landmark专题

深入RAG优化:BGE词嵌入全解析与Landmark Embedding新突破
前面已经写过一篇关于Embedding选型的文章,《如何高效选择RAG的中文Embedding模型?揭秘最佳实践与关键标准!》,主要介绍通过开源网站的下载量和测评效果选择Embedding模型。 一、Embedding选型建议与结果 选型建议: 1、大部分模型的序列长度是 512 tokens。8192 可尝试 tao-8k,1024 可尝试 stella。 2、在专业数据领域上,嵌入

图像修复_LaFIn_Generative Landmark Guided Face Inpainting
Abstract 提出了一个深度学习策略来修复人脸图像,这个网络由两个部分组成,一个是人脸关键点预测子网络,该网络的目的是给另一个网络提供人脸的结构信息(破损人脸图像的人脸拓扑信息,表情信息)。另一个是图像修复网络,该网络的目的是修复出符合真实外观的人脸图像。该人脸图像修复方法在数据集CelebA-HQ和CelebA上进行了实验。 Introduction 人脸图像相比较海洋、草地等自然

Facial Landmark Detection
转自:http://www.cnblogs.com/lanye/p/5310090.html 源地址:http://www.learnopencv.com/facial-landmark-detection/#comment-2471797375 OCTOBER 18, 2015 BY SATYA MALLICK 51 COMMENTS Facial landmark de

多任务——Facial Landmark
《Facial Landmark Detection by Deep Multi-task Learning》2014 **要解决的问题:**人脸关键点的检测 **创新点:**在人脸关键点检测的同时进行多个任务的学习,包括:性别,是否带眼镜,是否微笑和脸部的姿势。使用这些辅助的属性可以更好的帮助定位关键点。这种Multi-task learning的困难在于:不同的任务有不同的特点,不同的收敛速
facial landmark datection-数据集
人脸特征点数据集,主要包括:性别,是否带眼睛,是否微笑和脸部姿势。 Facial landmark detection of face alignment has long been impeded by the problems of occlusion and pose variation. Instead of treating the detection task as a single

基于landmark的音频指纹(Matlab实现)
Landmark简介 Landmark原义为里程碑的一些,这里引申为关键点。landmark用于音频指纹的介绍参考这篇文章:点击打开链接 Landmark提取步骤 下面介绍一下具体的实现步骤: 1.时域分帧,分帧长度,窗类型,重叠长度都可以自己设定 2.对每一帧进行fft变化,然后求其能量 3.求局部最大值的值和坐标,这个可以参考我的这篇文章:点击打开链接

