facial专题

Deep Identity-aware Transfer of Facial Attributes
网络分为两部分,第一部分为face transform network,得到生成图像,该网络还包括一个判别网络用于判别输入图像的真假,以及一个VGG-Face Netowork,用于判别输入图像的性别,即identity loss. 利用face transform network得到的生成图像比较模糊,因此将生成图像输入一个enhancement network,得到增强图像. 网络结构如下

facial animation 资料总结
数据集: RAVDESS:website,download page 公开数据集,没有排行榜; paper(搜都搜不到): RAVDESS: The Ryerson Audio-Visual Database of Emotional Speech and Song, FaceWarehouse: project website, 私有数据集,需要申请,没有排行榜;SAVEE: proj
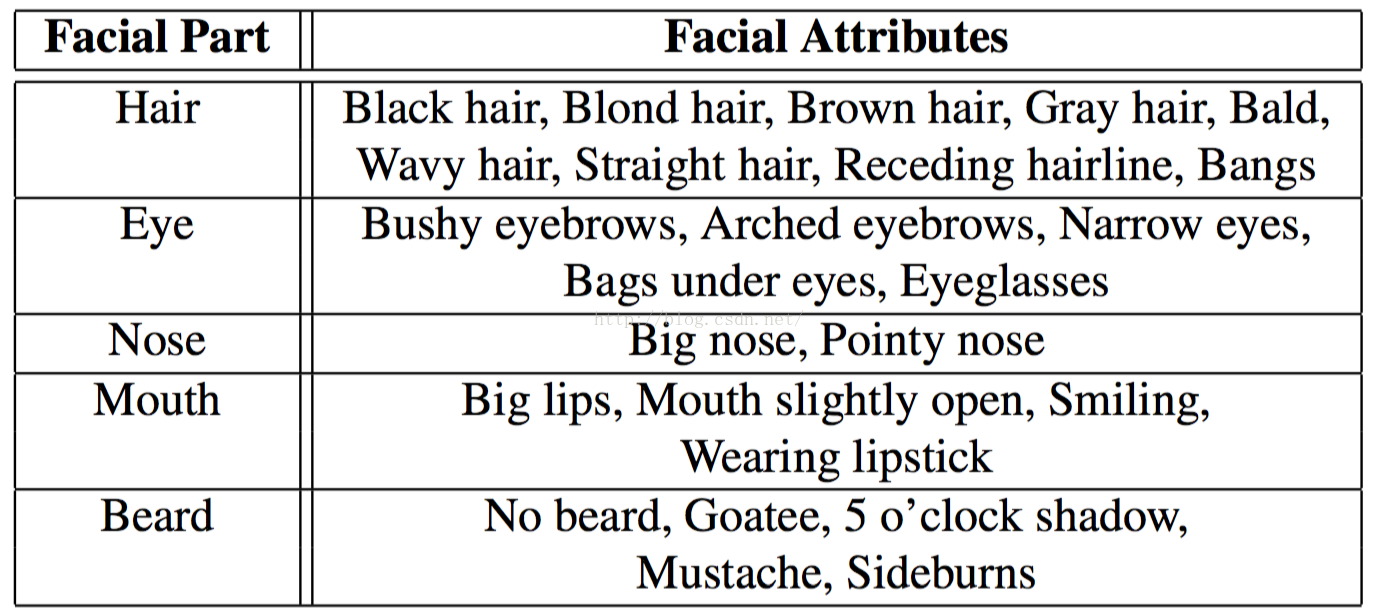
论文《From Facial Parts Responses to Face Detection: A Deep Learning Approach》笔记
论文:From Facial Parts Responses to Face Detection A Deep Learning Approach.pdf 实现:暂无 这篇论文发表于ICCV2015,很有借鉴意义,论文提出了一个新的概念deep convolutional network (DCN) ,在FDDB数据集上达到了目前世界领先水准,这篇论文可以与之前《Joint Cascad
Stop Staring: Facial Modeling and Animation Done Right
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp The book is friendly but also loaded with content and precise in its directions. "I am by no means Gods
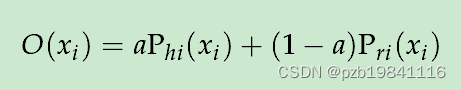
Facial Micro-Expression Recognition Based on DeepLocal-Holistic Network 阅读笔记
中科院王老师团队的工作,用于做微表情识别。 摘要: Toimprove the efficiency of micro-expression feature extraction,inspired by the psychological studyof attentional resource allocation for micro-expression cognit
Invarient facial recongnition
for later~ 代码阅读 1. 加载trainset import argparseimport loggingimport osimport numpy as npimport torchfrom torch import distributedfrom torch.utils.data import DataLoaderfrom torch.utils.tensorbo

