本文主要是介绍LLM漫谈(六)| 复旦MOSS提出数据配比scaling law,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

大型语言模型的预训练数据包括多个领域(例如,网络文本、学术论文、代码),其混合比例对结果模型的能力有着至关重要的影响。现有方法更多依赖于启发式或者定性策略来调整比例,MOSS团队提出了混合比例函数形式的定量预测方法,称为数据混合定律(data mixing laws)。
实验结果表明,该方法能够有效地优化RedPajama数据集上1B模型的训练混合比例,使其在100B个token的训练中达到与默认混合比例训练多训48%step的性能。
此外,该方法还成功应用于持续预训练,准确预测了避免灾难性遗忘的关键混合比例,并展现了“动态数据调度”的潜力。
作者建议嵌套使用训练步骤、模型大小的scaling law和数据混合定律(data mixing laws),以便能够预测在各种混合条件下基于海量数据训练的大型模型的性能,而只需进行小规模训练。
一、背景
1.1 大模型预训练
大模型预训练是在大量无监督数据上使用自回归方式预测下一个token来学习的,loss通常使用对数似然函数,如下公式所示:
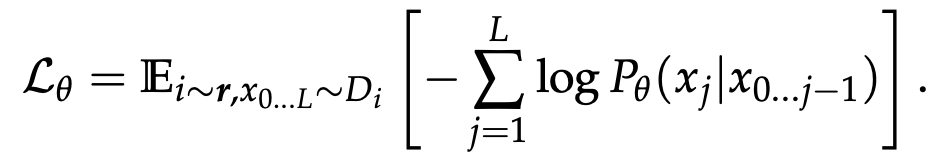
最终在验证集上评估大模型效果。
1.2 Scaling laws
scaling laws主要研究多种因素对大模型Loss的影响,公式如下:

这里x可以是模型大小、预训练数据大小、训练步数、计算量。
二、数据混合的比例以定量可预测的方式影响模型损失
为了发现数据混合规律,需要解决如下两个挑战:
(i)多变量:对于K个数据域的数据混合定律,混合比例有K−1个自由度,相应地,在目标函数中有K–1个变量。变量的增加使函数形式的识别变得复杂。
(ii)非单调性:损失和任何域的比例之间的单调关系表明,不平衡的混合可以实现最小损失,这与实践相矛盾。因此,与现有的损失随相关因素的规模单调递减的比例律不同,数据混合定律应该适应非单调性功能。
为了应对这些挑战,作者首先通过研究损失和混合比例之间的关系符合单变量单调函数的情况来简化问题,然后逐步增加多域数据分析。具体而言,开始只在两个域上进行训练,这样可以避免多变量复杂问题,并且只考虑来自其中一个训练域的验证数据,以避免非单调性(第2.1节)。随后,分析多个域的混合数据比例(第2.2节),探讨包括不同领域的一般验证数据的损失的可预测性(第2.3节)。
2.1 两域数据混合下域损失的初步研究
从最简单的情况开始探索,下面只研究两个域的混合,并分别在这两个域上评估模型。
a)实验设置
作者使用Pile数据集的Github和Pile CC子数据集训练70M和160M语言模型。两个数据集的混合比例设置为{0.25,0.375,0.5,0.625,0.75}。所有模型设置batch size为1M,训练30k步,总共30B个tokens,并在GitHub和Pile CC的验证集上评估不同步的检查点。
b)实验结论

# 实现代码如下:https://github.com/yegcjs/mixinglaws/blob/main/mix_2_domains.ipynb
图2揭示了给定域比例下域损失的定量可预测性。从图中可以发现,对于具有相同大小和用相同步骤数训练的检查点,在减去共享常数3后,它们在对数尺度上的域损失与域比例呈线性关系。结果表明,在其他因素不变的情况下,得到了这么一个函数可以拟合两个数据集的不同比例和loss的指数定律,公式如下所示:

2.2 扩展到在多域混合上训练的域损失
为了适应真实世界中两个以上领域的情况,作者将研究扩展到多个领域数据。为了简化视觉辅助,选择从三个领域的情况开始分析。
a)实验设置
作者选择Pile的GitHub、Pile CC和Books3三个子集,总共30B个tokens,并分别在三个域上评估模型。从{0,0.125,0.25,…,0.875,1}进行网格搜索,其中三个比例加起来为1,而且没有用完任何域中的所有令牌,最终产生了32种组合。
作者利用这些实验混合物的损失,通过猜想和验证来识别损失和混合物比例之间的函数形式。具体来说,对可能形式的猜想基于以下两个原则:
•兼容性:如果域的数目M=2,该形式可以简化为等式6。
•对称性:任何变量交换都不应改变函数形式。
第二个原则源于避免引入任何特定领域偏差的直觉。这两个原则共同导致了复 制方程中指数项的候选函数。每个训练领域都有 6 个,并通过遵守交换律的运 算将它们组合起来。
根据如上两个原则,作者实验了如下候选函数:

