scaling专题

LLM的范式转移:RL带来新的 Scaling Law
从几周前 Sam Altman 在 X 上发布草莓照片开始,整个行业都在期待 OpenAI 发布新模型。根据 The information 的报道,Strawberry 就是之前的 Q-star,其合成数据的方法会大幅提升 LLM 的智能推理能力,尤其体现在数学解题、解字谜、代码生成等复杂推理任务。这个方法也会用在 GPT 系列的提升上,帮助 OpenAI 新一代 Orion。 OpenA

论文阅读1 Scaling Synthetic Data Creation with 1,000,000,000 Personas
Scaling Synthetic Data Creation with 1,000,000,000 Personas 链接:https://github.com/tencent-ailab/persona-hub/ 文章目录 Scaling Synthetic Data Creation with 1,000,000,000 Personas1. 摘要2. 背景2.1 什么是数据合成2

温度缩放temperature scaling,以及其在对抗性样本的隐私泄露中的作用
温度缩放是一种后处理技术,主要用于校准模型的预测置信度。具体来说,温度缩放可以调整模型输出的概率分布,使得这些概率更能准确反映模型的实际置信度。 温度缩放(Temperature Scaling)是一种用于校准机器学习模型输出置信度的后处理技术。它主要用于分类任务,特别是在神经网络模型中,以使得模型输出的概率更符合实际的置信水平。 背景 在分类任务中,神经网络模型通常会输出一组值,通过 so

Scaling SGD Batch Size to 32K for ImageNet Training
为了充分利用GPU计算,加快训练速度,通常采取的方法是增大batch size.然而增大batch size的同时,又要保证精度不下降,目前的state of the art 方法是等比例与batch size增加学习率,并采Sqrt Scaling Rule,Linear Scaling Rule,Warmup Schem等策略来更新学来率. 在训练过程中,通过控制学习率,便可以在训练的时候采
