从而重建语音波形。
这里的MEL谱可以看做是实部,而相位信息可以看做是虚部,通过对实部和虚部的运算,得到最终的结果。
算法步骤
- 随机初始化一个相位谱
- 用这个相位谱与已知的幅度谱(来自MEL谱)经过ISTFT(逆傅里叶变换)合成新的语音波形
- 用合成语音做STFT, 得到新的幅度谱和新的相位谱
- 丢弃新的幅度谱,用已知幅度谱与新的相位谱合成新的语音
- 重复2,3,4多次,直至合成的语音达到满意的效果或者迭代次数达到设定的上限
引用 https://blog.csdn.net/CSDN_71560364126/article/details/103968034
tacotron模型
1. 整体框架
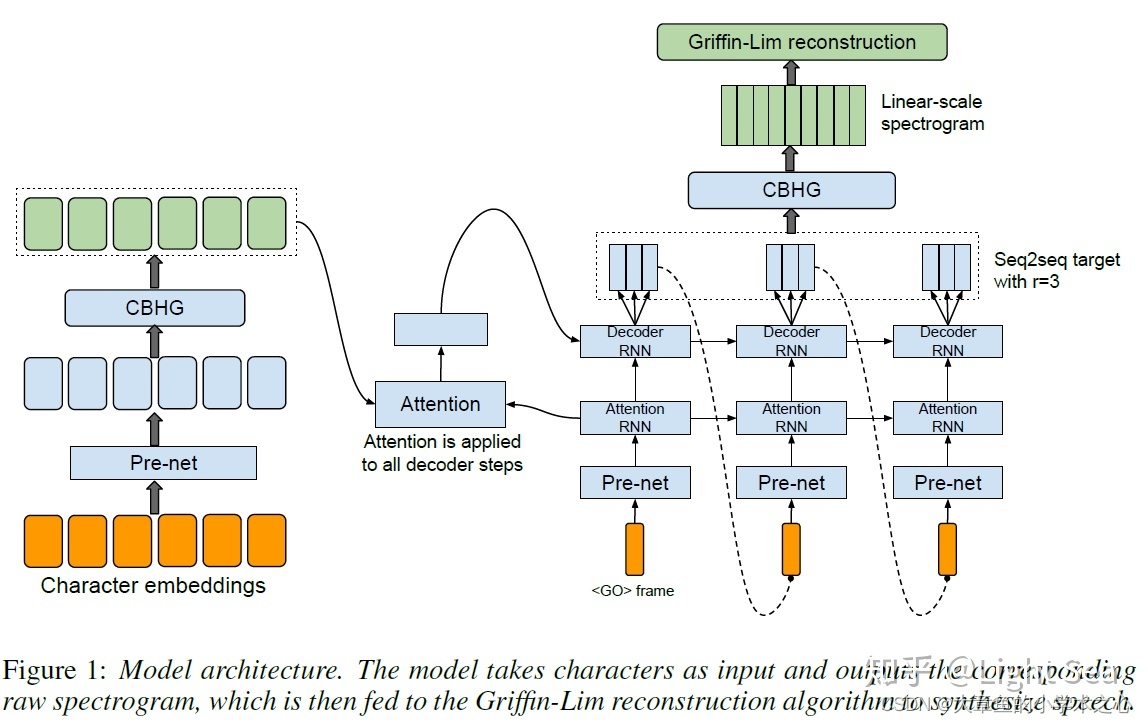
总体来说,模型和sequence-to-sequence模型非常相似,大体上由encoder和decoder组成,raw text经过pre-net, CBHG两个模块映射为hidden representation,之后decoder会生成mel-spectrogram frame。再由声码器处理成最后的波形(wav)。
2. 关键模块
2.1 CBHG
CBHG就是作者使用的一种用来从序列中提取高层次特征的模块,如下图所示:
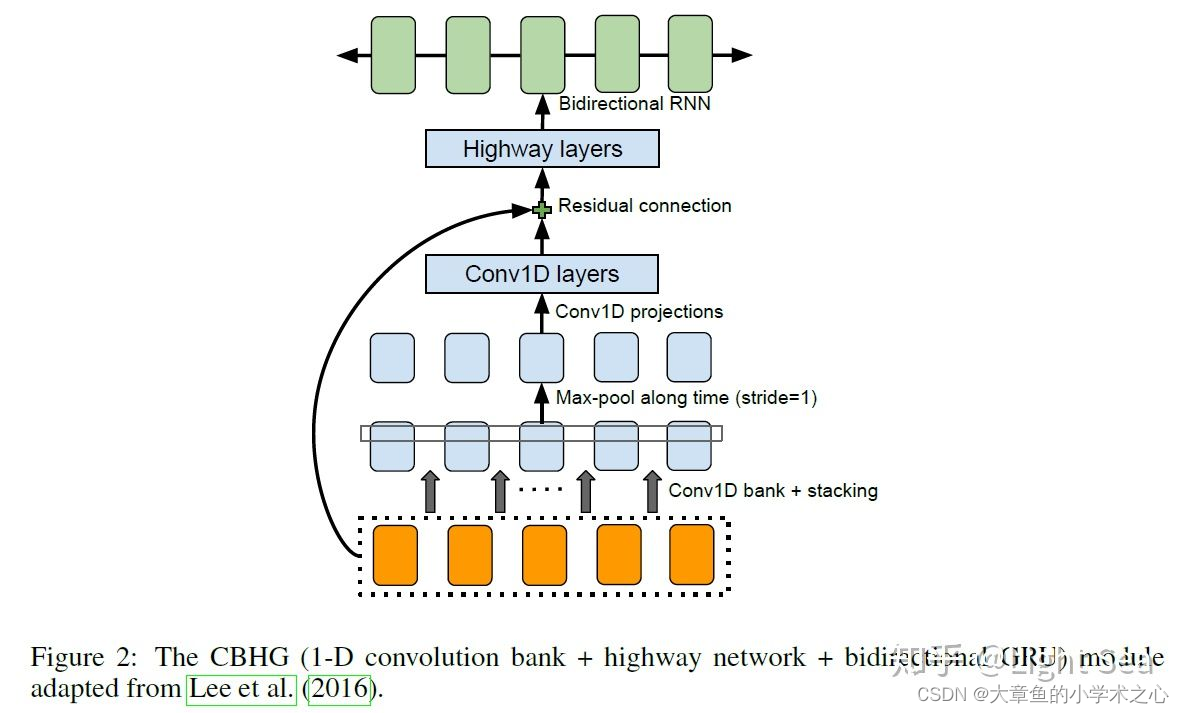
其中使用了卷积+highway+残差链接+双向GRU的组合,输入序列,输出同样也是序列.
