本文主要是介绍Parallel Tacotron 12,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 单位:google
- 作者:Isaac Elias
- 时间:2020 & 2021 interspeech
文章目录
- 1. Parallel Tacotron
- 总结
- abstract
- introduction
- method
- Input Encoder
- VariationalResidualEncoder
- Global VAE per Speaker
- Phoneme-Level Fine-Grained VAE
- Duration Decoder
- 2.4. Upsampling and Positional Embeddings
- 2.5 Spectrogram Decoder with Iterative Loss
- Loss
- 2. parallel tacotron2
- abstract
- introduction
- related work
- model arch
- soft-DTW
1. Parallel Tacotron
总结
- global VAE提取speaker embedding, CVAE提取层级phn prosody embedding;LConv block建模phn encoding;
- 预训练的模型提取duration info,duration predictor预测两个信息(1)是否有phn dur,0/1;(2)phn dur;
- decoder使用iter loss,多级逼近mel spec,loss求和;
abstract
- 非自回归框架
- contribution:
- 基于VAE的residual encoder:可以缓解TTS上one-to-many的问题,并且改善自然度;
- lightweight convolutions:有效的建模local context;
- iterative spectrogram loss:受启发于 iterative refinement。
introduction
- Tacotron以及其他的自回归框架,基于previous mel+text生成当前mel,从而解决TTS上one-to-many的问题;
