本文主要是介绍【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画
code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
paper:https://arxiv.org/pdf/2402.05712.pdf
出处:香港理工大学,HKISI CAS,CASIA,2024.2
1. 介绍
语音驱动的3D面部动画,可以用扩散模型或Transformer架构实现。然而它们的简单组合并没有性能的提升。作者怀疑这是由于缺乏配对的音频-4D数据,这对于Transformer在扩散框架中充当去噪器非常重要。
为了解决这个问题,作者提出DiffSpeaker,一个基于Transformer的网络,设计了有偏条件注意模块,用作传统Transformer中自注意力/交叉注意力的替代。融入偏置,引导注意机制集中在相关任务特定和与扩散相关的条件上。还探讨了在扩散范式内精确的嘴唇同步和非语言面部表情之间的权衡。
总结:提出了一种将Transformer架构与基于扩散的框架集成的新方法,特点是一个带偏置的条件自注意/交叉注意机制,解决了用有限音频- 4d数据训练基于扩散的transformer的困难。能够并行生成面部动作,推理速度很快。

2. 背景
条件概率模型:学习语音和面部运动之间的概率映射,为语音驱动的3D面部动画提供了一种有效方法。目前的技术仍然倾向于在简短的片段中创建面部动画,严重依赖于GRU的顺序处理能力[Cho等人,2014]或卷积网络,导致在处理上下文方面表现差,不如Transformer。
Transformer架构整合到扩散框架的困难:需要在整个长度范围内对面部运动序列进行降噪,这对于数据密集型注意力机制来说要求很高。
语音驱动的3D面部动画,从音频语音输入中生成逼真的面部动作,需要同步捕捉语音的音调、节奏和动态。之前的工作遵循确定性映射的范式,即一个音频对应一个面部动作。比如:制定将语音(音素)与面部运动(视素)联系起来的人工规则,并使用系统测量音素对视素的影响。最近的研究认识到任务中固有的一对多关系,一个语音输入可以对应多个面部动作。CodeTalker 使用量化码本学习这种复杂的数据分布,显著提高了性能。
扩散模型的概率映射:FaceDiffuser 采用基于扩散的生成框架和GRU来单独处理音频段。扩散模型也被应用于头部姿势的并发生成[Park等人,2023;Sun等人,2023],对个人用户的定制[Thambiraja等人,2023],以及扩散蒸馏[Chen等人,2023a]等方法来加速生成过程。一些并行研究[Park and Cho, 2023;Aneja等,2023;Zhao等人,2024]专注于自定义数据集的混合形状级动画。
3. 方法
将语音驱动的三维面部动画作为一个条件生成问题,目标是通过从后验分布![]() 中采样,基于语音a1:T和第k个人的说话风格sk,生成面部运动x1:T,包含V个顶点的模板面网格上的一个顶点序列x i∈R T×V×3。ai∈RD是一个音频片段,只产生一帧运动。说话风格sk∈RK是一个one-hot嵌入,表示K个人物。n越大表示xn中的高斯噪声越多,xn为纯高斯噪声,x0为期望的面部运动。马尔可夫链依次将高噪声xn转换为低噪声版本,直到得到面部运动分布:
中采样,基于语音a1:T和第k个人的说话风格sk,生成面部运动x1:T,包含V个顶点的模板面网格上的一个顶点序列x i∈R T×V×3。ai∈RD是一个音频片段,只产生一帧运动。说话风格sk∈RK是一个one-hot嵌入,表示K个人物。n越大表示xn中的高斯噪声越多,xn为纯高斯噪声,x0为期望的面部运动。马尔可夫链依次将高噪声xn转换为低噪声版本,直到得到面部运动分布:

