本文主要是介绍AI语音机器人:通过 Azure Speech 实现类人类的交互,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语音对话的重要性
在竞争日益激烈的客户互动领域,人工智能语音对话正成为重中之重。随着数字参与者的崛起,组织认识到语音机器人的强大力量,它是一种自然而直观的沟通方式,可以提供类似人类的体验,深度吸引用户,并让他们从竞争对手中脱颖而出。无缝客户服务、个性化协助和即时信息访问的需求推动了对高质量语音交互的需求不断增长。此外,随着公司努力保留和扩大收入,跨越语言障碍接触更多样化的客户群变得至关重要,这使得多语言和情境感知语音解决方案成为当今市场的关键差异化因素。
参考链接:
微软Azure AI 语音服务、OpenAI 免费试用申请

创建有效语音机器人解决方案的关键挑战
尽管潜力巨大,但创建真正引起用户共鸣的语音机器人解决方案仍充满挑战。很少有组织能够成功解决阻碍最先进语音机器人发展的关键障碍:
- 延迟:确保语音交互实时进行,没有明显的延迟,对于保持自然对话至关重要。高延迟会扰乱对话流程,导致用户沮丧和参与度下降。
- 准确性:准确的语音识别至关重要,尤其是在嘈杂的环境中或用户口音和方言各异的情况下。对口语的误解会导致错误的响应和沟通中断。
- 成本效益:组织面临的挑战是创建一个能够平衡高级功能与成本效益运营的架构,从而努力看到投资的回报。
- 个性化、人性化的对话:用户希望语音机器人能够理解上下文、表现出同理心并提供个性化和可理解的响应。要实现这种级别的交互,需要从当今的众多选项中仔细选择合适的 LLM,并实现自定义语音功能以增强对话体验。
通过下一代语音机器人实现类似人类的交互
在以下部分中,我们将探讨如何使用 Azure AI 功能解决这些核心挑战,使企业能够提供超出客户期望的下一代语音体验。以下是一个快速演示,利用 Azure AI Stack 中的一些功能来展示语音机器人参与促销销售对话:
提高准确性
适用于不同场景的自定义语音模型
Azure 自定义语音服务使企业能够利用特定领域的词汇、发音指南和定制的声学环境来微调自动语音识别 (ASR) 以满足特定需求。这些自定义功能可提高语音识别准确性并改善各种用例中的用户体验。
自定义语音模型的关键功能
- 处理噪音和声学变化:自定义语音模型可以经过训练,在嘈杂的环境和不同的声学条件下(例如繁忙的街道、公共场所或免下车通道)保持准确性。通过使用数据增强技术(例如将干净的音频与背景噪音混合),模型可以针对各种音景变得稳健。
- 领域特定词汇:提高对行业特定术语和技术术语的识别能力。自定义语音可以准确处理医疗保健、法律和金融等领域的专业语言,确保正确转录涉及复杂术语的对话。示例:在技术演示或客户支持电话中准确识别专业的科学术语或产品名称。
- 自定义发音:定制模型以识别非标准发音和独特术语,例如品牌名称或方言,确保准确转录口语。
- 口音和语言支持:调整模型以识别各种口音和方言,增强全球可访问性和用户参与度。
- 增强的输出格式:定义特定的文本格式规则,例如数字规范化和亵渎过滤,以满足清晰度和适当性的行业标准。
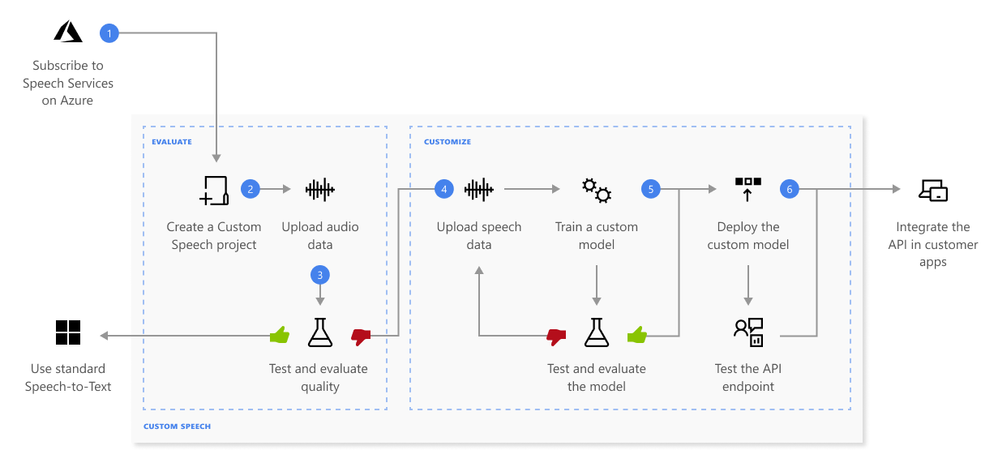
使用案例
- 教育:学术讲座期间提供准确的实时字幕。
- 医疗保健:可靠的医疗咨询记录。
- 客户支持:提高呼叫中心处理不同口音的准确性。
- 媒体:在现场直播中准确报道姓名和地点。
行动号召:利用 Azure 自定义语音增强语音应用程序。解决噪音、复杂术语和口音等挑战,提供无缝、引人入胜的用户体验。
参考链接:
自定义语音概述 - 语音服务 - Azure AI 服务 | Microsoft Learn
语音工作室 - 自定义语音 - 概述 (microsoft.com)
自定义模型微调的样本训练数据
https://docs.nvidia.com/deeplearning/riva/user-guide/docs/tutorials/asr-noise-augmentation-offline.h...
个人声音创作
自定义 AI 语音
Azure AI 文本转语音功能 使开发人员能够将文本转换为类似人类的合成语音。神经 TTS 是一种文本转语音系统,它使用深度神经网络使计算机的声音与人类的录音几乎无法区分。它提供类似人类的自然韵律和清晰的单词发音,这大大减少了与 AI 系统交互时的听力疲劳。借助 Azure 个人语音功能,用户可以创建自定义的 AI 语音,以复制他们自己或特定的角色。通过提供简短的语音样本,您可以生成一个独特的语音模型,该模型能够合成 100 多个地区 90 多种语言的语音。此功能对于个性化虚拟助手等应用程序特别有益,通过使用观众熟悉且可理解的声音来增强用户参与度和互动性。创建后,个人语音可以在应用程序中使用 ssml:
