声音专题

树莓派5_opencv笔记27:Opencv录制视频(无声音)
今日继续学习树莓派5 8G:(Raspberry Pi,简称RPi或RasPi) 本人所用树莓派5 装载的系统与版本如下: 版本可用命令 (lsb_release -a) 查询: Opencv 与 python 版本如下: 今天就水一篇文章,用树莓派摄像头,Opencv录制一段视频保存在指定目录... 文章提供测试代码讲解,整体代码贴出、测试效果图 目录 阶段一:录制一段

三文带你轻松上手鸿蒙的AI语音03-文本合成声音
三文带你轻松上手鸿蒙的AI语音03-文本合成声音 前言 接上文 三文带你轻松上手鸿蒙的AI语音02-声音文件转文本 HarmonyOS NEXT 提供的AI 文本合并语音功能,可以将一段不超过10000字符的文本合成为语音并进行播报。 场景举例 手机在无网状态下,系统应用无障碍(屏幕朗读)接入文本转语音能力,为视障人士提供播报能力。类似微信读书,可以实现将文章内容通过语音朗读,可以

ubuntu24.04 为什么扬声器没有声音,但是戴上耳机有声音
扬声器在 Ubuntu 24.04 下没有声音,但耳机有声音,可能是由于以下几个原因造成的: 1. 输出设备设置问题 系统可能将默认输出设备设置为耳机,而非扬声器。你可以检查或更改音频输出设备: 打开“设置” -> “声音”。在“输出”部分,查看默认输出设备是否是扬声器。如果不是,请手动选择扬声器作为输出设备。 2. 静音或音量设置问题 扬声器的音量可能被设置为静音或过低: 在“声音”

FSCapture屏幕录制没声音
今天参加培训,想着录屏腾讯会议下来,复习时可以慢慢看,结果播放时只有自己的声音。。。 但是录制B站其他视频播放却有声音。 解决方法:录制音频(麦克风+扬声器) 希望以后再也不要出现忘记录屏录音和录屏后无声音了

js-基于AudioContext在canvas上显示声音波形
js-基于AudioContext在canvas上显示声音波形 目录 文章目录 前言效果展示代码展示`index.html``Aud.js` 前言 从ES7后开始启用AudioContex常用API是:createScriptProcessor, onaudioprocess, getChannelData注意:onaudioprocess已经废弃,开始改用Analyse

QT---Windows下发布,不显示图标、是声音或是乱码
在qt安装目录下,找到:/qt/plugins,找到了plugins文件夹: 1.显示中文乱码: 在plugins文件夹下找到codecs文件夹: 在Main主函数里加: QApplication::addLibraryPath("./plugins"); QTextCodec::setCodecForLocale(QTextCodec::codecForName("GB2312"));

从0开始训练基于自己声音的AI大模型(基于开源项目so-vits-svc)
写在前面: 本文所使用的技术栈仅为:Python 其他操作基于阿里云全套的可视化平台,只需要熟悉常规的计算机技术即可。 目录 Step 1:注册及登录阿里云主机 Step 2:找到大模型项目 Step 3:创建大模型环境实例 Step 4:进入Ai_singer教程 Step 5:环境及预训练模型下载 Step 6:训练数据准备 Step 7:数据预处理和切分配置 Ste

关于声音函数sound()在codeblocks中的使用问题
函数名: sound 功 能: 以指定频率打开PC扬声器 用 法: void sound(unsigned frequency); 程序例: /* Emits a 7-Hz tone for 10 seconds. Your PC may not be able to emit a 7-Hz tone. */ #include <dos.h> int main(

UE5学习笔记20-给游戏添加声音
一、准备音频资源 1.Jump文件夹中有跳跃的音频资源wav文件夹中是SoundCue的音波资源 2.音乐衰减文件,右键->音频->音效衰减 二、 在对应的动画资源处将音频添加 1.找到对应的动画帧 2.在对应的行右键添加通知->播放音效 3、选中添加的音效选择对应的音频资源