- FastSpeech:FastSpeech1是基于知识蒸馏,FastSpeech2是添加额外的pitch & energy信息。
- 其他的方法:使用latent embedding表示韵律信息,比如style tokens或者使用VAE捕捉prosody representation来表示。
method
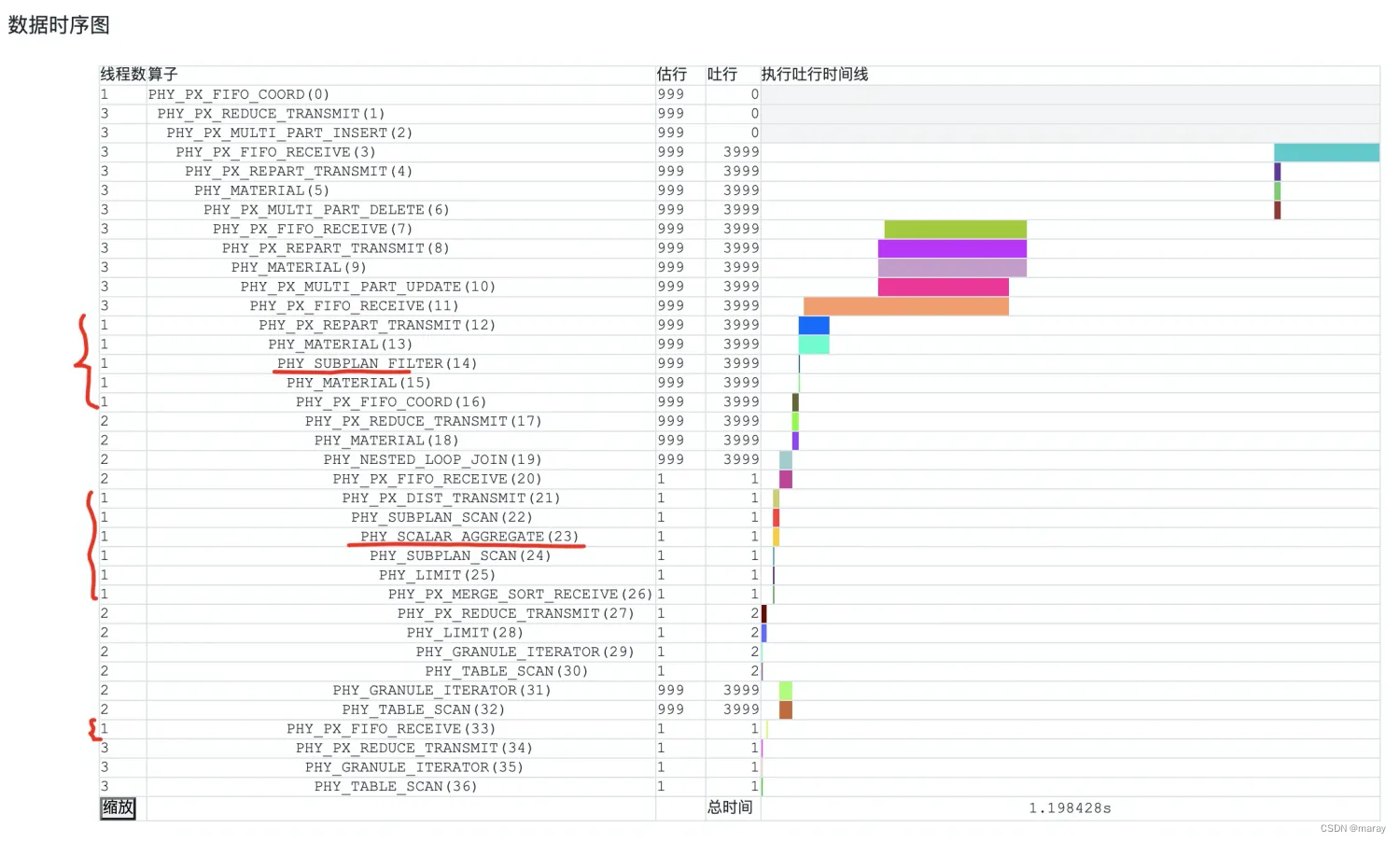
- lightweight convolutions (LConv)——depth-wise convolution,在TTS任务上相对于Transformer的self-attention会更关注局部特征。
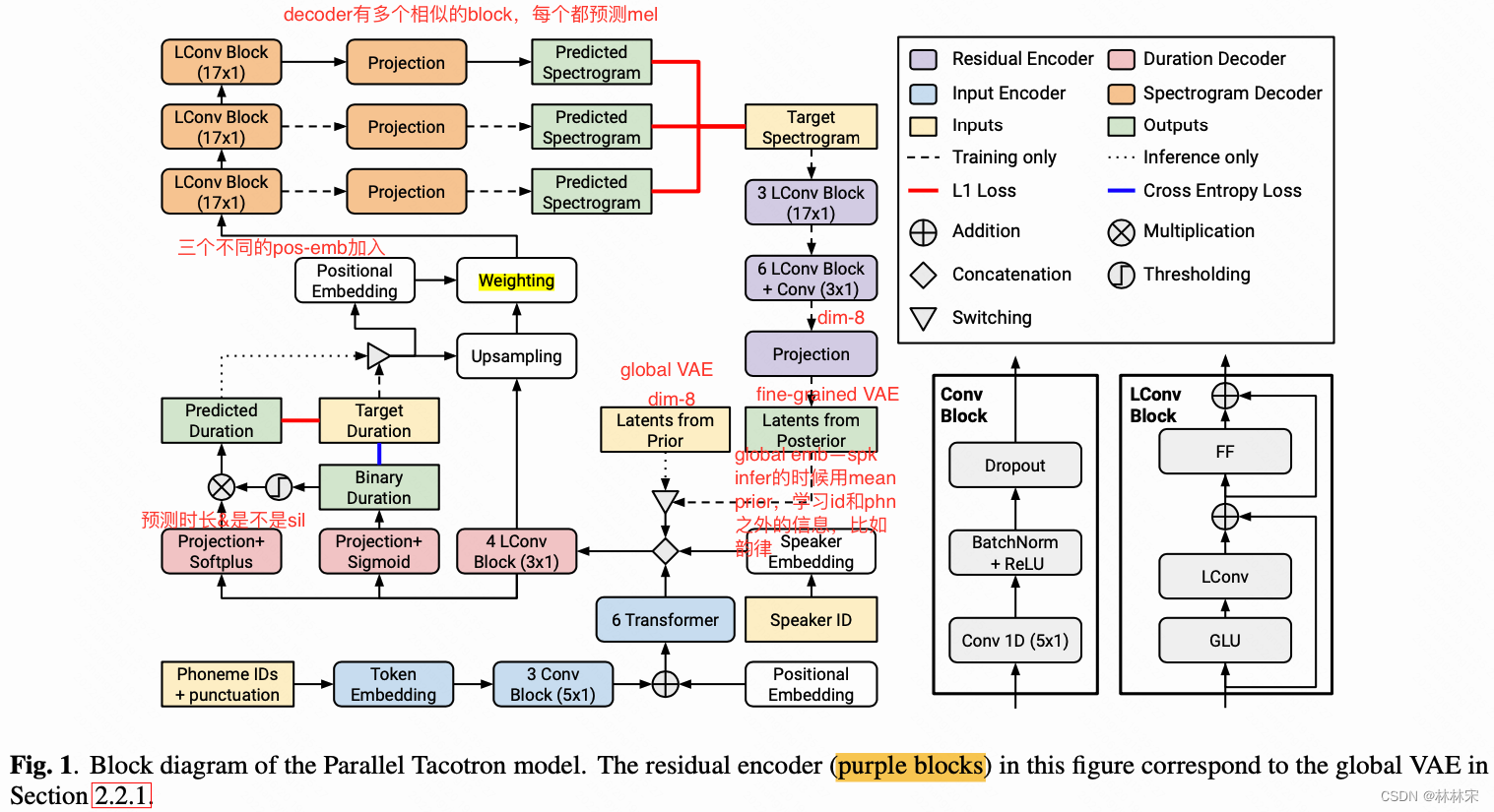
- global VAE和fine-grained VAE都有两个形式:posterior VAE和prior VAE。以speaker Global VAE为例,
Input Encoder
phn—encoder embedding。
VariationalResidualEncoder
Global VAE per Speaker
- traing stage :输入mel-spec,通过多个LConv block降采样,生成定长的global latent representation,表征说话人相关的信息。降维到8,然后后层使用的时候再升维度到 dim32。
- infer stage:使用预设的speaker prior mean;
- residual encoder:建模文本以外的说话人信息(包含说话人相关的韵律特征)
Phoneme-Level Fine-Grained VAE
此部分参考层级建模:Fully-hierarchical fine-grained prosody modeling for interpretable speech synthesis
- 输入position-emb + spk-emb + gt-mel
- 预测:mel-spec和encoder outputs的对齐
训练一个AR-LSTM,使用teacher forcing和L2 loss预测posterior mean