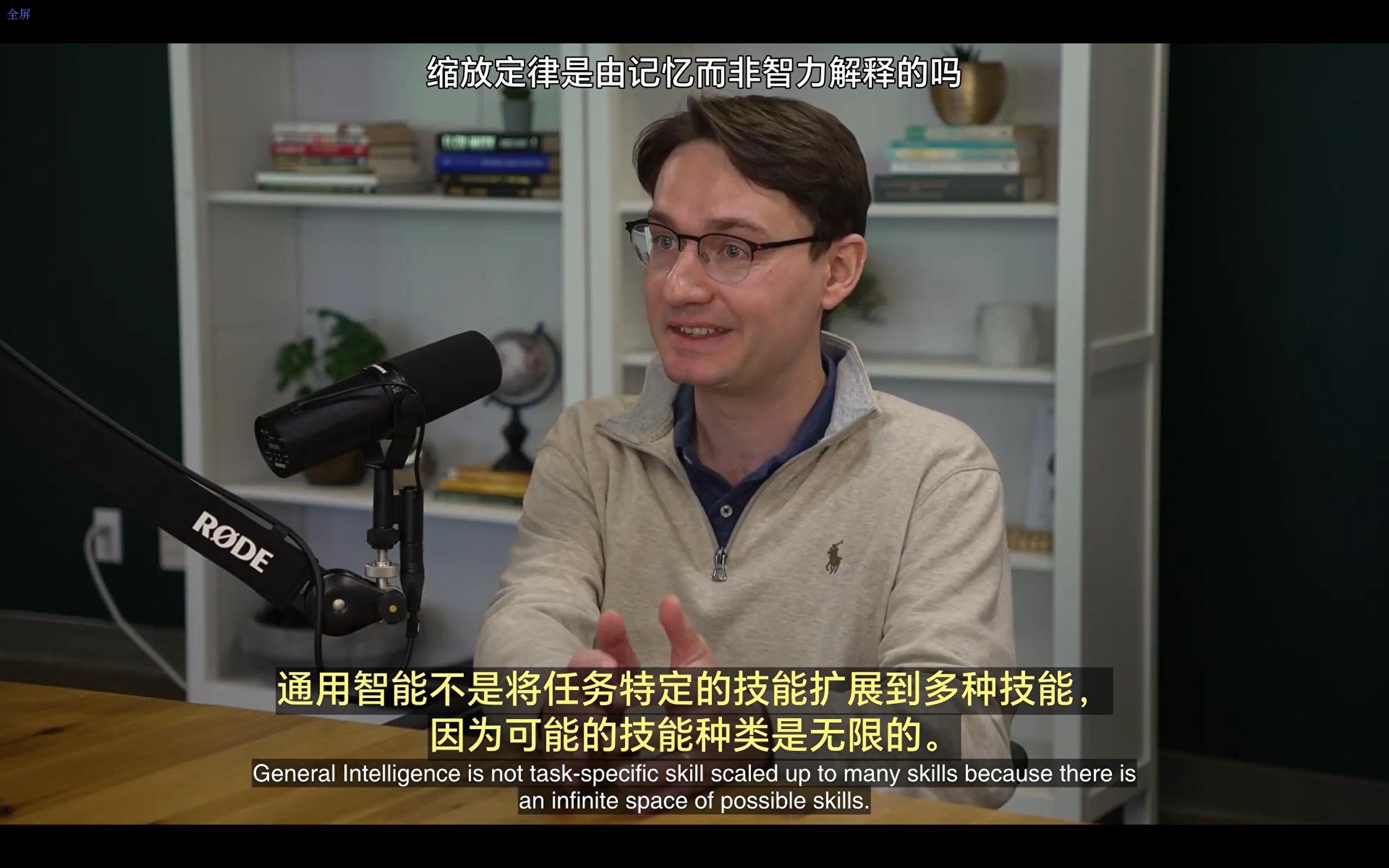
『大模型笔记』缩放定律(scaling laws)是由记忆而非智力解释的吗?
MAC 文章目录 一. 缩放定律(scaling laws)是由记忆而非智力解释的吗?1. 视频原文内容2. 要点总结一般智能的定义规模最大化的论点性能衡量的方式及其影响大语言模型的基准测试大语言模型的本质与记忆基准测试插值的概念与基准测试实例人类和模型的推理与样本效率 二. 参考文献 一. 缩放定律(scaling laws)是由记忆而非智力解释的吗? 1. 视频原文内
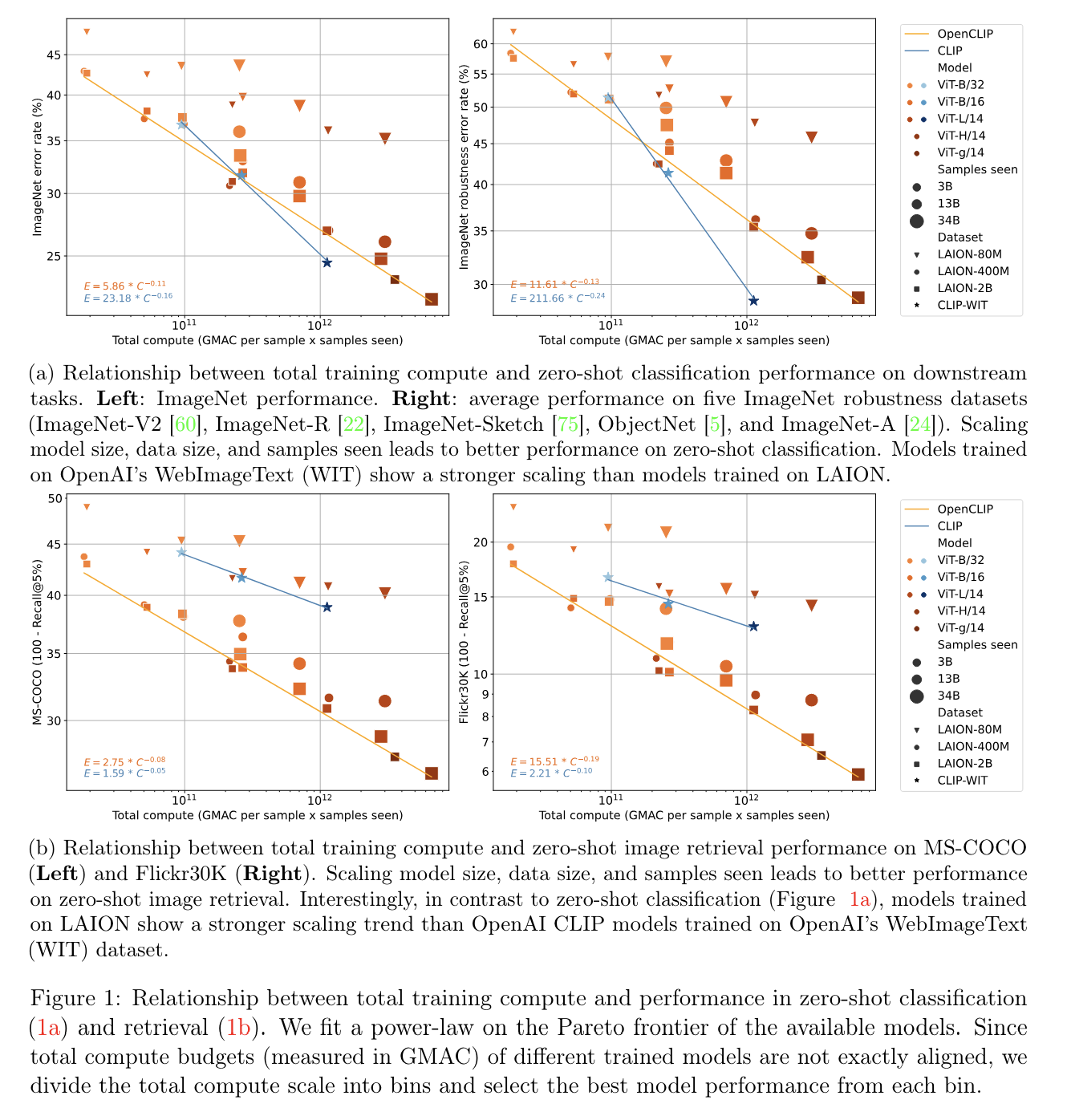
Reproducible scaling laws for contrastive language-image learning
这篇scaling laws横轴是GMAC per sample x samples seen,“GMAC” 是"Giga Multiply-Accumulate" 的缩写,这是计算机部件/系统所能执行的运算量的一种度量方式。一次 “multiply-accumulate” (乘累加) 操作包括一个乘法和一个累加操作。“Giga” 是表示10^9,也就是十亿的前缀。所以,一Giga MAC (GM
z score vs. min-max scaling 优缺点
Min-max:所有特征具有相同尺度 (scale) 但不能处理outlier z-score:与min-max相反,可以处理outlier, 但不能产生具有相同尺度的特征变换 More opinions (from researchgate): – If you have a PHYSICALLY NECESSARY MAXIMUM (like in the number of voters
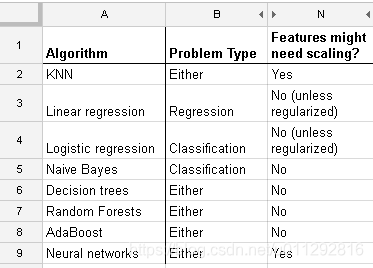
哪些机器学习算法需要进行特征缩放 - feature scaling