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript"><span style="color:#00e0e0">if</span> blnPersonalVoice<span style="color:#fefefe">:</span>speaker_profile_id <span style="color:#00e0e0">=</span> <span style="color:#abe338">"e04805d2-b81c-48ed-ac6b-1fa099edf0f3"</span>ssml <span style="color:#00e0e0">=</span> <span style="color:#abe338">"<speak version='1.0' xml:lang='hi-IN' xmlns='http://www.w3.org/2001/10/synthesis' "</span> \<span style="color:#abe338">"xmlns:mstts='http://www.w3.org/2001/mstts'>"</span> \<span style="color:#abe338">"<voice name='DragonLatestNeural'>"</span> \<span style="color:#abe338">"<mstts:ttsembedding speakerProfileId='%s'/>"</span> \<span style="color:#abe338">"<mstts:express-as style='cheerful' styledegree='5'>"</span> \<span style="color:#abe338">"<lang xml:lang='%s'> %s </lang>"</span> \<span style="color:#abe338">"</mstts:express-as>"</span> \<span style="color:#abe338">"</voice></speak> "</span> % <span style="color:#fefefe">(</span>speaker_profile_id<span style="color:#fefefe">,</span> locale<span style="color:#fefefe">,</span> <span style="color:#abe338">text</span><span style="color:#fefefe">)</span>result_future <span style="color:#00e0e0">=</span> synthesizer.speak_ssml_async<span style="color:#fefefe">(</span>ssml<span style="color:#fefefe">)</span><span style="color:#00e0e0">else</span><span style="color:#fefefe">:</span>result_future <span style="color:#00e0e0">=</span> synthesizer.speak_text_async<span style="color:#fefefe">(</span><span style="color:#abe338">text</span><span style="color:#fefefe">)</span>result <span style="color:#00e0e0">=</span> await loop.run_in_executor<span style="color:#fefefe">(</span>None<span style="color:#fefefe">,</span> result_future.<span style="color:#00e0e0">get</span><span style="color:#fefefe">)</span></code></span></span>
号召行动:探索如何在您的应用程序中实现个性化语音功能,以增强用户体验和参与度!