Duration Decoder
预训练的对齐器拿到phn duration信息
- 输入:encoder outputs + latent representation + speaker embeddings
- 预测两个类型的输出:(1) 二进制的0/1 ,判断phn是否有对应的时长——phn一般都有时长,预测1,silence & 标点符号可能是没有时长,预测0;(2)phn-duration,以秒计数;
2.4. Upsampling and Positional Embeddings
- 输入:duration decoder outputs,使用phn duration上采样到frame level;
- 然后➕三种位置向量,使得spec decoder知道the frame positions within phonemes :
- transformer sin_pos表明a frame position within a phoneme
- transformer sin_pos表明phoneme duration信息;
- Fractional progression of a frame in a phoneme(1D CoordConv)
2.5 Spectrogram Decoder with Iterative Loss
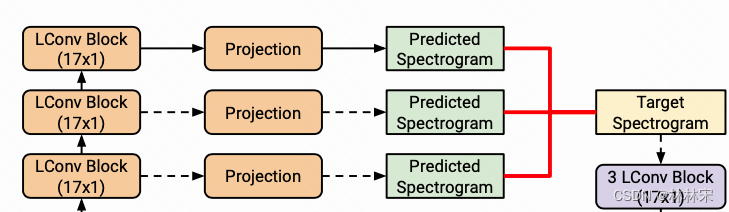
- 每一个LConv Block的输出都直接被转到128维的mel谱特征,计算L1 Loss,sum(L1 Loss)
Loss
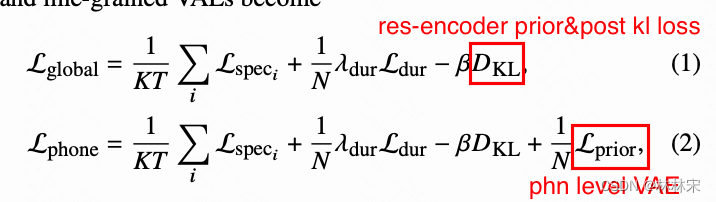
2. parallel tacotron2
abstract
- motivation:parallel tacotron是需要额外的对齐器,这增加了系统的复杂度,并且高度依赖对齐器的好坏。因此提出一个不需要对齐器、也不需要teacher-forcing duration info的合成系统。
- 包括:(1)可微分的时长模型(不需要监督的时长信号),soft-DTW
(2)upsample using attention with a novel auxiliary context ;
