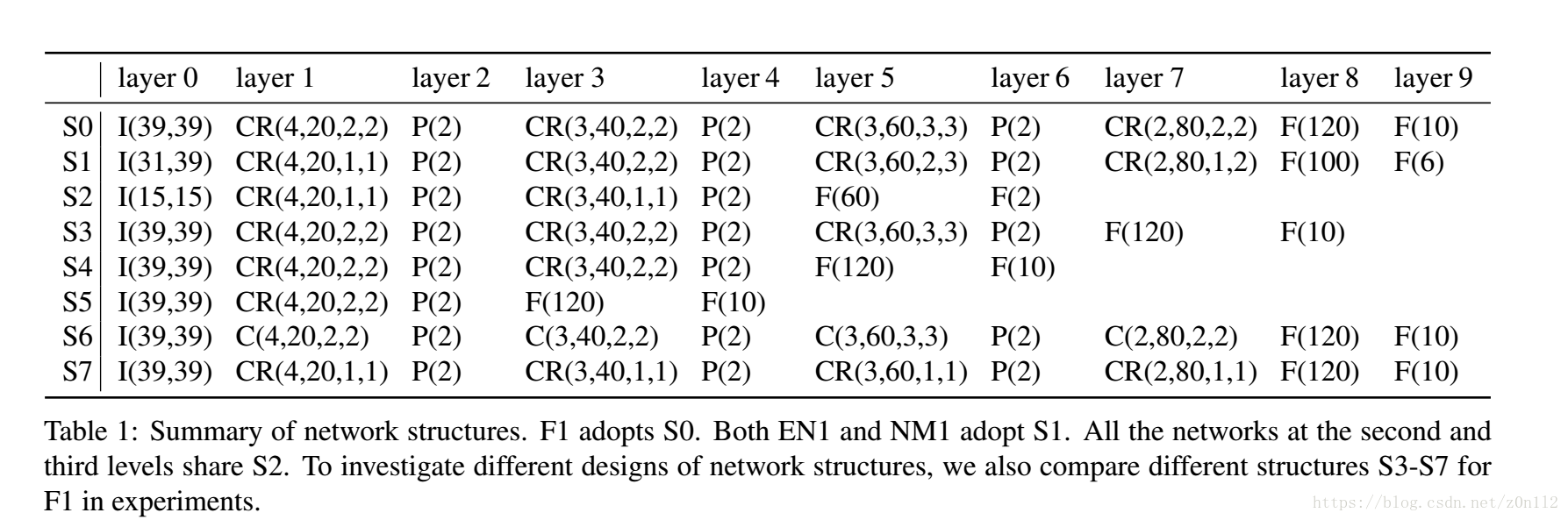
本文主要是介绍Invarient facial recongnition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
for later~
代码阅读
1. 加载trainset
import argparse
import logging
import os
import numpy as npimport torch
from torch import distributed
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom backbones import get_model
from dataset import get_dataloader
from face_fc_ddp import FC_ddp
from utils.utils_callbacks import CallBackLogging, CallBackVerification
from utils.utils_config import get_config
from utils.utils_distributed_sampler import setup_seed
from utils.utils_logging import AverageMeter, init_loggingfrom utils.utils_invreg import env_loss_ce_ddp, assign_loss
from utils.utils_feature_saving import concat_feat, extract_feat_per_gpu
from utils.utils_partition import load_past_partitionassert torch.__version__ >= "1.9.0", "In order to enjoy the features of the new torch, \
we have upgraded the torch to 1.9.0. torch before than 1.9.0 may not work in the future."import datetimeos.environ["NCCL_BLOCKING_WAIT"] = "1"try:world_size = int(os.environ["WORLD_SIZE"])rank = int(os.environ["RANK"])distributed.init_process_group("nccl", timeout=datetime.timedelta(hours=3))
except KeyError:world_size = 1rank = 0distributed.init_process_group(backend="nccl",init_method="tcp://127.0.0.1:12584",rank=rank,world_size=world_size,)def main(args):cfg = get_config(args.config)setup_seed(seed=cfg.seed, cuda_deterministic=False)torch.cuda.set_device(args.local_rank)os.makedirs(cfg.output, exist_ok=True)init_logging(rank, cfg.output)summary_writer = (SummaryWriter(log_dir=os.path.join(cfg.output, "tensorboard"))if rank == 0else None)##################### Trainset definition ###################### only horizon-flip is used in transformstrain_loader = get_dataloader(cfg.rec,args.local_rank,cfg.batch_size,False,cfg.seed,cfg.num_workers,return_idx=True)
3. 定义backbone model,加载权重,并行化训练
##################### Model backbone definition #####################backbone = get_model(cfg.network, dropout=cfg.dropout, fp16=cfg.fp16, num_features=cfg.embedding_size).cuda()if cfg.resume:if rank == 0:dict_checkpoint = torch.load(os.path.join(cfg.pretrained, f"checkpoint_{cfg.pretrained_ep}.pt"))backbone.load_state_dict(dict_checkpoint["state_dict_backbone"])del dict_checkpointbackbone = torch.nn.parallel.DistributedDataParallel(module=backbone, broadcast_buffers=False, device_ids=[args.local_rank], bucket_cap_mb=16,find_unused_parameters=True)backbone.train()backbone._set_static_graph()
4. 分类函数+损失定义
##################### FC classification & loss definition ######################if cfg.invreg['irm_train'] == 'var':reduction = 'none'else:reduction = 'mean'module_fc = FC_ddp(cfg.embedding_size, cfg.num_classes, scale=cfg.scale,margin=cfg.cifp['m'], mode=cfg.cifp['mode'], use_cifp=cfg.cifp['use_cifp'],reduction=reduction).cuda()if cfg.resume:if rank == 0:dict_checkpoint = torch.load(os.path.join(cfg.pretrained, f"checkpoint_{cfg.pretrained_ep}.pt"))module_fc.load_state_dict(dict_checkpoint["state_dict_softmax_fc"])del dict_checkpointmodule_fc = torch.nn.parallel.DistributedDataParallel(module_fc, device_ids=[args.local_rank])module_fc.train().cuda()opt = torch.optim.SGD(params=[{"params": backbone.parameters()}, {"params": module_fc.parameters()}],lr=cfg.lr, momentum=0.9, weight_decay=cfg.weight_decay)##################### Train scheduler definition #####################cfg.total_batch_size = cfg.batch_size * world_sizecfg.num_image = len(train_loader.dataset)n_cls = cfg.num_classescfg.warmup_step = cfg.num_image // cfg.total_batch_size * cfg.warmup_epochcfg.total_step = cfg.num_image // cfg.total_batch_size * cfg.num_epochassert cfg.scheduler == 'step'from torch.optim.lr_scheduler import MultiStepLRlr_scheduler = MultiStepLR(optimizer=opt,milestones=cfg.step,gamma=0.1,last_epoch=-1)start_epoch = 0global_step = 0if cfg.resume:dict_checkpoint = torch.load(os.path.join(cfg.pretrained, f"checkpoint_{cfg.pretrained_ep}.pt"),map_location={'cuda:0': f'cuda:{rank}'})start_epoch = dict_checkpoint["epoch"]global_step = dict_checkpoint["global_step"]opt.load_state_dict(dict_checkpoint["state_optimizer"])del dict_checkpoint
- dict_checkpoint是 检查点的信息,用字典存储
5. 评估定义
##################### Evaluation definition #####################callback_verification = CallBackVerification(val_targets=cfg.val_targets, rec_prefix=cfg.val_rec, summary_writer=summary_writer)callback_logging = CallBackLogging(frequent=cfg.frequent,total_step=cfg.total_step,batch_size=cfg.batch_size,start_step=global_step,writer=summary_writer)loss_am = AverageMeter()amp = torch.cuda.amp.grad_scaler.GradScaler(growth_interval=100)updated_split_all = []for key, value in cfg.items():num_space = 25 - len(key)logging.info(": " + key + " " * num_space + str(value))loss_weight_irm_init = cfg.invreg['loss_weight_irm']
6. 训练迭代
##################### Training iterations #####################if cfg.resume:callback_verification(global_step, backbone)for epoch in range(start_epoch, cfg.num_epoch):if cfg.invreg['loss_weight_irm_anneal'] and cfg.invreg['loss_weight_irm'] > 0:cfg.invreg['loss_weight_irm'] = loss_weight_irm_init * (1 + 0.09) ** (epoch - 5)if epoch in cfg.invreg['stage'] and cfg.invreg['loss_weight_irm'] > 0:cfg.invreg['env_num'] = cfg.invreg['env_num_lst'][cfg.invreg['stage'].index(epoch)]save_dir = os.path.join(cfg.output, 'saved_feat', 'epoch_{}'.format(epoch))if os.path.exists(os.path.join(save_dir, 'final_partition.npy')):logging.info('Loading the past partition...')updated_split_all = load_past_partition(cfg, epoch)logging.info(f'Total {len(updated_split_all)} partition are loaded...')else:if os.path.exists(os.path.join(save_dir, 'feature.npy')):logging.info('Loading the pre-saved features...')else:# extract features for each gpuextract_feat_per_gpu(backbone, cfg, args, save_dir)if rank == 0:_, _ = concat_feat(cfg.num_image, world_size, save_dir)distributed.barrier()emb = np.load(os.path.join(save_dir, 'feature.npy'))lab = np.load(os.path.join(save_dir, 'label.npy'))# conduct partition learninglogging.info('Started partition learning...')from utils.utils_partition import update_partitionupdated_split = update_partition(cfg, save_dir, n_cls, emb, lab, summary_writer,backbone.device, rank, world_size)del emb, labdistributed.barrier()updated_split_all.append(updated_split)if isinstance(train_loader, DataLoader):train_loader.sampler.set_epoch(epoch)for _, (index, img, local_labels) in enumerate(train_loader):global_step += 1local_embeddings = backbone(img)# cross-entropy lossif cfg.invreg['irm_train'] == 