通常以距离或者相似度(例如标量积scaler product)作为计算量的算法: 例如KNN, SVM。 而基于概率图模型(graphical model)的算法:Fisher LDA ,Naive Bayes, Decision trees 和 Tree-based 集成方法 (RF, XGB)不会受到特征缩放的影响。 Reference: https://stats.stackexchang
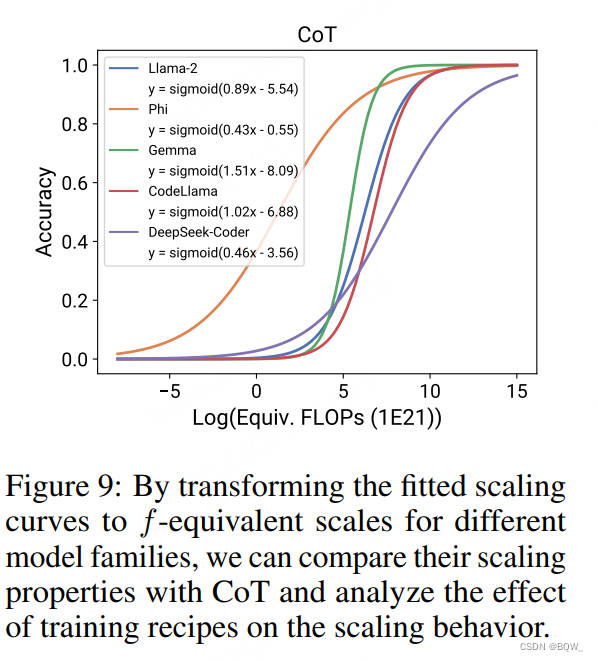
【自然语言处理】【Scaling Law】Observational Scaling Laws:跨不同模型构建Scaling Law
相关博客 【自然语言处理】【Scaling Law】Observational Scaling Laws:跨不同模型构建Scaling Law 【自然语言处理】【Scaling Law】语言模型物理学 第3.3部分:知识容量Scaling Laws 【自然语言处理】Transformer中的一种线性特征 【自然语言处理】【大模型】DeepSeek-V2论文解析 【自然语言处理】【大模型】BitN

Web agent 学习 2:TextSquare: Scaling up Text-Centric VisualInstruction Tuning
学习论文:TextSquare: Scaling up Text-Centric Visual Instruction Tuning(主要是学习构建数据集) 递归学习了:InternLM-XComposer2: Mastering Free-form Text-Image Composition and Comprehension in Vision-Language Large Models(
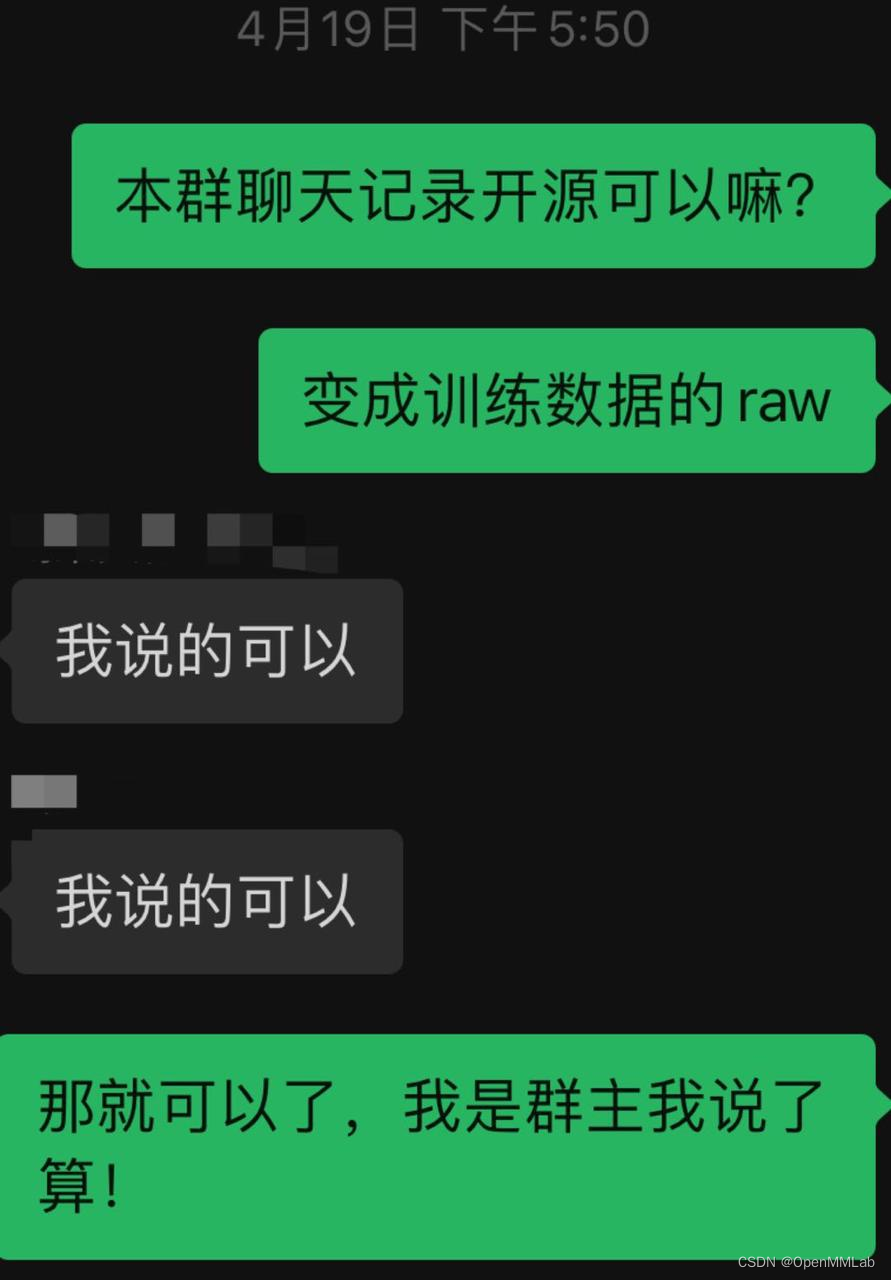
反着用scaling law验证数据:群聊场景指代消歧
本文作者:白牛 我们之前开源了 LLM 群聊助手茴香豆(以下简称豆哥),它的特点是: 设计了一套拒答 pipeline,实用于群聊场景。能够有效抵抗各种文本攻击、过滤无关话题,累计面对 openmmlab 数千用户运行半年( 17 个群、7w 条群消息)。这个过程确认了 text2vec 模型更适合反着用工业级开源。除算法 pipeline 外,还实现对应的 android、web ser