【AI音频处理】:重塑声音世界的无限可能
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 文章目录 引言一、语音识别:人机交互的新篇章二、语音合成:让机器“说话”的艺术三、音乐创作与推荐:AI赋予音乐新生命四、声音效果处理:让声音更加完美五、AI在音频分析中的深度应用情感识别语音生物识别 六、AI在音乐创作中的创新实践风格迁移实时伴奏与即兴创作 七、AI在音频处理中的挑战与未来技术挑战未来展望 结语

音频检测电路 | 声音传感器模块 | 口哨开关 | Arduino
音频检测电路 | 声音传感器模块 | 口哨开关 | Arduino 案例分析电路设计1. **基本音频检测电路设计**电路结构:2. **灵敏度调节原理**方法:3. **非 MCU 控制的 LED 触发**设计步骤:4. **电路示例**5. **示意图(文本描述)**总结 实验方法 案例分析 一个硅胶娃娃,挤压或拍打会亮灯; 这个硅胶玩偶的工作原理可能是基于以下几个

Win11 操作(七)声音降噪
前言 为了听脚步和不外放声音影响到女朋友休息,于是买了S21头戴式耳机,虽然目的都达到了,但是又有新问题出现 损害队友听力 由于天气炎热,家里都开着风扇,但是耳机没有降噪功能所以我的麦噪音极大,这就导致我极大的不方便。如果是按键说话,有时候又忘记按键,如何自由麦则污染队友耳朵。 但是自己在KOOK平台上,通过平台的只能降噪,发现效果很好队友都不吐槽我的麦炸了。于是我就想有没有本地降噪的软件

3D 声音实验室开始提供3D音频制作
音频是制作沉浸式虚拟现实(VR)或360度体验的重要组成部分。 3D 声音实验室专注于3D / VR音频,并已宣布音频技术随时可供MainBerlin工作室的创作者和艺术家使用。 3D 声音实验室使用最先进的3D音频技术,由Sf?ar提供,Sf?ar是3D声音实验室与Voodoopop合资组建的双耳3D声音制作工具的顶级品牌。 MainBerlin的共同所有者Peer N

探索多模态人工智能:融合视觉、语言与声音的未来智能系统
前言 在这个信息爆炸的时代,人工智能(AI)已经渗透到我们生活的每一个角落,从智能手机的语音助手到自动驾驶汽车,再到医疗诊断和个性化推荐系统。然而,随着技术的进步,我们对智能系统的要求也在不断提高。我们不再满足于单一的智能功能,而是期待它们能够理解并处理来自不同源的复杂信息——这正是多模态人工智能(Multimodal AI)的魅力所在。 多模态AI技术,它通过融合多种模态的数据——文

多听听牛逼人物的声音
这是蜗牛的第 64 篇原创分享。 大家好,我是蜗牛。 昨天是阿里日的前一天,看了云直播的集体婚礼。比较羡慕那 102 对新人。突然间想结婚,想想还没女朋友,就拉回现实。 晚上听几个阿里合伙人现场访谈,有提到疫情,有提到内网发帖,有提到蒋凡事件,有提到月饼事件,有提到价值观和道德的差别,有提到最新的人才观,有提到业务之间的融合,有提到直播风口的讨论。 这里我整理下这些牛逼人物的观点,再谈谈我的思考

如何识别视频里的声音转化为文字?视频转文字方法
如何识别视频里的声音转化为文字?识别视频声音转文字技术,不仅极大地提升了信息处理的效率,还促进了跨语言沟通和文化交流。在全球化背景下,它成为了连接不同语言群体的桥梁。此外,随着人工智能技术的不断进步,这一领域的算法不断优化,使得识别准确率更高,处理速度更快,为各行各业带来了更加便捷、智能的解决方案。以下将详细介绍这些工具: 方法一:口袋视频转换器 这款工具可以将视频里的声音转化为文字。除了这一

显示器熄屏待机时,音响持续发出USB插入和拔出的声音的解决方法!
电脑电源计划设置经过一段时间自动关闭显示屏,当显示屏关闭的时候,连接电脑主机的音响会每隔大约5秒左右持续播放USB插入和拔出的提示声,非常烦人。 网上搜索的解决方法是在显示器的设置中将输入源的【自动输入】关闭即可。原因是显示器信号被主机切断之后,显示器自己会去向主机请求查找信号源,主机接收到命令后不断去检查是否有插入和拔出外部设备就会导致持续有提示音。 但是!但是!但是!当显示