'var':loss_ce_tensor, acc = module_fc(local_embeddings, local_labels, return_logits=False)loss_ce = loss_ce_tensor.mean()loss = loss_ceelif cfg.invreg['irm_train'] == 'grad':loss_ce, acc, logits = module_fc(local_embeddings, local_labels, return_logits=True)loss = loss_ce# IRM lossif len(updated_split_all) > 0:if cfg.invreg['irm_train'] == 'grad':loss_irm = env_loss_ce_ddp(logits, local_labels, world_size, cfg, updated_split_all, epoch)elif cfg.invreg['irm_train'] == 'var':import dist_all_gatherloss_total_lst = dist_all_gather.all_gather(loss_ce_tensor)label_total_lst = dist_all_gather.all_gather(local_labels)loss_total = torch.cat(loss_total_lst, dim=0)label_total = torch.cat(label_total_lst, dim=0)loss_irm_lst = []for updated_split in updated_split_all:n_env = updated_split.size(-1)loss_env_lst = []for env_idx in range(n_env):loss_env = assign_loss(loss_total, label_total, updated_split, env_idx)loss_env_lst.append(loss_env.mean())loss_irm_lst.append(torch.stack(loss_env_lst).var())loss_irm = sum(loss_irm_lst) / len(updated_split_all)else:print('Please check the IRM train mode')loss += loss_irm * cfg.invreg['loss_weight_irm']if rank == 0:callback_logging.writer.add_scalar(tag='Loss CE', scalar_value=loss_ce.item(),global_step=global_step)if len(updated_split_all) > 0:callback_logging.writer.add_scalar(tag='Loss IRM', scalar_value=loss_irm.item(),global_step=global_step)if cfg.fp16:amp.scale(loss).backward()amp.unscale_(opt)torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)amp.step(opt)amp.update()else:loss.backward()torch.nn.utils.clip_grad_norm_(backbone.parameters(), 5)opt.step()opt.zero_grad()if cfg.step[0] > cfg.num_epoch:# use global iteration as the stepslr_scheduler.step(global_step)else:lr_scheduler.step(epoch=epoch)with torch.no_grad():loss_am.update(loss.item(), 1)callback_logging(global_step, loss_am, epoch, cfg.fp16, lr_scheduler.get_last_lr()[0], amp, acc)if global_step % cfg.verbose == 0 and global_step > 0:callback_verification(global_step, backbone)if rank == 0:path_module = os.path.join(cfg.output, f"model_{epoch}.pt")torch.save(backbone.module.state_dict(), path_module)if cfg.save_all_states:checkpoint = {"epoch": epoch + 1,"global_step": global_step,"state_dict_backbone": backbone.module.state_dict(),"state_dict_softmax_fc": module_fc.module.state_dict(),"state_optimizer": opt.state_dict(),"state_lr_scheduler": lr_scheduler.state_dict()}torch.save(checkpoint, os.path.join(cfg.output, f"checkpoint_{epoch}.pt"))callback_verification(global_step, backbone)if rank == 0:path_module = os.path.join(cfg.output, f"model_{epoch}.pt")torch.save(backbone.module.state_dict(), path_module)# convert model and save itfrom torch2onnx import convert_onnxconvert_onnx(backbone.module.cpu().eval(), path_module, os.path.join(cfg.output, "model.onnx"))distributed.destroy_process_group()
Run it with “main” f
if __name__ == "__main__":torch.backends.cudnn.benchmark = Trueparser = argparse.ArgumentParser(description="Distributed Training of InvReg in Pytorch")parser.add_argument("config", type=str, help="py config file")parser.add_argument("--local_rank", type=int, default=0, help="local_rank")main(parser.parse_args())
这篇关于Invarient facial recongnition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!