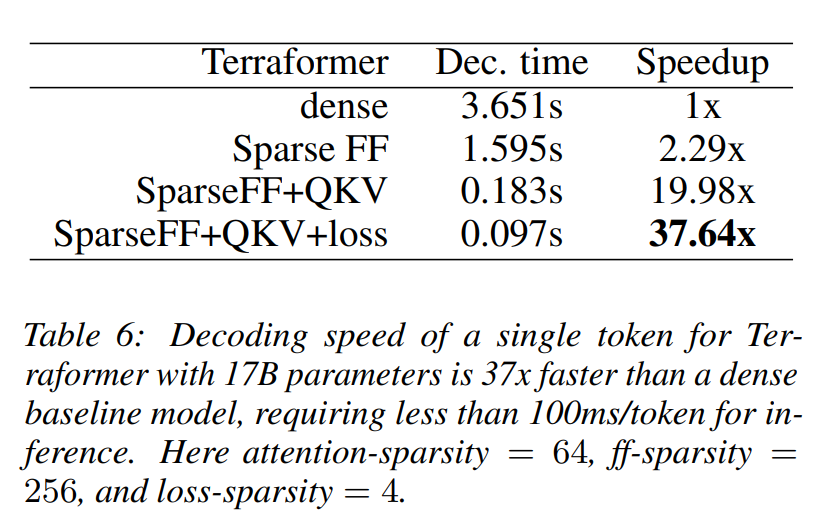
【论文阅读】Sparse is Enough in Scaling Transformers
Sparse is Enough in Scaling Transformers 论文地址摘要1 介绍2 相关工作模型压缩。模型修剪模型蒸馏。稀疏注意力。张量分解。稀疏前馈。 3 Sparse is Enough3.1 稀疏前馈层3.2 稀疏 QKV 层3.3 稀疏损失层。 4 长序列的稀疏性4.1 长序列架构4.2 内存效率的可逆性4.3 泛化的循环4.4 实验 5 结论 论

大语言模型从Scaling Laws到MoE
1、摩尔定律和伸缩法则 摩尔定律(Moore's law)是由英特尔(Intel)创始人之一戈登·摩尔提出的。其内容为:集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍;而经常被引用的“18个月”,则是由英特尔首席执行官大卫·豪斯(David House)提出:预计18个月会将芯片的性能提高一倍(即更多的晶体管使其更快),是一种以倍数增长的观测。[1] 然而,由于受到晶体管的散热问
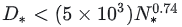
大语言模型中的第一性原理:Scaling laws
大语言模型的尺度定律在大语言模型的训练过程中起到了非常重要的作用。即使读者不参与大语言模型的训练过程,但了解大语言模型的尺度定律仍然是很重要的,因为它能帮助我们更好的理解未来大语言模型的发展路径。 1. 什么是尺度定律 尺度定律(Scaling laws)是一种描述系统随着规模的变化而发生的规律性变化的数学表达。这些规律通常表现为一些可测量的特征随着系统大小的增加而呈现出一种固定的比例关系。尺
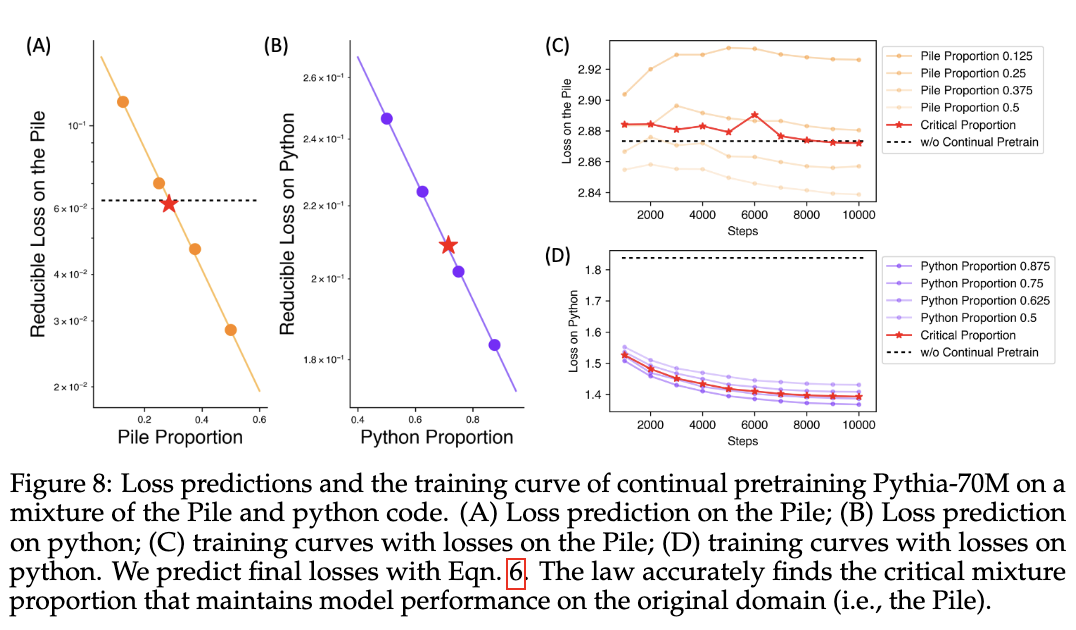
LLM漫谈(六)| 复旦MOSS提出数据配比scaling law