Facial Expression Recognition with multi-scale Graph Convolutional Networks-论文笔记
这篇文章的作者是来自中国移动研究院的研究者,将图卷积神经网络应用与人脸表情识别中,并提出了一种新的通过人脸图片构建图结构的方法。 论文地址:Facial Expression Recognition with multi-scale Graph Convolutional Networks 1. Abstract Recognizing emotion through facial expr
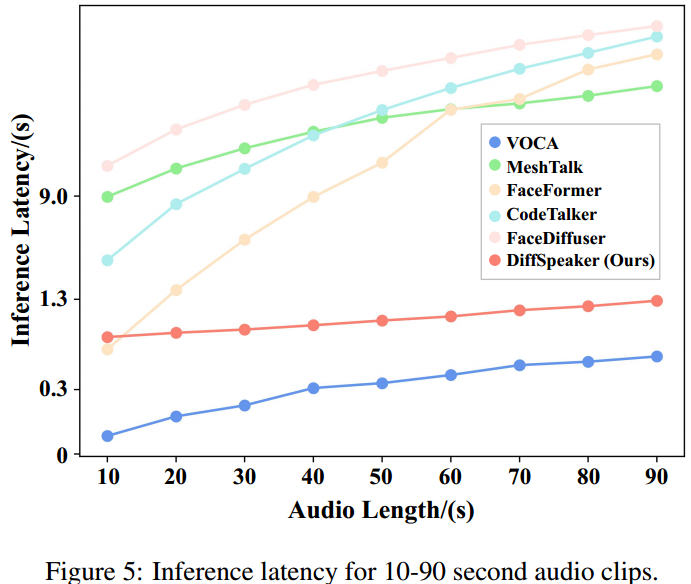
【论文阅读】DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