(3) iterative recon-loss基于soft-DTW,学习token-frame的对齐
introduction
Flow-TTS从token预测frame级别特征,使用teacher-forcing使预测和真实长度mismatch接近。
PT2也使用dot-product,从token预测时长,使用soft-DTW loss解决长度不匹配的问题。
- parallel Tacotron-1的问题
- 使用aligner得到对齐时长,时长处理时候有四舍五入的操作,该操作是不可导的;因此四舍五入的错误不会参与梯度反传(该错误无法校正);
- 训练时候用的真实duration,预测时候用的predict duration,因此mel重建损失无法参与duration predictor预测的提度反传。
——————————————————
学到token和frame mel之间的对齐信息,且duration model可以参与梯度反传。
- duration由自然数N表示修改为实数R
- token2frame mapping
related work
- Parallel Tacotron2 的主要改进在时长预测的部分,使用可微分时长建模以及learned upsampling提取对齐和模型时长。
- AlignTTS, JDI-T 和 EfficientTTS 使用联合训练的对齐模型得到时长信息,为了将token上采样,AlignTTS, JDI-T 使用 length regulator 信息, EfficientTTS使用Gaussian kernel mechanism;
- FlowTTS直接预测token在句中对应的帧数,而不预测token的时长。(这个地方没太明白??)
- EATS 的对齐是基于block-alignment假设,先随机给一个时长,在这个范围内使用softDTW对齐;PT2也是使用softDTW,但是没有这个假设,是基于整句进行的对齐。
model arch
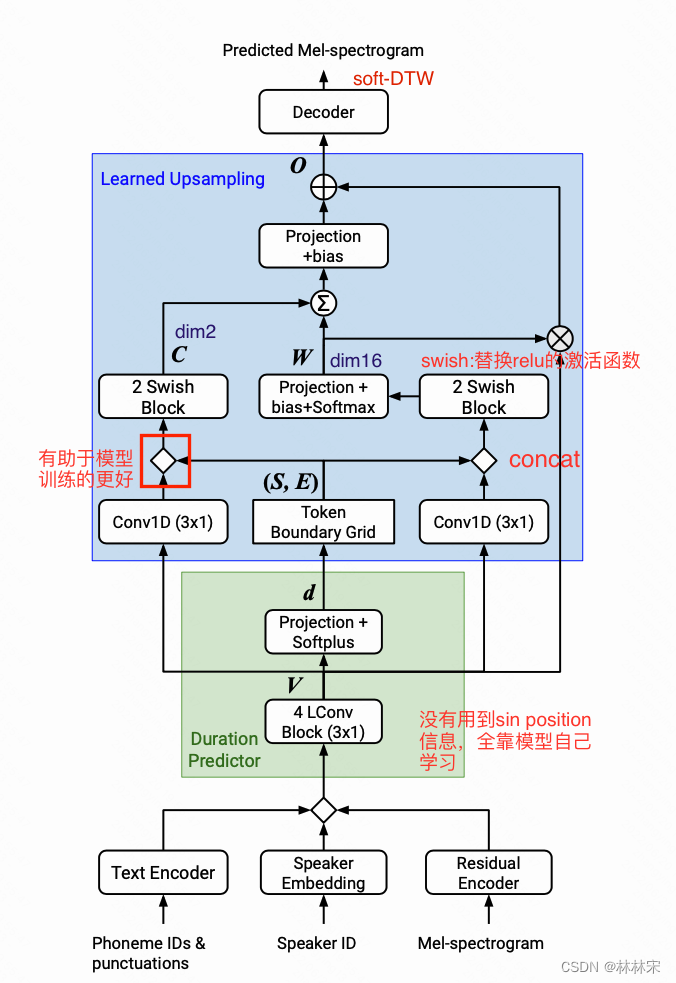
soft-DTW

这篇关于Parallel Tacotron 12的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!