大型语言模型的预训练数据包括多个领域(例如,网络文本、学术论文、代码),其混合比例对结果模型的能力有着至关重要的影响。现有方法更多依赖于启发式或者定性策略来调整比例,MOSS团队提出了混合比例函数形式的定量预测方法,称为数据混合定律(data mixing laws)。 实验结果表明,该方法能够有效地优化RedPajama数据集上1B模型的训练混合比例,使其在100B个token的训练中
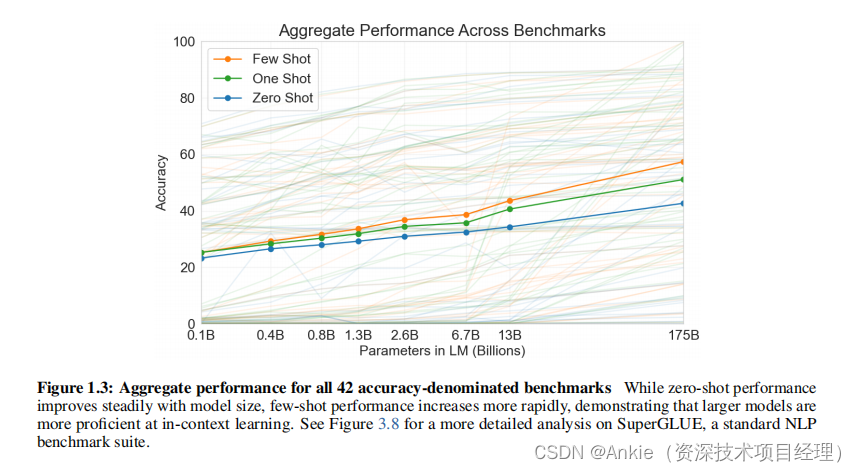
人工智能论文GPT-3(1):2020.5 Language Models are Few-Shot Learners;摘要;引言;scaling-law
摘要 近期的工作表明,在大量文本语料库上进行预训练,然后针对特定任务进行微调,可以在许多NLP任务和基准测试中取得实质性进展。虽然这种方法在架构上通常是与任务无关的,但仍然需要包含数千或数万示例的针对特定任务的微调数据集。相比之下,人类通常只需要几个示例或简单的说明就能执行新的语言任务——这是当前NLP系统仍难以做到的。在这里,我们展示了扩大语言模型规模可以极大地提高与任务无关、少量样本的性能,

图像入门处理4(How to get the scaling ratio between different kinds of images)
just prepare for images fusion and registration ! attachments for some people who need link1 图像处理入门 3
多尺度变换(Multidimensional Scaling ,MDS)详解
一、基本思想 MDS(Multidimensional Scaling ,MDS多维尺度变换)是一种经典的降维算法,其基本思想是通过保持数据点之间的距离关系,将高维数据映射到低维空间中。 具体来说,MDS算法的基本步骤如下: 1、构建距离矩阵:首先,我们需要计算原始空间中数据点之间的距离。常用的距离度量方法包括欧几里得距离、Minkowski距离等。通过计算每对数据点之间

告别微软,姜大昕带领这支精英团队攀登Scaling Law,万亿参数模型已有预览版