参考链接:
What is personal voice? - Azure AI services | Microsoft Learn
认知服务语音-sdk/samples/custom-voice at master · Azure-Samples/cognitive-services-speech...
使用语音合成标记语言 (SSML) 实现语音和声音 - 语音服务 - Azure AI 服务 | ...
通过实时音频合成实现低延迟
为了实现无缝、低延迟的语音交互,利用 Azure Speech SDK 和 OpenAI 的流式传输功能进行实时音频合成至关重要。通过以小块形式处理响应并在每个块准备就绪后立即合成音频,您可以提供流畅的对话体验。
来自 Azure OpenAI 的流响应
首先从 OpenAI 实时流式传输文本响应:
- 流响应:使用 OpenAI 的流式传输功能接收生成的部分文本响应。
- 缓冲和过程:积累文本直到检测到完整的想法(以标点符号表示),然后开始合成。
<span style="color:#333333"><span style="background-color:#ffffff"><span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">completion <span style="color:#00e0e0">=</span> client.chat.completions.create<span style="color:#fefefe">(</span>model<span style="color:#00e0e0">=</span>open_ai_deployment_name<span style="color:#fefefe">,</span> messages<span style="color:#00e0e0">=</span>message_text<span style="color:#fefefe">,</span> stream<span style="color:#00e0e0">=</span>True<span style="color:#fefefe">)</span>async def process_stream<span style="color:#fefefe">(</span><span style="color:#fefefe">)</span><span style="color:#fefefe">:</span>text_buffer <span style="color:#00e0e0">=</span> <span style="color:#abe338">""</span><span style="color:#00e0e0">for</span> event <span style="color:#00e0e0">in</span> completion<span style="color:#fefefe">:</span><span style="color:#00e0e0">if</span> choice <span style="color:#fefefe">:</span><span style="color:#00e0e0">=</span> event.choices[<span style="color:#00e0e0">0</span>].delta.content<span style="color:#fefefe">:</span>text_buffer <span style="color:#00e0e0">+</span><span style="color:#00e0e0">=</span> choice<span style="color:#00e0e0">if</span> any<span style="color:#fefefe">(</span>p <span style="color:#00e0e0">in</span> text_buffer <span style="color:#00e0e0">for</span> p <span style="color:#00e0e0">in</span> <span style="color:#abe338">",;.!?"</span><span style="color:#fefefe">)</span><span style="color:#fefefe">:</span>await text_to_speech_streaming<span style="color:#fefefe">(</span>text_buffer.strip<span style="color:#fefefe">(</span><span style="color:#fefefe">)</span><span style="color:#fefefe">)</span>text_buffer <span style="color:#00e0e0">=</span> <span style="color:#abe338">""</span> <span style="color:#d4d0ab"># Clear buffer</span>
</code></span></span></span></span>使用推送模型设置音频输出
使用推送模型,在合成音频数据后立即进行流式传输:
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript"><span style="color:#d4d0ab"># Custom class to handle pushed audio data</span>
<span style="color:#abe338">class</span> CustomPushAudioStream<span style="color:#fefefe">(</span>PushAudioOutputStreamCallback<span style="color:#fefefe">)</span><span style="color:#fefefe">:</span>def write<span style="color:#fefefe">(</span>self<span style="color:#fefefe">,</span> audio_buffer<span style="color:#fefefe">:</span> memoryview<span style="color:#fefefe">)</span> <span style="color:#00e0e0">-</span><span style="color:#00e0e0">></span> int<span style="color:#fefefe">:</span><span style="color:#d4d0ab"># Handle the received audio data (e.g., play it, save it)</span>print<span style="color:#fefefe">(</span>f<span style="color:#abe338">"Received audio buffer of size: {len(audio_buffer)}"</span><span style="color:#fefefe">)</span><span style="color:#00e0e0">return</span> len<span style="color:#fefefe">(</span>audio_buffer<span style="color:#fefefe">)</span><span style="color:#d4d0ab"># Create a global SpeechSynthesizer with custom push stream</span>