DiffSpeaker: 使用扩散Transformer进行语音驱动的3D面部动画 code:GitHub - theEricMa/DiffSpeaker: This is the official repository for DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer paper:htt
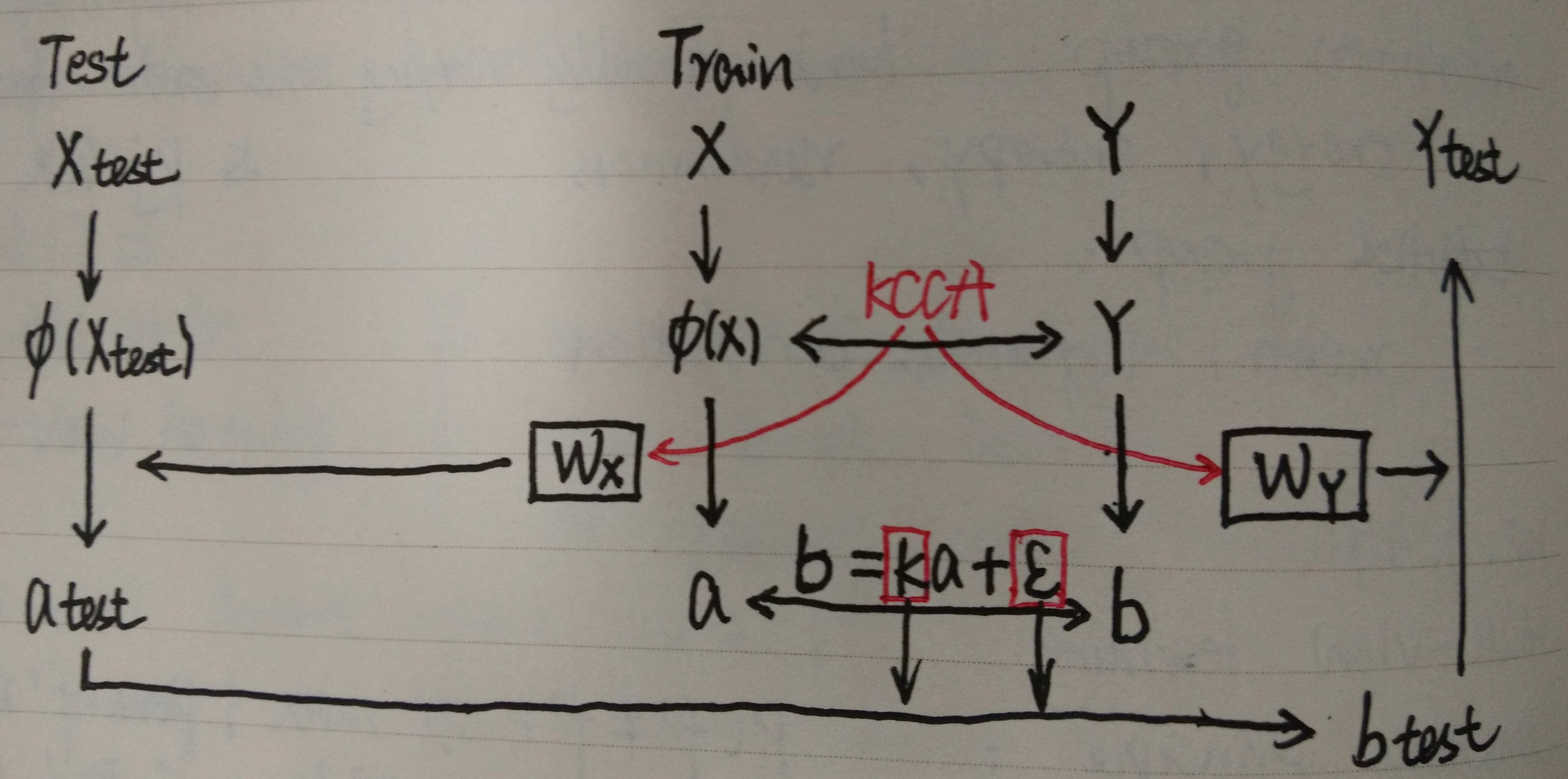
Facial Expression Recognition Using KCCA
Zheng, W., et al. (2006).Neural Networks, IEEE Transactions on 17(1): 233-238. 在每个面部图像标记34个特征点,利用Gabor变换提取特征,形成一个labeled graph(LG) vector,代表了面部图像的特征。对于每个训练的面部图像,the semantic ratings describing the ba