模型案例:| 音频识别-报警器声音识别模型
导读 2023年以ChatGPT为代表的大语言模型横空出世,它的出现标志着自然语言处理领域取得了重大突破。它在文本生成、对话系统和语言理解等方面展现出了强大的能力,为人工智能技术的发展开辟了新的可能性。同时,人工智能技术正在进入各种应用领域,在智慧城市、智能制造、智慧医疗、智慧农业等领域发挥着重要作用。 柴火创客2024年将依托母公司Seeed矽递科技在人工智能领域的创新硬件,与全球创客爱好者

终于等到“你”之“失踪的桌面声音图标”
今天早上照例听英语的时候,觉得声音有点小听不清,而播放器的声音已经是放到最大了,于是就下意识的想点开左面右下角的喇叭按钮,可是我这才发现原本应该有的喇叭图标却怎么找也找不着了,这可把我给伤心的哟! 于是乎,便上搜了搜,总结如下: 一、 原因: 1、 病毒木马破坏了本机声卡相关的组件,当声卡驱动程序有关的组件被病毒破坏时,就可能导致电脑不能发声; 2、 控制面板,多媒体,

用ffmpeg拉流HLS转推至nginx-rtmp-module没有声音的问题
命令行很简单,如下 ffmpeg -re -analyzeduration 8000 -probesize 200000 -i http://ip1/test.m3u8 -strict -2 -c:v copy -c:a copy -bsf:a aac_adtstoasc -f flv rtmp://ip2/test/1 从ip1所在的服务器拉一路HLS直播流,转推给ip2所在的服务器上的n

android13隐藏调节声音进度条下面的设置按钮
总纲 android13 rom 开发总纲说明 目录 1.前言 2.情况分析 3.代码修改 4.编译运行 5.彩蛋 1.前言 将下面的声音调节底下的三个点的设置按钮,隐藏掉。 效果如下 2.情况分析 查看布局文件 通过布局我们可以知道这个按钮就是 com.android.keyguard.AlphaOptimizedImageBu
AudioSep:从音频中分离出特定声音(人声、笑声、噪音、乐器等)本地一键整合包下载
AudioSep是一种 AI 模型,可以使用自然语言查询进行声音分离。这一创新性的模型由Audio-AGI开发,使用户能够通过简单的语言描述来分离各种声音源。 比如在嘈杂的人流车流中说话的录音中,可以分别提取干净的人声说话声音和嘈杂的人流车流噪声。可以根据需求分离,保留人声或者噪声。甚至可以单独提取声音中的笑声。除此之外,还能提取伴奏声音里指定的乐器声音,比如一段钢琴和吉他合奏曲目,需要单独分

QQ语音麦克风没声音,但其他地方能用麦克风(USB耳机麦克风)
除了QQ语音,其他地方麦克风都好好的,耳机也是新买的,怎么回事呢? 别怀疑,就是QQ的问题 我在找遍了各种教程,设置了各种隐私性注册表等等等等的东西后,发现 一点用都没有 ,真是让人绝望 但上帝为你关上一扇窗的同时,还会给你留个通风口 如何解决 此处用win11举例(别问我为什么不是win10,电脑自带的,win11狗都不用) 点这个,win10里也有同样的东西,找找看