push_stream <span style="color:#00e0e0">=</span> CustomPushAudioStream<span style="color:#fefefe">(</span><span style="color:#fefefe">)</span>
audio_config <span style="color:#00e0e0">=</span> AudioConfig<span style="color:#fefefe">(</span>stream<span style="color:#00e0e0">=</span>push_stream<span style="color:#fefefe">)</span>
synthesizer <span style="color:#00e0e0">=</span> SpeechSynthesizer<span style="color:#fefefe">(</span>speech_config<span style="color:#00e0e0">=</span>speech_config<span style="color:#fefefe">,</span> audio_config<span style="color:#00e0e0">=</span>audio_config<span style="color:#fefefe">)</span><span style="color:#d4d0ab"># Function to perform text-to-speech synthesis</span>
async def text_to_speech_streaming<span style="color:#fefefe">(</span><span style="color:#abe338">text</span><span style="color:#fefefe">)</span><span style="color:#fefefe">:</span>result <span style="color:#00e0e0">=</span> synthesizer.speak_text_async<span style="color:#fefefe">(</span><span style="color:#abe338">text</span><span style="color:#fefefe">)</span>.<span style="color:#00e0e0">get</span><span style="color:#fefefe">(</span><span style="color:#fefefe">)</span><span style="color:#00e0e0">if</span> result.reason <span style="color:#00e0e0">=</span><span style="color:#00e0e0">=</span> ResultReason.SynthesizingAudioCompleted<span style="color:#fefefe">:</span>print<span style="color:#fefefe">(</span>f<span style="color:#abe338">"Synthesis complete for: {text}"</span><span style="color:#fefefe">)</span>elif result.reason <span style="color:#00e0e0">=</span><span style="color:#00e0e0">=</span> ResultReason.Canceled<span style="color:#fefefe">:</span>print<span style="color:#fefefe">(</span><span style="color:#abe338">"Synthesis canceled."</span><span style="color:#fefefe">)</span>
</code></span></span>
行动号召:通过首先流式传输来自 OpenAI 的响应,然后立即将音频输出推送到播放,您可以在语音交互中实现低延迟和高响应度。这种基于推送的流式传输方法非常适合实时动态对话,可确保自然且引人入胜的用户体验。
参考链接:
利用新的文本转语音功能让您的语音聊天机器人更具吸引力 (microsoft.com)
如何使用语音 SDK 降低语音合成延迟 - Azure AI 服务 | Microsoft Learn
用户体验提升
OpenAI 集成的智能提示
OpenAI 与 Azure AI Speech 的集成通过智能提示增强了用户体验,使交互更具吸引力和个性化。利用自然语言处理功能,这些系统可以理解上下文并实时生成相关响应,从而实现客户支持或虚拟助理场景中的无缝对话。此外,通过指示 OpenAI 包含标点符号,语音机器人可以利用流式传输功能生成具有适当停顿和语调的音频响应。这不仅使交互更加自然,而且还通过在合成过程中逐步播放音频来减少延迟,从而增强整体用户体验。
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript"><span style="color:#00e0e0">*</span><span style="color:#00e0e0">*</span>Conversation Protocol<span style="color:#00e0e0">*</span><span style="color:#00e0e0">*</span><span style="color:#00e0e0">1</span>. You converse <span style="color:#00e0e0">with</span> customer <span style="color:#00e0e0">in</span> simple<span style="color:#fefefe">,</span> short <span style="color:#fefefe">,</span> sentences.<span style="color:#00e0e0">2</span>. You use punctuations frequently <span style="color:#00e0e0">-</span> <span style="color:#fefefe">,</span>;.!?<span style="color:#00e0e0">3</span>. You generate <span style="color:#abe338">text</span> so <span style="color:#00e0e0">that</span> <span style="color:#00e0e0">in</span> <span style="color:#00e0e0">the</span> begining you have a small phrase ending <span style="color:#00e0e0">in</span> punctuations <span style="color:#fefefe">,</span>;.!?</code></span></span>
号召行动:了解如何将智能提示集成到您的应用程序中以提升客户互动并简化沟通流程!
