本文主要是介绍Deep Convolutional Network Cascade for Facial Point Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CVPR2013的一篇文献,利用CNN做人脸特征点定位. 为了进一步加深对mxnet的理解,准备做轮子.
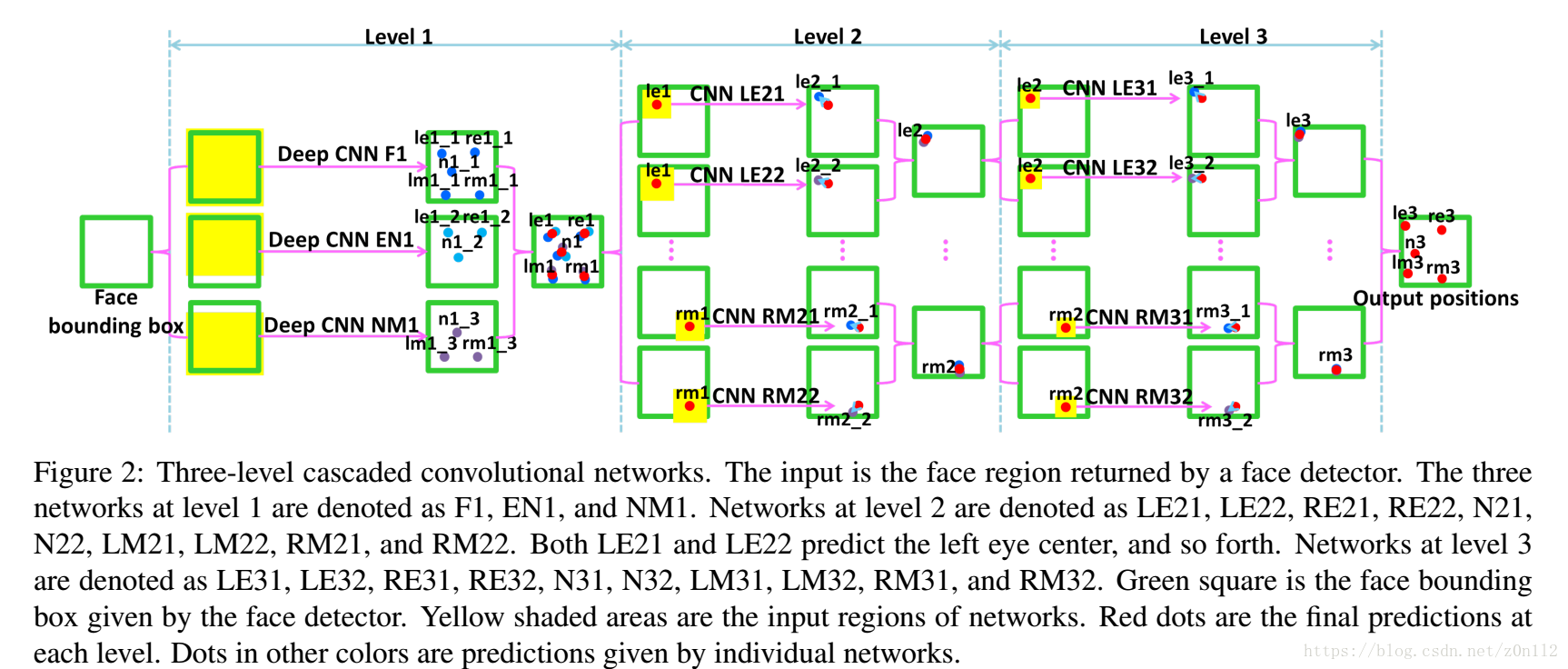
上图是完整的架构图,包括Level 1, level 2, level 3 三级网络组成, 逐渐提高定位精度.
Level 1
这一级由三个子网络组成,其中
* F1: 输入整个人脸区域,输出lefteye,righteye,nose,leftmouth,rightmouth共5个特征点坐标(10维)
* EN1: 输入人脸上部区域(不包括mouth),输入lefteye,righteye,nose共3个特征点坐标
* NM1: 输入人脸下部区域(不包括eye),输出nose,leftmouth,rightmouth共3个特征点坐标
三个网络的输出取平均值作为Level 1的最终输出. Level中的网络结构一样,如下图所示
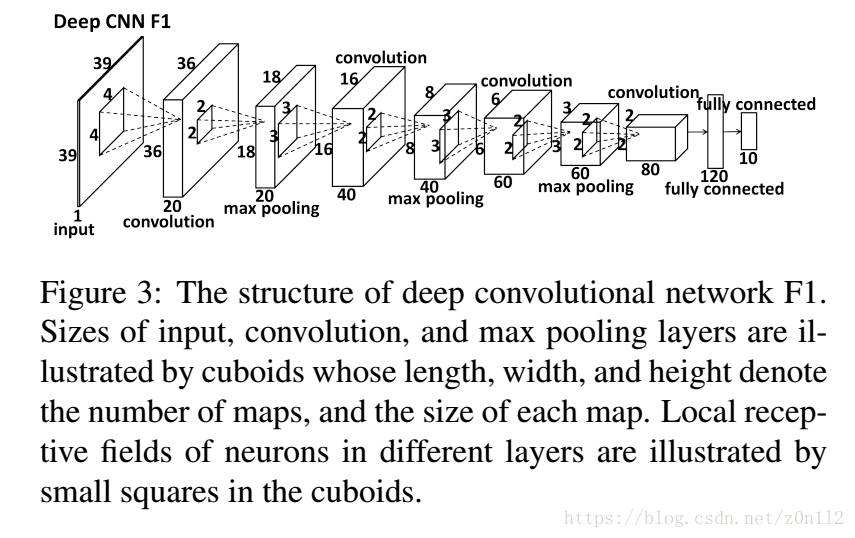
当然三个网络输入的尺寸可能不一致
local feature vs global feature
为什么选择三个不同区域对同一个目标做训练?