ChatGPT狂飙160天,世界已经不是之前的样子。 新建了人工智能中文站https://ai.weoknow.com 每天给大家更新可用的国内可用chatGPT资源 发布在https://it.weoknow.com 更多资源欢迎关注 攀登 Scaling Law,打造万亿参数大模型,前微软 NLP 大牛姜大昕披露创业路线图。 前段时间,OpenAI 科学家
Learn CUDA Programming第二章 scaling image例子报错 invalid argument
从Learn CUDA programming 的GitHub网站下载的例子在我的Ubuntu上运行会出现错误 Example Code如下: #include<stdio.h>#include"scrImagePgmPpmPackage.h"//Kernel which calculate the resized image__global__ void createResizedI
问题 B: Scaling Recipe
题目描述 You’ve got a recipe which specifies a number of ingredients, the amount of each ingredient you will need, and the number of portions it produces. But, the number of portions you need is not the
【分布式webscoket】IM聊天系统消息如何存储 如何分库分表以及Seata解决事务以及ShardingSphere-Scaling解决数据迁移
前言 在实现IM(即时通讯)聊天系统时,随着用户数量和消息量的增加,数据库的压力会逐渐增大。为了保证系统的可扩展性和性能,通常需要对聊天消息进行分库分表。以下是一些建议: 分表策略 按时间分表 优点:可以根据时间轴快速查询,旧数据归档处理也较为方便。 实现:每个时间周期(如每月、每周)创建一个新表,表名包含时间标识。 按用户分表 优点:可以将用户的消息分散到不同的表中,减少单表数据量,提高查询

Scaling Memcache at Facebook论文理解
