speech专题
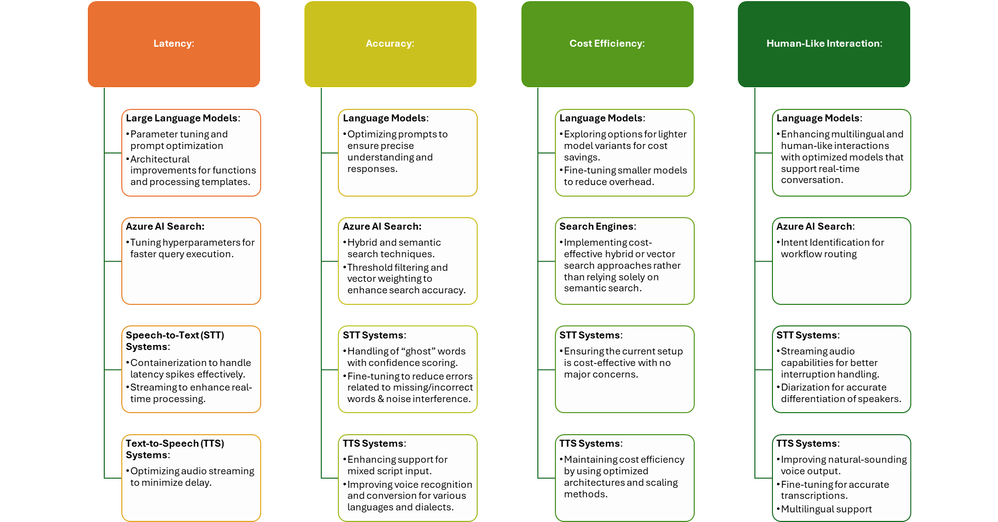
AI语音机器人:通过 Azure Speech 实现类人类的交互
语音对话的重要性 在竞争日益激烈的客户互动领域,人工智能语音对话正成为重中之重。随着数字参与者的崛起,组织认识到语音机器人的强大力量,它是一种自然而直观的沟通方式,可以提供类似人类的体验,深度吸引用户,并让他们从竞争对手中脱颖而出。无缝客户服务、个性化协助和即时信息访问的需求推动了对高质量语音交互的需求不断增长。此外,随着公司努力保留和扩大收入,跨越语言障碍接触更多样化的客户群变得至关重要,这使

【原创】edge-tts与基于mpv的edge-playback,使命令行和Python的Text To Speech唾手可得
最近想用Python脚本写一个TTS的小工具。一顿查找下来,发现AI时代手机端上这么普遍的TTS功能,居然在Web上这么稀有。估计都是被云API厂商拿去赚钱了。幸好Edge浏览器还是比较良心地提供了这个功能,不过又是和浏览器紧密结合的。 最终功夫不负有心人,发现了edge-tts与edge-playback,使命令行和Python脚本的Text To Speech唾手可得。先记录下来,找时间再丰
IBM Speech to Text:发出语音识别请求
要使用 IBM Watson® Speech to Text 服务请求语音识别,您只需提供要转录的音频。 服务为其每个接口(WebSocket 接口、同步 HTTP 接口和异步 HTTP 接口)提供了相同的基本转录功能。 以下示例显示了每个服务接口的基本转录请求 (不含可选参数): 这些示例将提交名为 audio-file.flac的简短 FLAC 文件。示例使用缺省语言模型 en-US_Br

教你用 Web Speech API 和 Node.js 来创建一个简单的 AI 聊天机器人
使用语音命令在今天变得非常普遍,许多手机用户使用像 Siri 和 Cortana 这样的语音助手,我们的卧室也被亚马逊的 Echo 和 Google Home 这样的设备“入侵”了。这些系统都离不开语音识别软件,现在,我们的浏览器也友好支持了 Web Speech API,可以让用户在 Web 应用中集成语音功能。 这篇文章将介绍如何使用 API 来在浏览器中创建人工智能语音聊天界面。这个应用会
Speech JS:JavaScript 的语音识别与合成
随着人工智能和自然语言处理技术的快速发展,语音识别和语音合成已经成为许多应用程序的重要功能。在 Web 开发领域,Speech JS 是一个非常实用的工具库,它使得在 JavaScript 应用中实现语音识别和语音合成变得更加简便和高效。 什么是 Speech JS? Speech JS 是一个基于 Web Speech API 的 JavaScript 库。Web Speech API 是一

