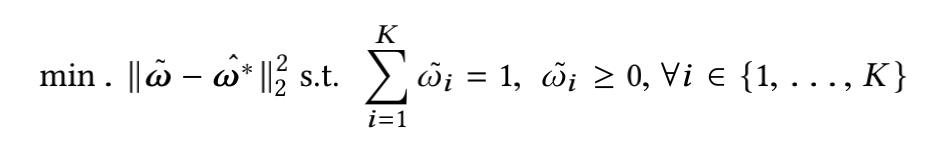本文主要是介绍多任务——Facial Landmark,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 《Facial Landmark Detection by Deep Multi-task Learning》2014
**要解决的问题:**人脸关键点的检测
**创新点:**在人脸关键点检测的同时进行多个任务的学习,包括:性别,是否带眼镜,是否微笑和脸部的姿势。使用这些辅助的属性可以更好的帮助定位关键点。这种Multi-task learning的困难在于:不同的任务有不同的特点,不同的收敛速度。针对这两个问题,文章给出前者的解决办法是tasks-constrained deep model,对后者解决办法是task-wise early stopping。文章中的方法在处理有遮挡和姿势变化时表现较好,而且模型比较简单。
网络结构:
实验中,作者对不同的辅助任务跟主任务人脸关键点检测进行不同形式的组合,证明了辅助任务对于关键点检测的准确性有提高作用。

1)tasks-constrained deep model
传统的多任务学习把每个任务都赋予相同的权重,损失函数就是不同任务的损失函数直接相加。而在人脸特征点检测的任务中,不同的任务具有不同的loss,特征点检测是平方和误差,而其它分类任务是交叉熵误差,在训练时,各个任务使用相同的特征,只有在最后一级
才根据任务的不同做不同的处理(分类或者回归)。不同的任务设置不同的权重参数。
2)Task-wise early stopping
针对多任务学习的特点,作者提出了一种新的early stopping方法。当辅助任务达到最好表现以后,这个任务就对主要任务没有帮助了,就可以停止这个任务。难点在于什么时候进行停止,更多的是根据经验来判断,作者的着重点在于关键点的检测,部分的牺牲了辅助任务的性能。
注:博众家之所长,集群英之荟萃。

这篇关于多任务——Facial Landmark的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!