原文地址:http://nil.csail.mit.edu/6.824/2020/papers/memcache-fb.pdf 体会 这篇论文读起来很有意思,设计体现了各方面的权衡,里面不仅考虑了分布式的CAP问题,也考虑到了计算机网络发包的机制和其他方面的内容,值得仔细品味。 读这篇文章的过程中也发现自己对于分布式体系概览不是很熟悉,RAFT和Memcache的应用范围划分不是很熟悉,另外
用于图像生成的Scaling Transformers
概述 Scaling Transformers 是一种用于图像生成的神经网络架构,它通过扩展传统的 Transformer 模型来处理大规模数据集和高分辨率图像。这种模型通过改进注意力机制和网络结构,提高了处理大型图像的效率和生成质量。 核心特点 改进的注意力机制:为了处理更大的图像,Scaling Transformers 对传统的自注意力(Self-Attention)机制进行了优化,减
Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning-笔记
通过Active Learning(AL)算法,找到最小的需要标注的数据进行训练,来标记未标记的数据。 AL必须满需下边的需求才能作为crowd-sourced database的默认的最优策略: Generality:算法必须能够应用到任意的分类和标记任务。因为crowd-sourced systems应用广泛。Black-box treatment of the classife

Bootstrap-Scaling Up Crowd-Sourcing to Very Large Datasets: A Case for Active Learning
论文Scaling Up Crowd-Sourcing to Very Large Datasets A Case for Active Learning对bootstrap做了介绍。 原书(B. Efron and R. J. Tibshirani. An Introduction to the Bootstrap. Chapman & Hall, 1993.)