在三种数据域上的拟合错误,如下表1所示:
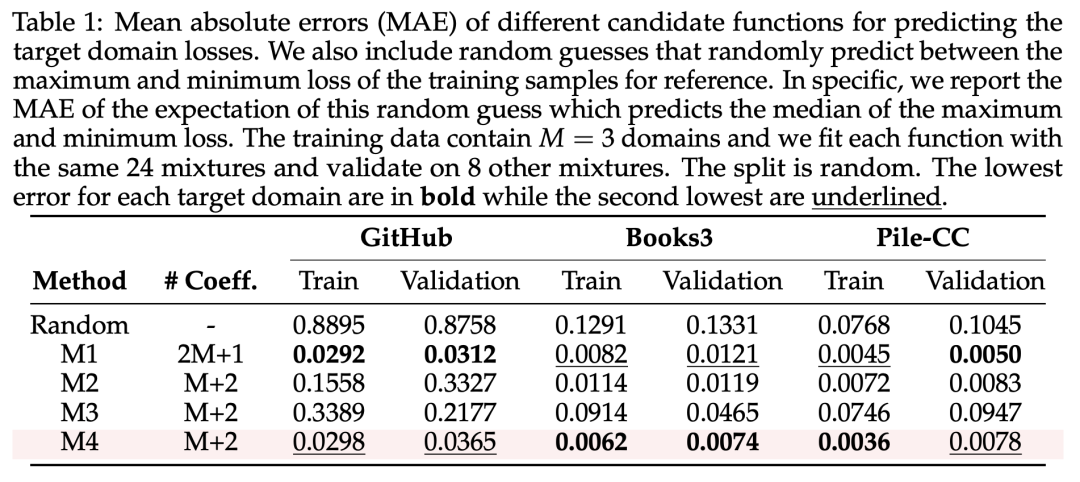
b)实验结论
从表1中的结果来看,M1和M4的预测比较可靠,而M4的系数较少,因此最后采用M4形式:
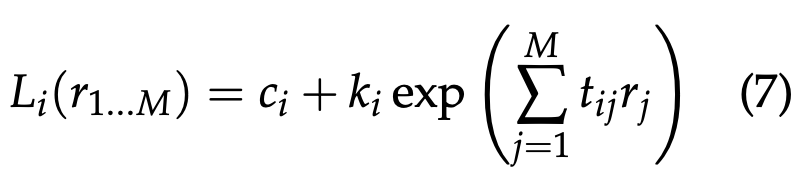
采用上述M4形式,拟合的结果如下所示:
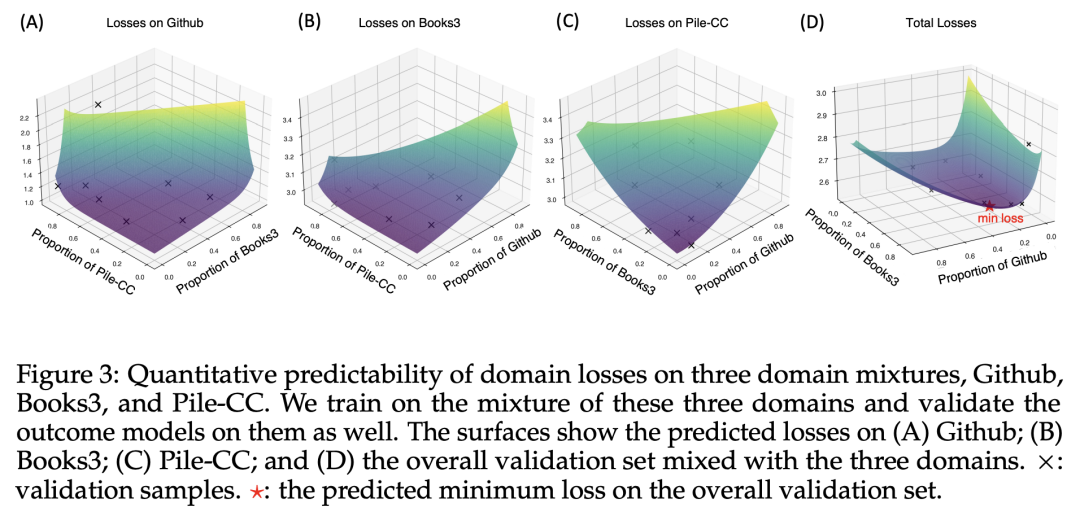