一般图像识别中,如果一个简单特征出现在一处,我们假设它会出现在其他地方,具有某种意义,所以整张图送入CNN学习有用的全局特征.但是这种假设对于布局固定的目标就不再合适了,比如眼睛和嘴巴. 嘴巴和眼睛对应的简单特征很相似, 但复杂特征差异很大,把他们隔离开有助于让低层次的网络学习到的简单特征,对目标更具有针对性,有利于高级特征的学习优化. 文中的EN1和NM1鼓励网络学习local feature,而不是鼓励学习global feature.
Level 2
Level 2由10个子网络组成,输入特征点的邻域区域,输出邻域中心相对特征点的偏移量. 10个自网络,两两一组,负责对一个特征点的精定位,比如LE21和LE22是计算lefteye的偏移量. 一组内的两个子网络的区别是视野区域不同,比如
LE21截取的区域的尺寸是人脸框的0.16,而LE22截取的区域的尺寸是人脸框尺寸的0.18.
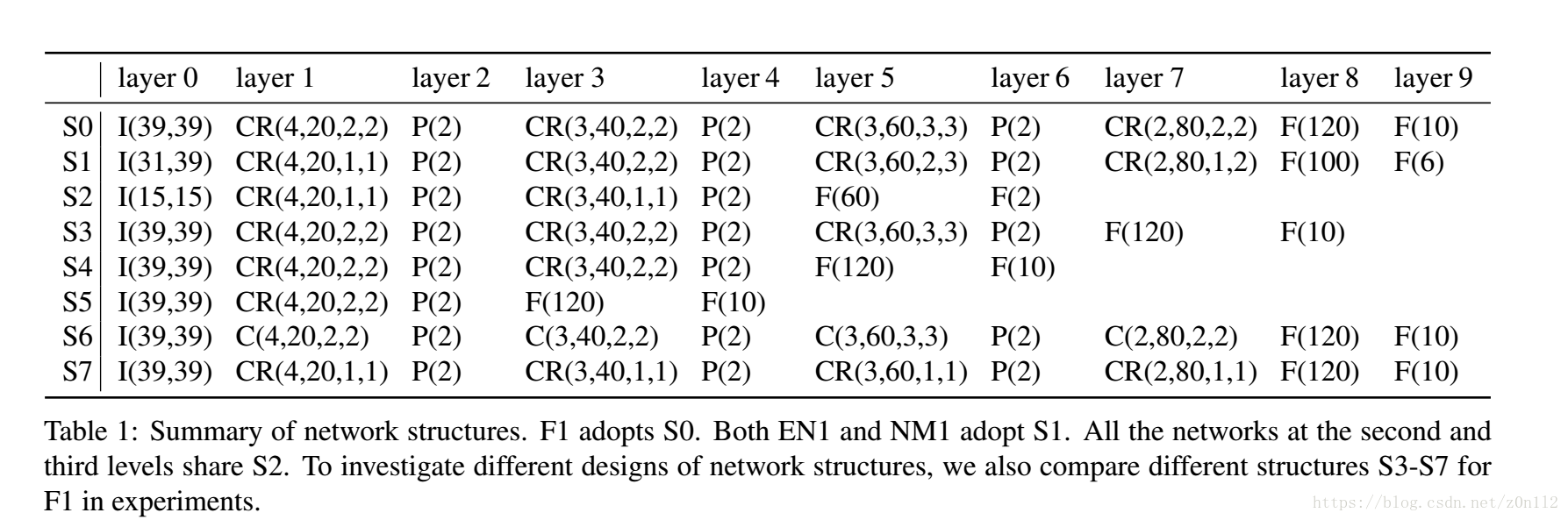
由于输入尺寸差异很大, Level 2的子网络采用了新的网络结构,即上表的S2.
absolute value rectification
文中采用的激励函数是tanh,而特殊的是tanh之后取ABS(),文中称之为absolute value rectification.
上表中的CR(4,20,1,1)就是这种带abs()的卷积层+tanh激励函数,4表示kernel size, 20是特征图个数,
(1,1)的含义没看明白….
Level 3
Level 3 和 Level 2很相似, 最大的区别是每个网路输入的视野区域更加小了. 另外level 2 和 level 3训练中需要加入在线的translation,实验中发现这个translation的范围对结果有显著影响,不易过大, 如果人脸框是64,
那么加入的translation范围[-3,3]即可,过大可能导致精度降低
codes
https://github.com/z01nl1o02/DCNN-for-facial-landmark-detection
这篇关于Deep Convolutional Network Cascade for Facial Point Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!