Computer Vision for Predicting Facial Attractiveness
转载:http://www.learnopencv.com/computer-vision-for-predicting-facial-attractiveness/ Computer Vision for Predicting Facial Attractiveness JULY 27, 2015 BY AVI SINGH 13 COMMENTS Most of us have lo
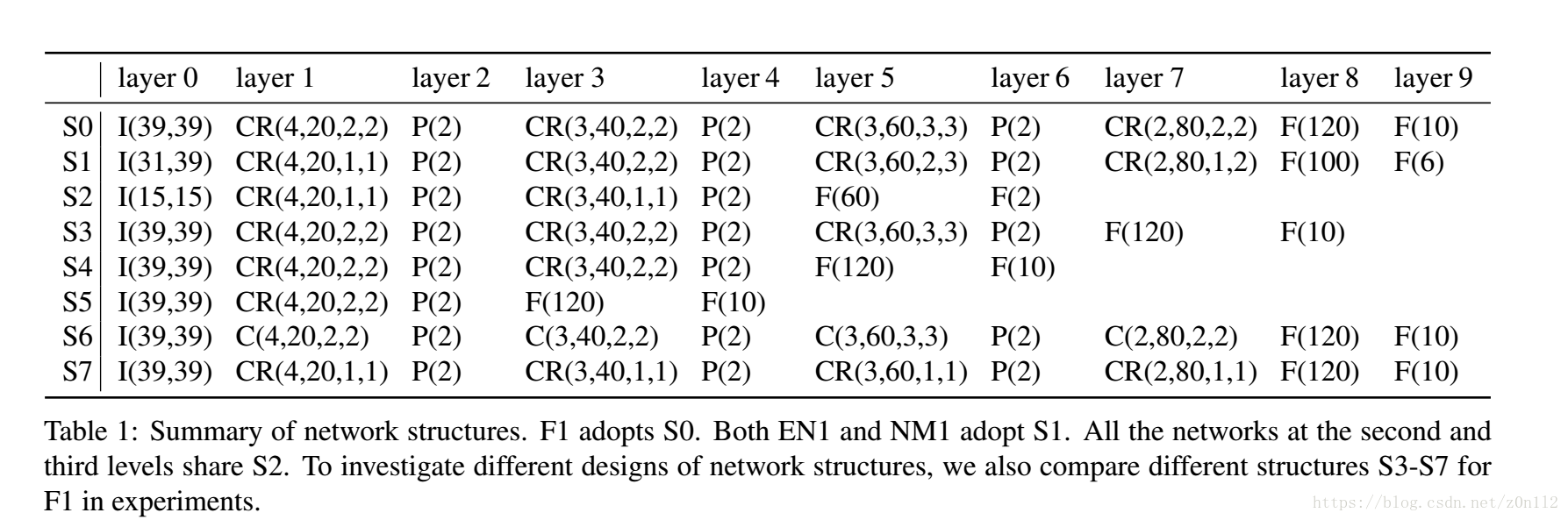
Deep Convolutional Network Cascade for Facial Point Detection
CVPR2013的一篇文献,利用CNN做人脸特征点定位. 为了进一步加深对mxnet的理解,准备做轮子. 上图是完整的架构图,包括Level 1, level 2, level 3 三级网络组成, 逐渐提高定位精度. Level 1 这一级由三个子网络组成,其中 * F1: 输入整个人脸区域,输出lefteye,righteye,nose,leftmouth,rightmouth共5个