用python克隆了前男友的声音
声音克隆开源项目推荐:MockingBird 项目简介 MockingBird 是一个由开源社区开发的声音克隆项目,托管在 GitHub 上。该项目旨在通过深度学习技术实现高质量的声音克隆,使用户能够合成任意人的声音,并生成自然、流畅的语音输出。MockingBird 的核心功能包括语音转换、文本到语音(TTS)合成以及多种音色的自定义调整。它为研究人员、开发者以及对语音技术感兴趣的爱好者
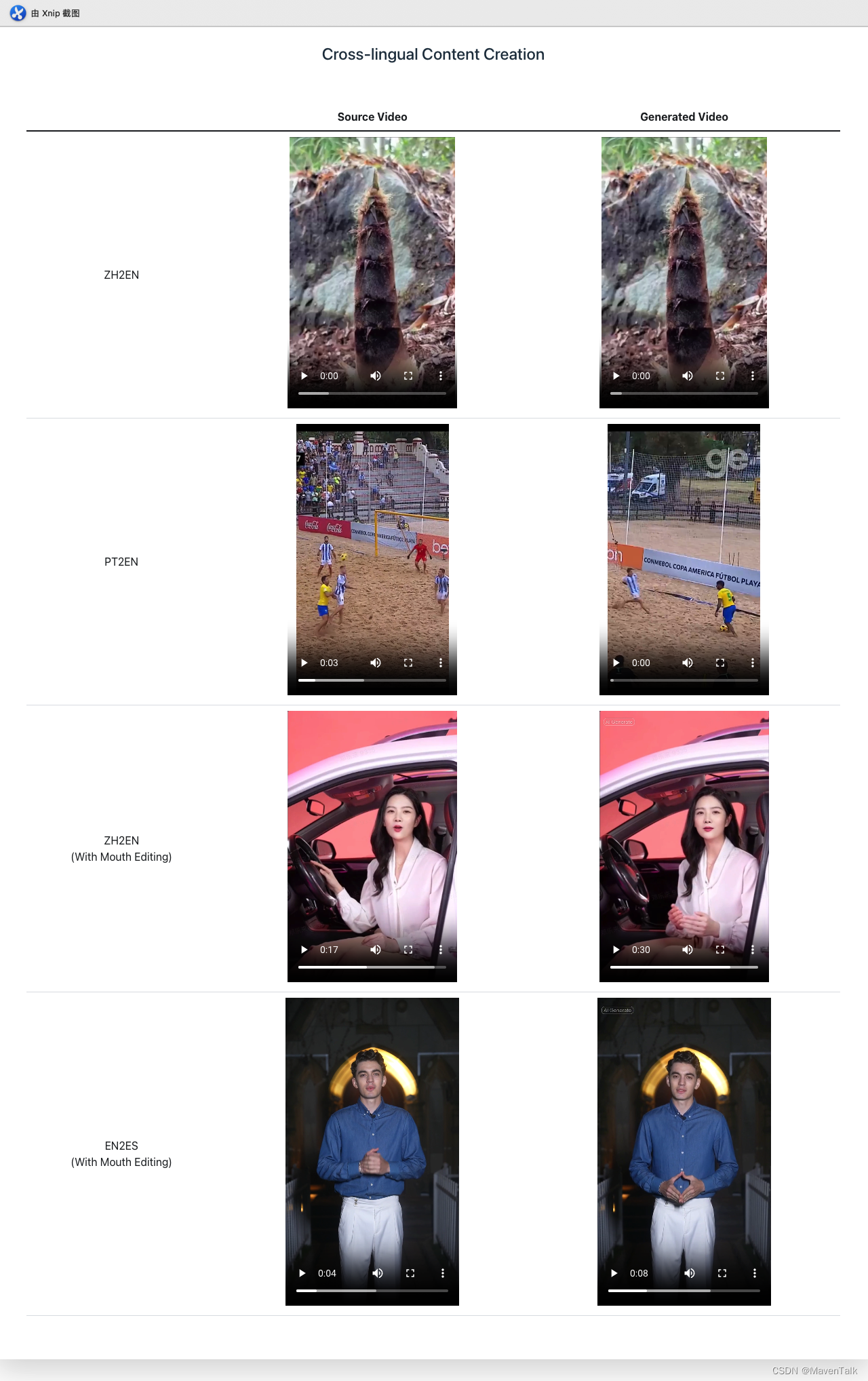
豆包高质量声音有望复现-Seed-TTS
我们介绍了 Seed-TTS,这是一个大规模自回归文本转语音 (TTS) 模型系列,能够生成与人类语音几乎没有区别的语音。Seed-TTS 作为语音生成的基础模型,在语音上下文学习方面表现出色,在说话人的相似性和自然性方面取得了与客观和主观评估中基本人类语音相匹配的表现。通过微调,我们在这些指标上获得了更高的主观分数。Seed-TTS 对各种语音属性(如情感)具有卓越的可控性,并且能够为野外的说话