LLaSM:Large language and speech model
1.Introduction 级联方法使用ASR将语音输入转化为文本输入,语音到文本会导致信息损失,本文提出LLaSM,一个具有跨模态对话能力的大型语音与语言模型,能够理解和遵循语音与语言指令,借鉴LLaVA,利用预训练的语音模态编码器和大语言模型,使用Whisper作为语音编码器,将语音信号转化为嵌入,然后,一个模态适配器学习将语音嵌入与大模型的输入文本嵌入对齐,将语音嵌入和文本嵌入串联起

google speech command dataset的生成
GitHub - hyperconnect/TC-ResNet: Code for Temporal Convolution for Real-time Keyword Spotting on Mobile Devices 模型要分出几类: def prepare_words_list(wanted_words): """Prepends common tokens to the cu

Google speech command 数据集获取
🏆本文收录于「Bug调优」专栏,主要记录项目实战过程中的Bug之前因后果及提供真实有效的解决方案,希望能够助你一臂之力,帮你早日登顶实现财富自由🚀;同时,欢迎大家关注&&收藏&&订阅!持续更新中,up!up!up!! 问题描述 在关键字检测领域,一个比较流行的数据集就是Google Speech Commands,但是目前根据链接或者是在pytorch中直接下载,都是下载的3

音频筑基:200字说清声和音的区别(Sound/Audio/Music/Voice/Speech辨析)
音频筑基:200字说清声和音的区别(Sound/Audio/Music/Voice/Speech辨析) 音频筑基:200字说清声和音的区别 音频筑基:200字说清声和音的区别(Sound/Audio/Music/Voice/Speech辨析) 梳理如下: 声音 声(Sound) 广义:机械波产生的振动狭义:人耳可听到的振动(20-20kHz) 音(Audio) 有意义的声(滤去
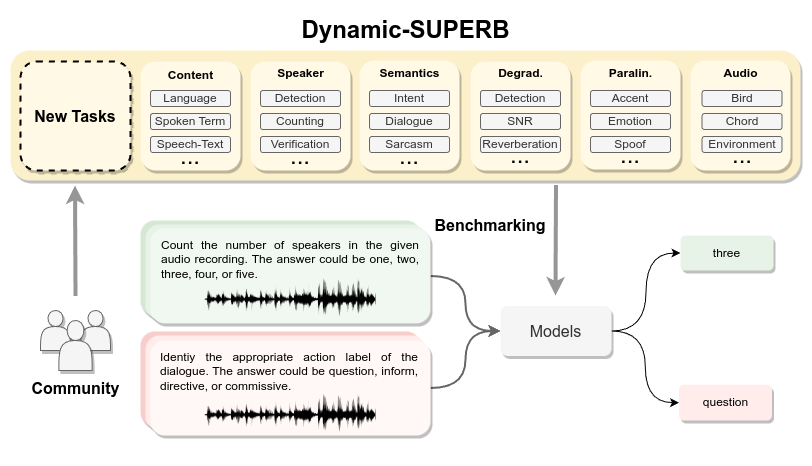
关于Speech processing Universal PERformance Benchmark (SUPERB)基准测试及衍生版本