highway layers
与LSTM GRU中的门控思想类似,引入Gate机制来解决深度神经网络中的梯度消失和梯度爆炸问题
https://zhuanlan.zhihu.com/p/38130339
2.2 encoder
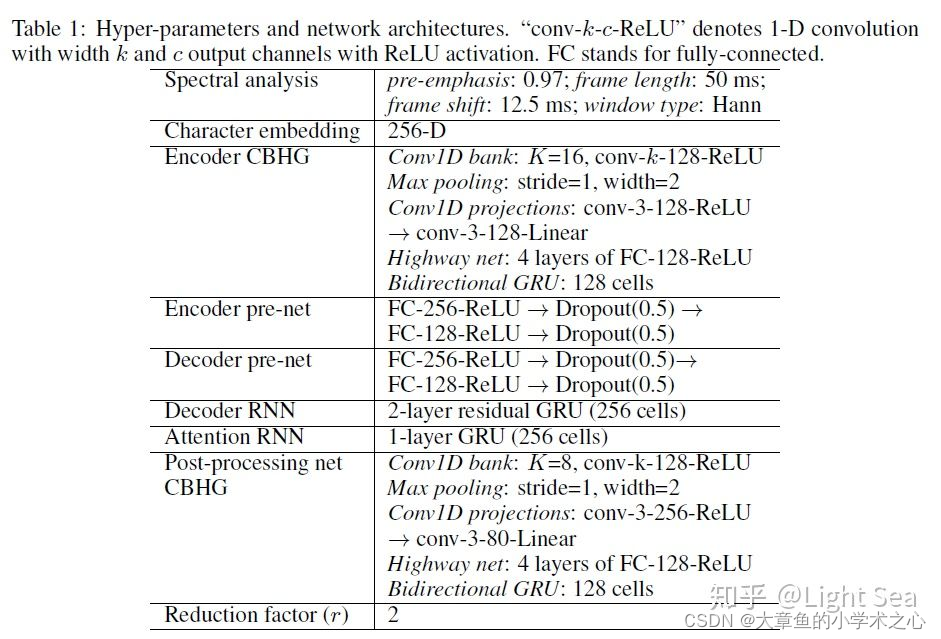
输入被CBHG处理之前还需要经过pre-net进行预处理,作者设计pre-net的意图是让它成为一个bottleneck layer来提升模型的泛化能力,以及加快收敛速度。下图展示了模型整体架构的文字表示,我们可以看到pre-net是由全连接层+dropout组成的模块:
2.3 decoder
作者使用两个decoder: attention decoder和output decoder,attention decoder用来生成query vector作为attention的输入,注意力模块生成context vector,最后output decoder则将query vector和context vector组合在一起作为输入。
这里作者并没有选择直接用output decoder来生成spectrogram,而是生成了80-band mel-scale spectrogram,也就是我们之前提到的mel-spectrogram,熟悉信号处理的同学应该知道,spectrogram的size通常是很大的,因此直接生成会非常耗时,而mel-spectrogram虽然损失了信息,但是相比spectrogram就小了很多,且由于它是针对人耳来设计的,因此对最终生成的波形的质量不会有很多影响。
另外一个用来缩减计算量的做法是每个decoder step预测多个(r个)frame,且作者发现这样做还可以加速模型的收敛。
2.4 post-processing net and waveform synthesis
作者使用比较简单的Griffin-Lim 算法来生成最终的波形,由于decoder生成的是mel-spectrogram,因此需要转换成linear-scale spectrogram才能使用Griffin-Lim算法,这里作者同样使用CBHG来完成这个任务。实际上这里post-processing net中的CBHG是可以被替换成其它模块用来生成其它东西的,比如直接生成waveform,在Tacotron2中,CBHG就被替换为Wavenet来直接生成波形。
2.5 实验
略逊于waveNet
2.6 数据集
这篇关于tacotron论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