其中![]() 。目标是得到
。目标是得到![]() 。为了在a和sk的指导下,从p(xn)推断出低噪分布p (xn−1),取神经元网络G,表达式为:
。为了在a和sk的指导下,从p(xn)推断出低噪分布p (xn−1),取神经元网络G,表达式为:
![]()
G作为去噪器,根据音频a、说话风格sk和扩散步长n,从xn中恢复面部运动x0。然后使用x0来构造马尔可夫链下一步的分布p(xn−1)。即DDIM过程,构造了相对较短的马尔可夫链,实现高效生成。
3.1 Diffusion-based Transformer Architecture
接下来介绍如何将语音a、风格sk和扩散步骤n的条件合并到Transformer体系结构中:网络g采用编码器-解码器架构,如图2所示,条件分别由Ea、Es、En编码,并提供给解码器D,解码器D对输入进行去噪:
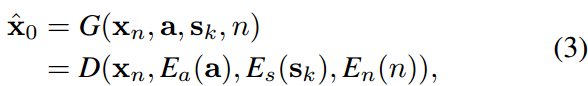
音频编码器ea = ea (a 1:T)∈RT×C是预训练的音频编码器,样式编码器es = es (sk)∈R1×C是线性投影层,步进编码器en = en (n)∈R1×C首先将标量n转换为频率编码,然后将其传递给线性层。重要的是,网络G并行处理所有帧步长t ={1,···,t},但在扩散步长n中发生变化。

Attention with Condition Tokens
3.2 Training Objective


![]()
4. 实验
4.1 Datasets and Implementations
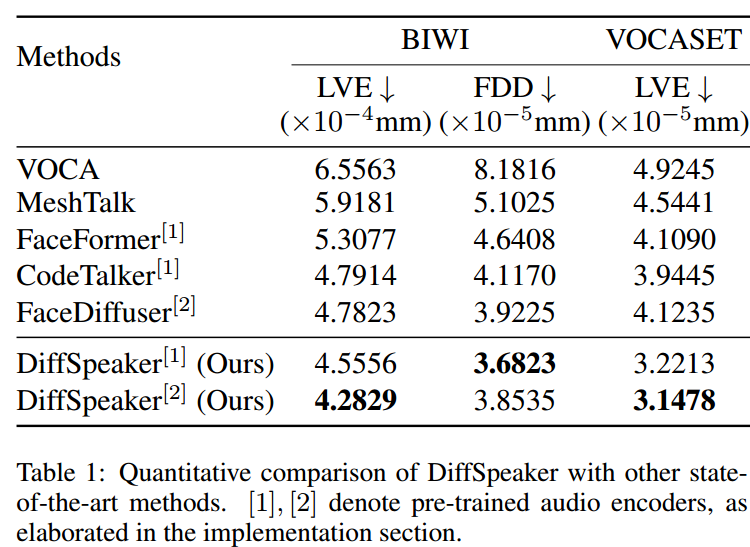

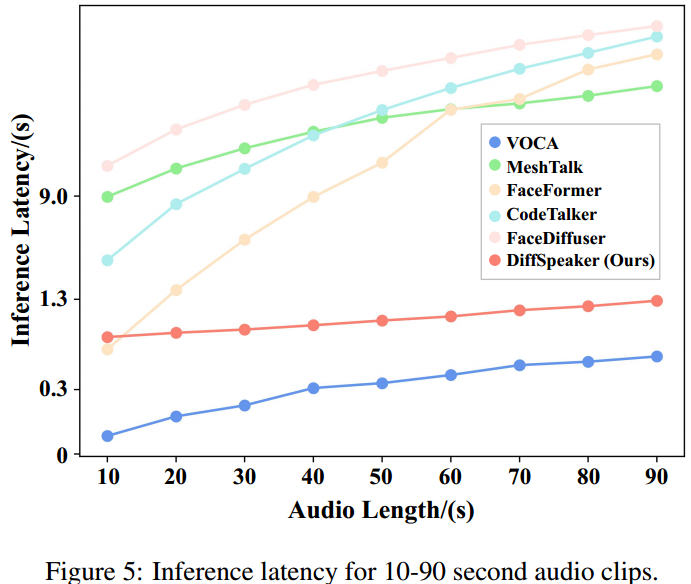
这篇关于【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