Speech processing Universal PERformance Benchmark (SUPERB)是由台湾大学、麻省理工大学,卡耐基梅隆大学和 Meta 公司联合提出的评测数据集,其中包含了13项语音理解任务,旨在全面评估模型在语音处理领域的表现。这些任务涵盖了语音信号的各个方面,包括语言学、说话人、韵律和语义元素。 具体来说,SUPERB包含以下13项任
Speech Processing for IP Networks: Media Resource Control Protocol
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Media Resource Control Protocol (MRCP) is a new IETF protocol, providing a key enabling technology that
【PAT】1071. Speech Patterns (25)【map容器的使用】
题目描述 People often have a preference among synonyms of the same word. For example, some may prefer “the police”, while others may prefer “the cops”. Analyzing such patterns can help to narrow down a s
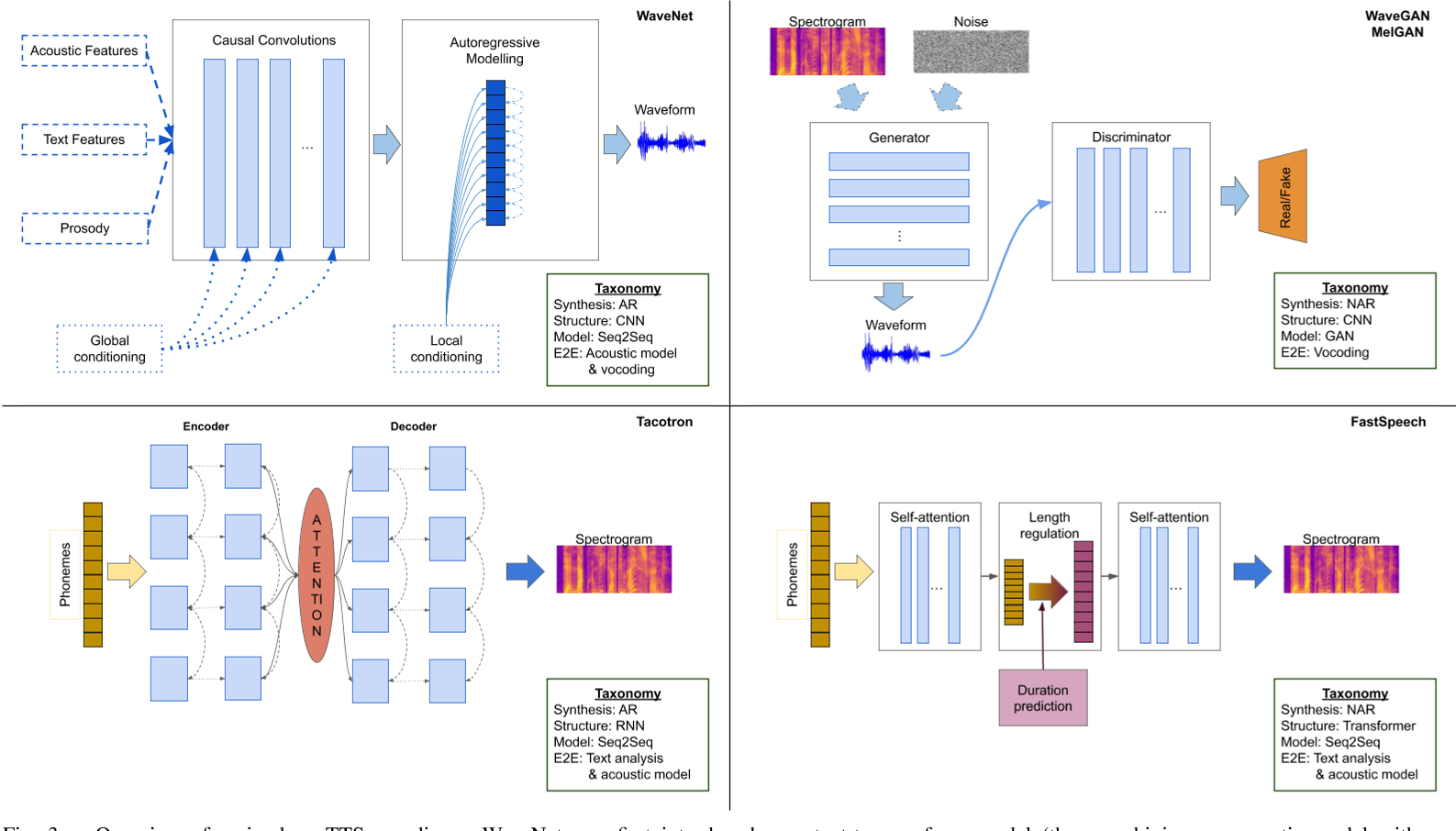
语音合成综述Speech Synthesis
目录 语音合成概述语音信号基础语音特征提取音库制作和文本前端声学模型声码器 一、语音合成概述 语音信号的产生分为两个阶段,信息编码和生理控制。首先在大脑中出现某种想要表达的想法,然后由大脑将其编码为具体的语言文字序列,及语音中可能存在的强调、重读等韵律信息。经过语言的组织,大脑通过控制发音器官肌肉的运动,产生出相应的语音信号。其中第一阶段主要涉及人脑语言处理方面,第二阶段涉及语音信号产生的生
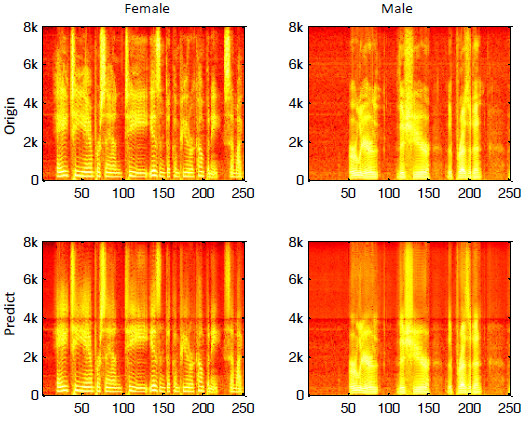
A Deep Neural Network Approach To Speech Bandwidth Expansion
题名:一种用于语音带宽扩展的深度神经网络方法 作者:Kehuang Li;Chin-Hui Lee 2015年出来的 摘要 本文提出了一种基于深度神经网络(DNN)的语音带宽扩展(BWE)方法。利用对数谱功率作为输入输出特征进行所需的非线性变换,训练神经网络来实现这种高维映射函数。在10小时的大型测试集上对该方法进行评估时,我们发现与传统的基于高斯混合模型(GMMs)的BWE相比,DNN扩展