Kaggle-Facial Keypoints Detection:原始数据保存为图片
python version: Python 3.6.4 如题,将原始数据“training.csv”中的图片数据保存成文件,直接上代码: import numpy as np import pandas as pd from PIL import Image training = pd.read_csv("training.csv") training['Image'] = trai

【论文阅读】Facial Motion Prior Networks forFacial Expression Recognition
Fig.1 显示了拟议的FMPN框架的体系结构,该框架由三个网络组成:面部运动掩码发生器(FMG)、先验融合网络(PFN)和分类网络(CN)。构建FMG是为了生成一个掩码,即人脸运动掩码,它突出显示给定灰度表情人脸的运动区域。PFN的目标是将原始输入图像与FMG生成的人脸运动掩码融合,将局部知识引入到整个框架中。CN是一种典型的卷积神经网络(CNN),用于特征提取和分类,如VGG、Res

Facial Landmark Detection
转自:http://www.cnblogs.com/lanye/p/5310090.html 源地址:http://www.learnopencv.com/facial-landmark-detection/#comment-2471797375 OCTOBER 18, 2015 BY SATYA MALLICK 51 COMMENTS Facial landmark de

多任务——Facial Landmark
《Facial Landmark Detection by Deep Multi-task Learning》2014 **要解决的问题:**人脸关键点的检测 **创新点:**在人脸关键点检测的同时进行多个任务的学习,包括:性别,是否带眼镜,是否微笑和脸部的姿势。使用这些辅助的属性可以更好的帮助定位关键点。这种Multi-task learning的困难在于:不同的任务有不同的特点,不同的收敛速
facial landmark datection-数据集
人脸特征点数据集,主要包括:性别,是否带眼睛,是否微笑和脸部姿势。 Facial landmark detection of face alignment has long been impeded by the problems of occlusion and pose variation. Instead of treating the detection task as a single
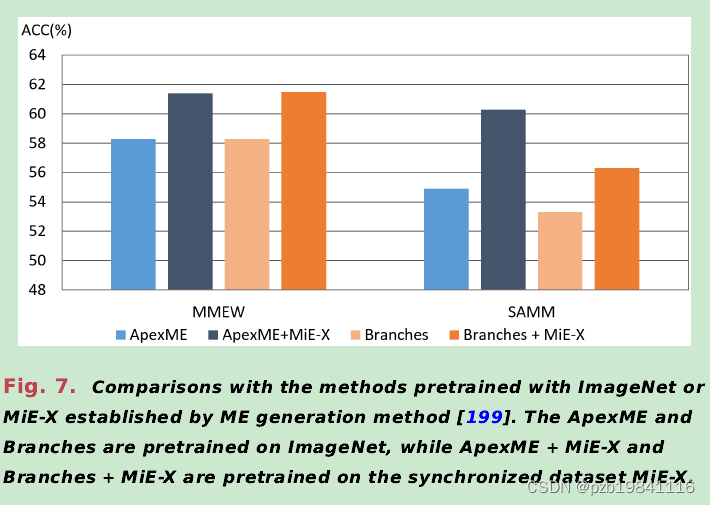
Facial Micro-Expressions:An Overview 阅读笔记
Proceedings of the IEEE上一篇微表情相关的综述,写的很详细。从心理学与计算机两个领域阐述了微表情生成的原因与相关算法,值得仔细研读。 摘要: Four main tasks in ME analysis arespecifically discussed,including ME spotting,ME recognition,ME action u

【翻译】Lighteweight and Effective Facial LandmarkDetection Using Adversarial Learning WithFace Geomet
Lighteweight and Effective Facial Landmark Detection Using Adversarial Learning With Face Geometric Map Generative Network 基于几何地图生成网络的对抗式学习的光照和有效的人脸地标检测 使用对抗学习和人脸几何地图生成网络进行轻量级和有效的人脸地标检测 作者:Hong

论文复现:Active Learning with the Furthest NearestNeighbor Criterion for Facial Age Estimation
Furthest Nearest Neighbor 方法就是其他文章中的Descripency方法,是一种diversity samplig方法。 由于特征空间是不断变化的,在特征空间上使用Descripency方法违背了该准则的初衷。 import osimport torchimport numpy as npfrom copy import deepcopyfro
![[MM18]BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network](https://img-blog.csdnimg.cn/2019111916545396.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3djaHN0cmlmZQ==,size_16,color_FFFFFF,t_70)
[MM18]BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network
BeautyGAN: Instance-level Facial Makeup Transfer with Deep Generative Adversarial Network ACM MM 2018http://liusi-group.com/projects/BeautyGANfacial makeup transfer | generative adversarial network

Graph based feature extraction and hybrid classification approach for facial expression recognition
基于图的特征提取和混合分类方法的面部表情识别 Author G. G. Lakshmi Priya e-mail:lakshmipriya.gg@vit.ac.in L. B. Krithika e-mail:krithika.lb@vit.ac.in School of Information Technology and Engineering, Vellore Institute of