人脸识别领域 landmark_2d_106,landmark_23d_64,embedding 特征
1. 人脸识别领域 landmark_2d_106 在人脸识别领域,landmark_2d_106是指对人脸的106个关键点进行的二维标定。这些关键点通常包括眼睛、眉毛、鼻子、嘴唇等部位的位置。通过准确地识别和定位这些关键点,可以帮助系统更准确地识别人脸并进行人脸属性分析、情绪分析等任务。 2. 人脸识别领域 landmark_3d_64 在人脸识别领域,landmark_3d_64是指对人脸的6
Landmark Drillworks r5000.0.1-ISO
300\ Surpac学习教材.zip Agilent.89600.Vector.Signal.Analyzer.v8.0-ISO 1CD\ Aquaveo GMS Premium10.05 64位 高级版地下水模拟+培训资料Aquaveo Groundwater Modeling System(GMS) v10.0.5 Premium Win64 1CD\ ArtiCAD.Pr
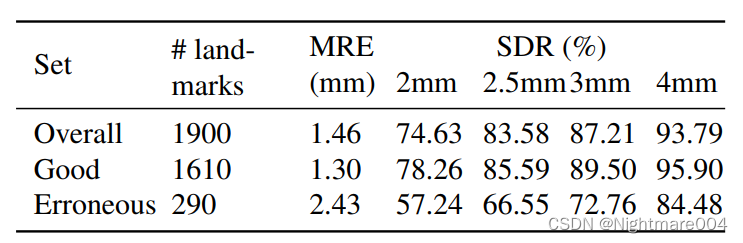
Contour-Hugging Heatmaps for Landmark Detection阅读笔记
代码:https://github.com/jfm15/ContourHuggingHeatmaps 我自己稍微改了一点的https://github.com/Nightmare4214/ContourHuggingHeatmaps 摘要 希望输出landmark的位置和每个landmark的不确定度(Uncertainty) 作者主要贡献: 作者通过分类的方式来训练模型通过temper
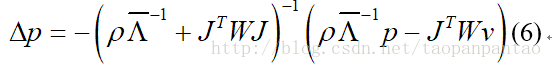
【翻译】Convolutional Experts Network for Facial Landmark Detection
【翻译】Convolutional Experts Network for Facial Landmark Detection 摘要: 约束局部模型(CLM)是一个成熟的面部标记点检测方法系列。然而他们最近不如 级联回归 方法流行。这部分是由于现有CLM局部检测器无法对表情,照明,面部毛发,化妆等影响的非常复杂的标记点外观进行建模。我们提出了一种新颖的局部检测器 - 卷积专家网络(CEN),它将
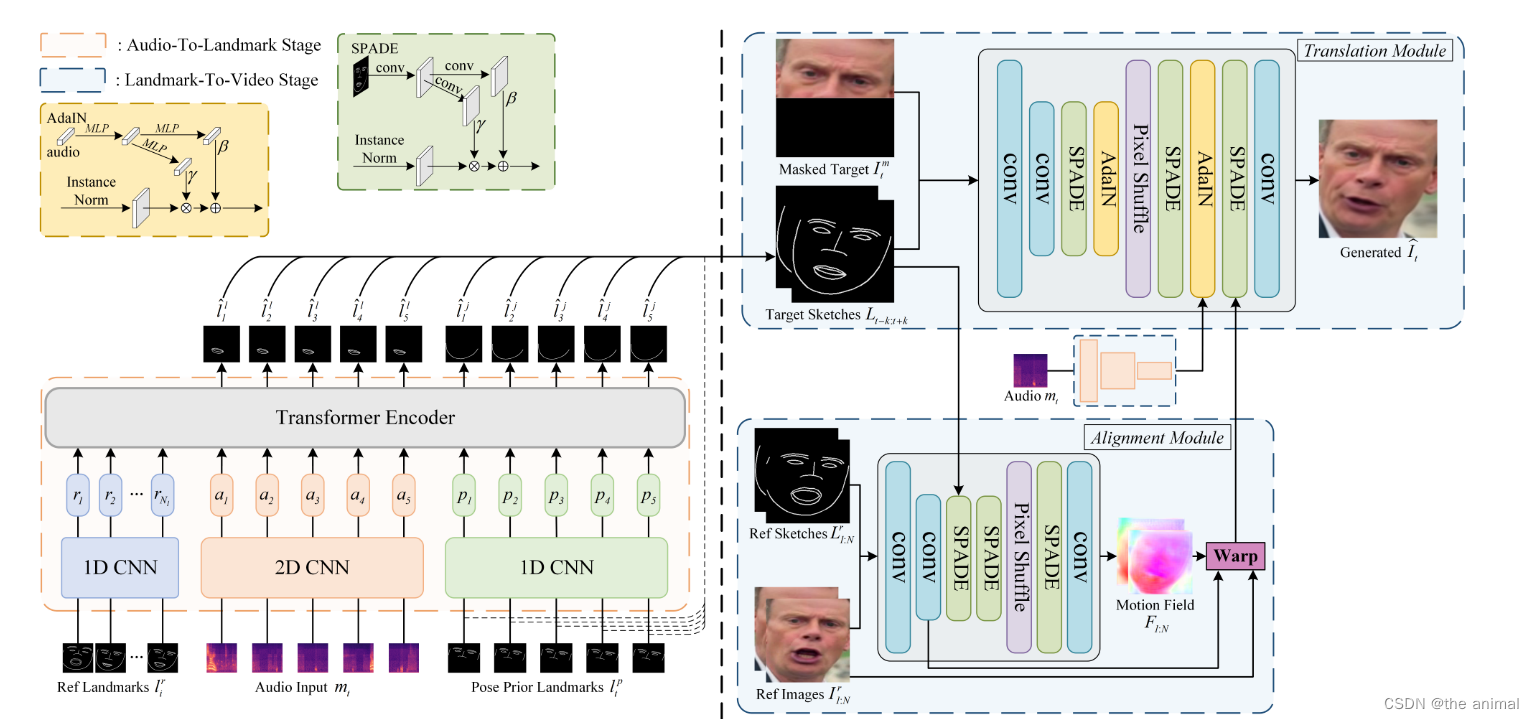
Identity-Preserving Talking Face Generation with Landmark and Appearance Priors
主要问题:1)模型如何生成具有与输入音频一致的面部运动(特别是嘴部和下颌运动)的视频?2)模型如何在保留身份信息的同时生成视觉上逼真的帧? 摘要: 从音频生成说话脸部视频引起了广泛的研究兴趣。一些特定个人的方法可以生成生动的视频,但需要使用目标说话者的视频进行训练或微调。现有的通用方法在生成逼真和与嘴唇同步的视频同时保留身份信息方面存在困难。为了解决这个问题,我们提出了一个两阶段的框架,包括从音频

通过场景landmark做定位的新思路(CVPR 2022)
点击进入—>3D视觉工坊学习交流群 Learning to Detect Scene Landmarks for Camera Localization(论文阅读笔记) 2022 CVPR 微软与明尼苏达大学联合研究 项目地址和代码:https://github.com/microsoft/SceneLandmarkLocalization. 主要内容: 提出了一种基于学习的相机定位算法,其无需