p0001--汪德亮2018--Supervised Speech Separation Based on DeepLearning: An Overview
今天开始看汪德亮的Supervised Speech Separation Based on DeepLearning: An Overview做一个翻译为主的个人笔记 abstract:语音分离是指将目标语音从背景干扰中分离出来,传统的方式是从信号处理的角度解决的。最近,多种监督学习的算法用于语音分离,尤其是基于深度学习的监督算法,大大提升了分离的性能。本文主要介绍近几
5.4.2、【AI技术新纪元:Spring AI解码】OpenAI Text-to-Speech (TTS) Integration
OpenAI文本转语音(TTS)集成 简介 音频API基于OpenAI的TTS(文本转语音)模型提供了一个语音端点,用户可以: 朗读一篇书面博客文章。以多种语言生成语音输出。利用流媒体实现实时音频输出。 必要条件 创建OpenAI账号并获取API密钥。您可以在OpenAI注册页面上注册,并在API密钥页面上生成API密钥。 自动配置 Spring AI为OpenAI文本转语音客户
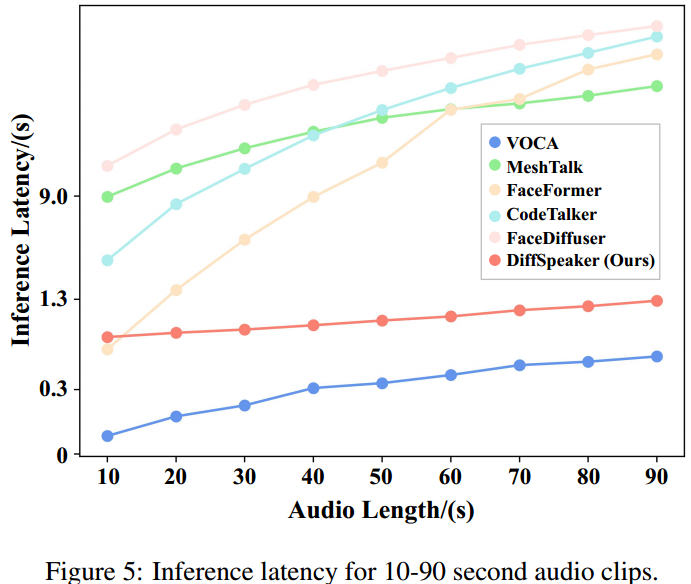
【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画 code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer paper:htt
web Speech Synthesis 文字语音播报,Audio 播放base64提示音
SpeechSynthesisUtterance基本介绍 SpeechSynthesisUtterance是HTML5中新增的API,用于将指定文字合成为对应的语音.也包含一些配置项,指定如何去阅读(语言,音量,音调)等 SpeechSynthesisUtterance基本属性 SpeechSynthesisUtterance.lang 获取并设置话语的语言SpeechSynthesisUtt
一段关于 Gesture Speech 的描述
一段关于 Gesture & speech 的描述 http://cslu.cse.ogi.edu/HLTsurvey/ch9node6.html#SECTION94

Web Speech API的语音识别技术
SpeechSynthesis对象 这是一个实验性技术 目前兼容性如图: pc端几乎兼容,移动端部分不兼容 网页语音 API 的SpeechSynthesis 接口是语音服务的控制接口; 它可以用于获取设备上关于可用的合成声音的信息,开始、暂停语音,或除此之外的其他命令。 SpeechSynthesis 也从它的父接口继承属性,EventTarget. SpeechSynthe
【 WPF】使用 System.Speech.Synthesis 命名空间中的 SpeechSynthesizer 类来朗读文本
在 WPF 中,你可以使用 System.Speech.Synthesis 命名空间中的 SpeechSynthesizer 类来朗读文本。下面是一个简单的示例代码,演示了如何使用 SpeechSynthesizer 类来朗读文本: using System;using System.Windows;using System.Speech.Synthesis;namespace YourNa