通过实时语音转文本流实现低延迟
使用 Azure Speech SDK 进行实时语音转文本 (STT) 流式传输PushAudioInputStream可实现语音的即时转录,从而提供响应迅速且自然的用户体验。此方法非常适合需要快速反馈的场景,例如客户支持、实时转录和交互式语音系统。
主要优点
即时反馈:使用PushAudioInputStream实时 STT 可确保语音在说出后立即转录,保持对话的流畅性并增强整体用户体验。
<span style="background-color:#2b2b2b"><span style="color:#f8f8f2"><code class="language-applescript">
speech_config <span style="color:#00e0e0">=</span> speechsdk.SpeechConfig<span style="color:#fefefe">(</span>subscription<span style="color:#00e0e0">=</span>speech_key<span style="color:#fefefe">,</span> region<span style="color:#00e0e0">=</span>speech_region<span style="color:#fefefe">)</span><span style="color:#d4d0ab"># Create a push audio input stream and audio configuration</span>
stream <span style="color:#00e0e0">=</span> speechsdk.audio.PushAudioInputStream<span style="color:#fefefe">(</span><span style="color:#fefefe">)</span>
audio_config <span style="color:#00e0e0">=</span> speechsdk.audio.AudioConfig<span style="color:#fefefe">(</span>stream<span style="color:#00e0e0">=</span>stream<span style="color:#fefefe">)</span><span style="color:#d4d0ab"># Create the SpeechRecognizer with push stream input</span>
speech_recognizer <span style="color:#00e0e0">=</span> speechsdk.SpeechRecognizer<span style="color:#fefefe">(</span>language<span style="color:#00e0e0">=</span>lang<span style="color:#fefefe">,</span> speech_config<span style="color:#00e0e0">=</span>speech_config<span style="color:#fefefe">,</span> audio_config<span style="color:#00e0e0">=</span>audio_config<span style="color:#fefefe">)</span><span style="color:#d4d0ab"># Global list to store recognized text</span>
<span style="color:#abe338">text</span> <span style="color:#00e0e0">=</span> []<span style="color:#d4d0ab"># Callback function to handle recognized speech</span>
def handle_recognized<span style="color:#fefefe">(</span>evt<span style="color:#fefefe">)</span><span style="color:#fefefe">:</span><span style="color:#00e0e0">if</span> evt.result.reason <span style="color:#00e0e0">=</span><span style="color:#00e0e0">=</span> speechsdk.ResultReason.RecognizedSpeech<span style="color:#fefefe">:</span><span style="color:#abe338">text</span>.append<span style="color:#fefefe">(</span>evt.result.<span style="color:#abe338">text</span><span style="color:#fefefe">)</span>print<span style="color:#fefefe">(</span>f<span style="color:#abe338">"Recognized: {evt.result.text}"</span><span style="color:#fefefe">)</span><span style="color:#d4d0ab"># Connect the callback function to the recognized event</span>
speech_recognizer.recognized.connect<span style="color:#fefefe">(</span>handle_recognized<span style="color:#fefefe">)</span><span style="color:#d4d0ab"># Start continuous recognition</span>
speech_recognizer.start_continuous_recognition<span style="color:#fefefe">(</span><span style="color:#fefefe">)</span></code></span></span>
参考链接:
语音 SDK 音频输入流概念 - Azure AI 服务 | Microsoft Learn
采用流式架构的实时中断处理
在对话式 AI 中,妥善处理中断对于创建自然的对话流至关重要。借助流式架构,语音机器人可以实时检测并响应用户中断。通过在流式传输机器人响应的同时持续监控人类语音,系统可以在检测到用户讲话时立即停止播放。这可确保机器人不会继续打断用户说话,使交互更加自然,减少挫败感。利用 Azure Speech SDK 的实时功能,开发人员可以构建机器人,不仅可以在用户输入时停止 TTS 流,还可以准确管理对话上下文并无缝切换回聆听模式,从而增强整体用户体验。
号召行动:如何在语音机器人中实现实时中断处理可以创造更自然、响应更快的交互,从而提高用户满意度!