Remote Photoplethysmograph Signal Measurement from Facial Videos Using Spatio-Temporal Networks
前言 前期方法的缺陷 早期rPPG研究多数为“提取—分析”的两阶段方法,首先检测或跟踪人脸以提取rPPG信号,然后分析并估计相应的平均HR。缺点:1)基于纯经验知识自定义的面部区域,不一定是最有效的区域,这些区域应该随数据而变化。2)有些方法中使用了手动制作的特征或过滤器,可能使重要的心跳信息丢失。 前期使用的深度学习方法也可能有一下缺点:1)HR估计任务被视
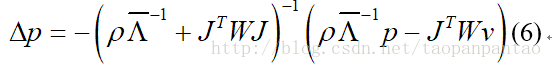
【翻译】Convolutional Experts Network for Facial Landmark Detection
【翻译】Convolutional Experts Network for Facial Landmark Detection 摘要: 约束局部模型(CLM)是一个成熟的面部标记点检测方法系列。然而他们最近不如 级联回归 方法流行。这部分是由于现有CLM局部检测器无法对表情,照明,面部毛发,化妆等影响的非常复杂的标记点外观进行建模。我们提出了一种新颖的局部检测器 - 卷积专家网络(CEN),它将
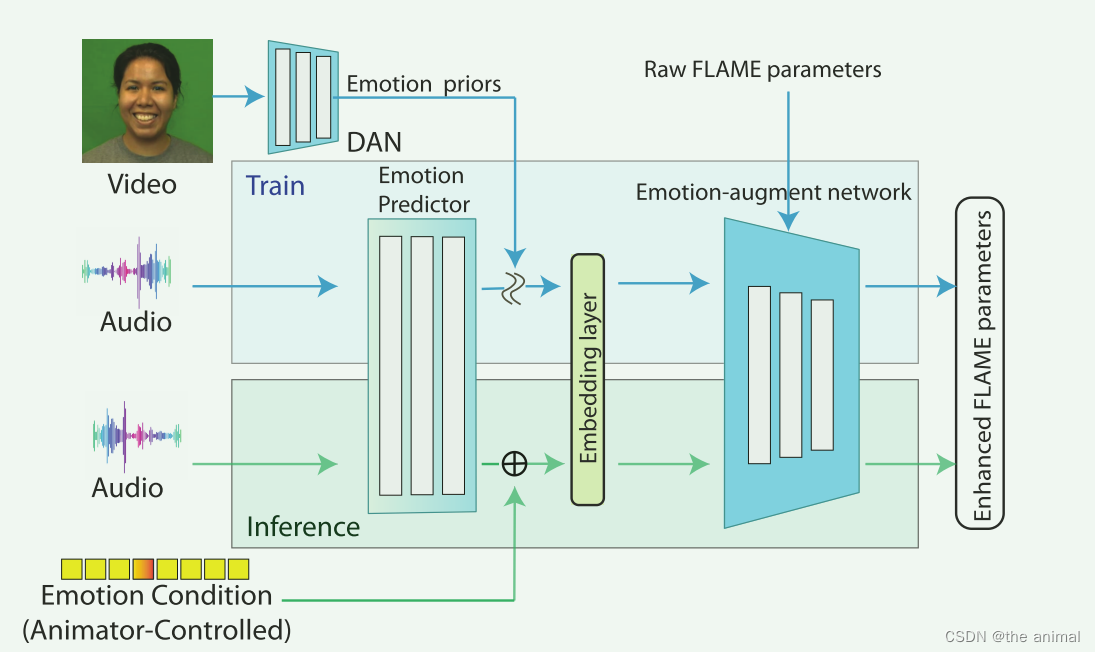
论文总结:EXPRESSIVE SPEECH-DRIVEN FACIAL ANIMATION WITH CONTROLLABLE EMOTIONS
存在的问题:现有的语音驱动面部动画方法可以产生令人满意的嘴部运动和嘴唇同步,但在情感表达和情感控制方面存在不足。 作者使用wav2vec2.0和transformer encoder来获取文本向量和全局风格向量。将其拼接起来通过Auido2FLAME模块来预测flame的参数,Auido2FLAME由多层CNN组成。在此阶段,将主要关注嘴唇同步,并确保嘴部运动的精确性。引入了一个情感控制模块,其