语音合成综述——亚洲微软谭旭《A Survey on Neural Speech Synthesis》上篇
受老师关怀、同学帮助,研一磕磕绊绊也算过去了,回过头来总结一下这一年入门不知道入没入进去的语音合成,正好从这篇大佬的综述理一理脉络,也算是研一的一个总结吧。 下图是本篇论文的结构框架图 论文从两个角度去总结这些年TTS语音合成的发展史,key components和advanced topics,因为文章很长,且我的知识储备并不能覆盖所有的模型,所以我会按照我的进度(较为热门易懂的端到端模型)去
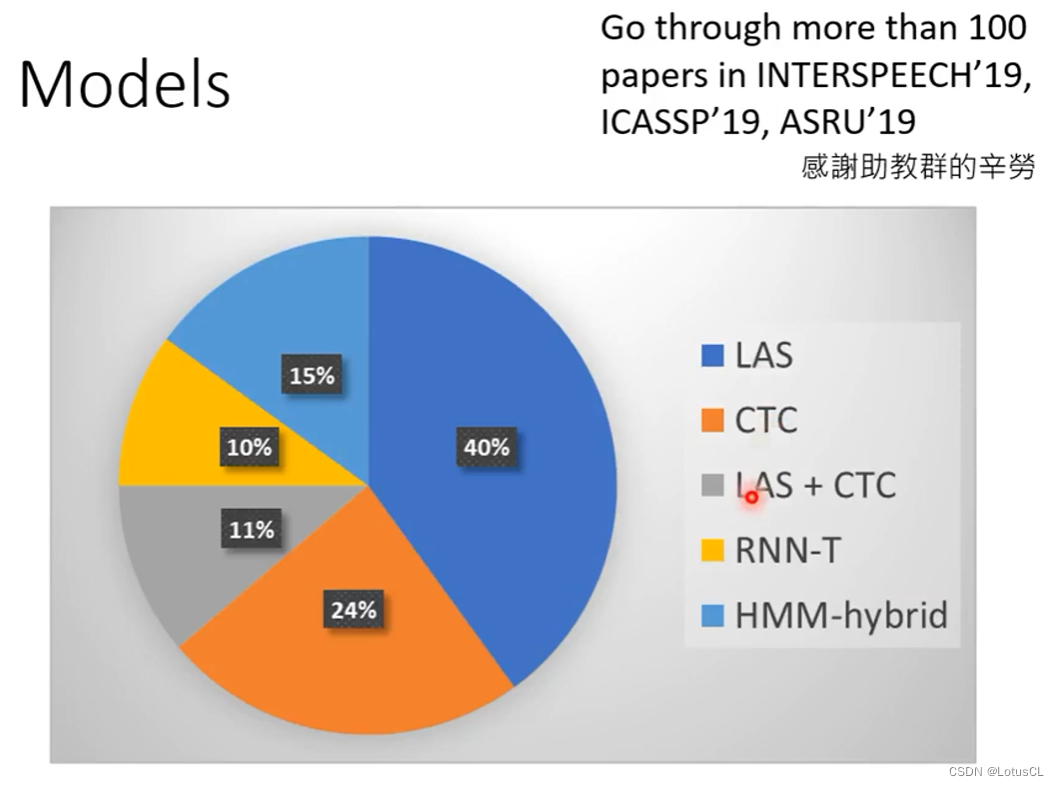
Speech Recognition,初见语音识别——语音信号处理学习(二)
从学习(二)开始,开始观看《李宏毅深度学习人类语言处理国语课程(2020)》 国内观看地址: Speech Recognition (Part 1)哔哩哔哩bilibili 语音模型:即将 sound 转为 text。 Text: a sequence of Token 长度:N,总种类数量:V Sound: vectors sequence 长度:T,维度:d 一、Text T
Microsoft Vista Speech Recognition Tested - Perl Scripting
http://www.youtube.com/watch?v=KyLqUf4cdwc 微软的语言识别系统! Powered by ScribeFire.
浙大PAT 1071题 1071. Speech Patterns
/*模拟题,混用c和c++了,代码比较乱。ps:"alphanumercial" mean that f4 is a word.*/#include<iostream>#include<string>#include<string.h>#include<map>using namespace std;char str[1050000];char ctmp[1050000];m

第八篇【传奇开心果系列】python的文本和语音相互转换库技术点案例示例:Google Text-to-Speech虚拟现实(VR)沉浸式体验经典案例
传奇开心果博文系列 系列博文目录python的文本和语音相互转换库技术点案例示例系列 博文目录前言一、雏形示例代码二、扩展思路介绍三、虚拟导游示例代码四、交互式学习示例代码五、虚拟角色对话示例代码六、辅助用户界面示例代码七、实时语音交互示例代码八、多语言支持示例代码九、情感识别示例代码十、自定义语音示例代码十一、场景感知示例代码十二、音效结合示例代码十三、交互式故事体验示例代码十四、个性化导