通过实时分类实现说话人识别
实时语音区分是一项强大的功能,可以区分音频流中的说话者,使系统能够识别和转录特定说话者的语音片段。此功能在会议或多参与者讨论等场景中特别有用,因为知道谁说了什么可以提高清晰度和理解力。通过采用单通道音频流,该技术可以准确识别不同的声音并将其与相应的对话关联起来,从而提供包含说话者标签的结构化转录输出。
行动号召:探索如何通过集成实时日记化来改善呼叫分析和增强客户互动,从而提升您的呼叫中心运营!
参考链接:
https://techcommunity.microsoft.com/t5/ai-azure-ai-services-blog/announcing-general-availability-of-...
多语言能力
自动语言检测和翻译
Azure 自动语言检测和翻译功能可实现实时翻译,无需用户指定输入语言,从而显著增强了用户交互。此功能允许应用程序无缝识别口语,从而促进多语言场景中的交流。语音翻译 API 可以在单个会话中处理多种语言,根据需要自动在它们之间切换,同时以文本或音频形式提供准确的翻译。此外,Azure AI 文本转语音提供 400 多种声音和 140 多种语言和区域设置。单个预构建的逼真神经语音具有 多语言 支持,可以轻松以同一种声音阅读多种语言的内容。
行动号召:了解如何通过整合自动语言检测和翻译来提升您在不同市场的客户互动!
参考链接:Announcing-video-translation-and-speech-translation-api
结论
Azure AI 创新助力成功之路
Azure AI Speech、Azure AI Speech 和 Azure Open AI 的创新为语音机器人领域的持续成功铺平了道路。
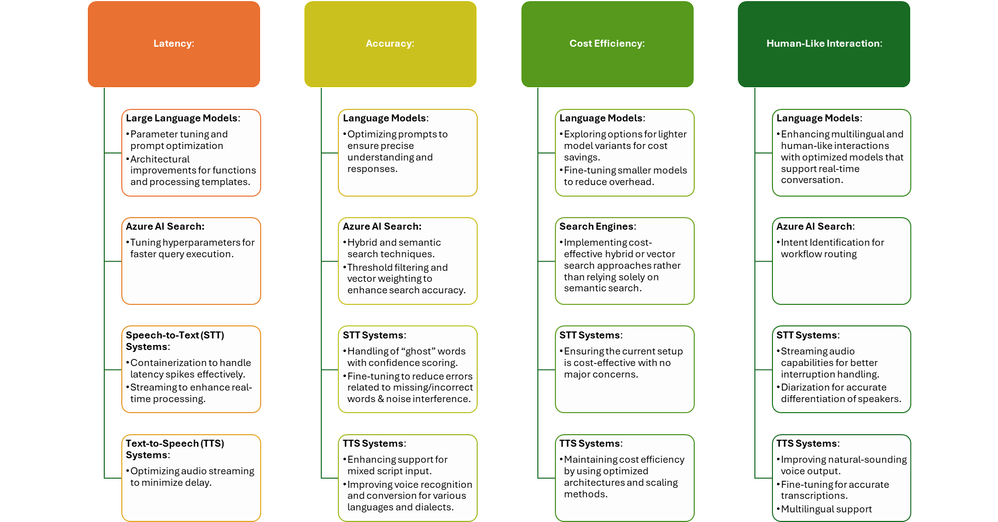
Azure 尖端技术为语音机器人开发中的关键挑战提供了全面的解决方案。凭借低延迟、高准确度、经济高效的扩展和类似人类的交互,Azure 使企业能够提供响应迅速且引人入胜的语音体验,满足并超越客户期望。通过利用这些功能,组织可以增强其沟通策略并推动有意义的用户参与。
这篇关于AI语音机器人:通过 Azure Speech 实现类人类的交互的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