三、嵌套标度法则仅使用小规模实验预测在各种混合物上训练的损失
3.1 Loss预测的pipeline
虽然数据混合定律使我们能够在未见过的混合数据上预测训练模型的性能,但满足该定律的要求涉及跨不同混合物训练多个模型,并且模型大小和tokens计数与目标模型相同。此外,我们必须对每个目标模型大小和训练数据集重复此过程(一个想法是将使用少量标记训练的小型模型上的优化训练混合物转移到大型模型和大量训练数据的训练上。然而,在附录 A 中,我们表明,有关模型性能的数据混合的偏序会随着模型大小和训练标记数量的变化而变化。因此,实验规模的最佳混合物在目标规模上可能不是最佳的)。这导致成本非常高,从而阻碍了数据混合定律的实际使用。
是否可以在不进行大规模训练的情况下获得不同混合比例的损失呢?scaling law验证了训练步骤和模型大小的关系。特别是,OpenAI[3]仅用 1000×–10000×更少的计算量就预测了目标模型的损失。因此,我们可以在不同的混合物上用很少的训练步骤训练小模型,并对其拟合缩放法则来估计目标模 型大小的损失和目标训练步骤数。然后,我们可以使用预测的损失来拟合数据混合定律并搜索最佳混合。数据混合定律的管道如图 1 所示:

数据混合定律详细信息如下算法1所示:

3.2 实验
a)实验设置
作者在 RedPajama 的混合物上训练模型,并选择Pile为验证集,以模拟验证数据与训练数据分开收集的场景。为了适应训练步长和模型大小的缩放规律,作者为 30B tokens数据训练了一系列 70M、160M、305M 和 410M 模型。对于所有模型,将批量大小设置为 1M 令牌,从而转化为 1B 模型的 100k 步和小模型的 30k 步,并应用余弦学习率衰减,并进行 2k 步的预热,在第 100k 步时衰减到最大学习率的 0.1。
为了通过有限数量的实验运行达到较低的预测误差,作者利用混合比例项在数据混合定律中表示为指数函数的事实来选择用于实验的混合物。具体来说,通过从不耗尽所有域标记的最大可用域开始,通过双减每个训练域的比例来枚举候选混合物。这样,每个(隐式)验证域的损失就均匀分布。然后,从所有候选者中抽取 40 个混合物样本,并训练最小的 70M 模型。对其中的 20 个 混合物进行重新采样,以适应数据混合定律,并选择在所有 40 个样本上达到最小预测误差的组作为运行管道的最终混合物集。详细内容请参见附录B.2。
b)实验结果
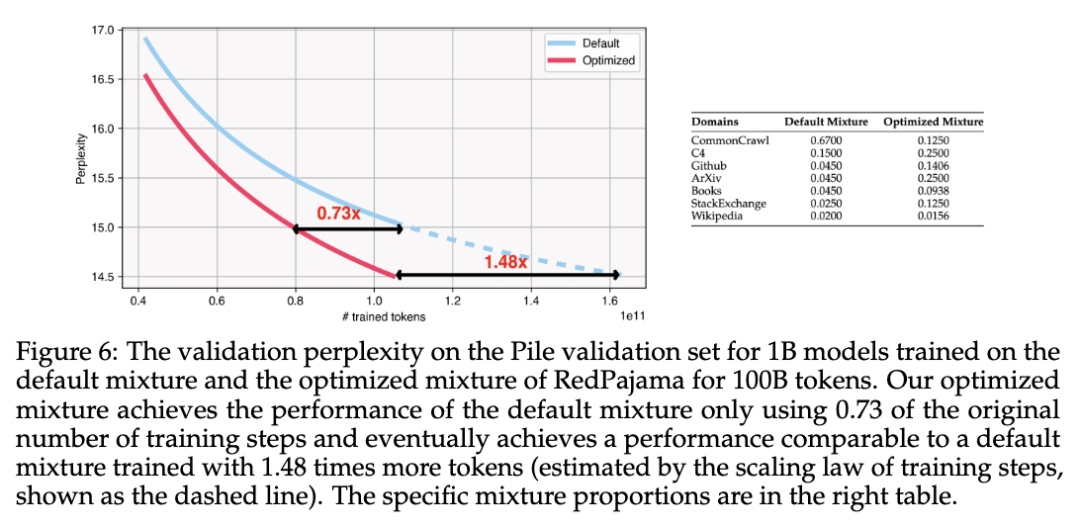
图 6 显示了使用RedPajama 默认混合物和从算法1获得的优化混合物及其在验证数据上的表现。损失预测如图7所示:

有如下发现:
- 管道有效优化性能:在优化混合物上训练的模型仅需要 73% 的步长即可达到与在 默认混合物上训练的模型相当的性能。如果使用默认混合进行训练,它最终会达到需要多 48% 步数的性能。这表明数据混合定律管道在混合物优化方面的有效性。
- 为模型能力的平衡提供参考的预测:图 7 中的预测结果证明了相对值的合理参考。
四、数据混合定律驱动的持续预训练 Outlook 数据计划的应用
持续预训练与预训练模型范式相同,但是模型参数是以预训练参数而不是随机初始化的。通常来说,持续预训练是增强现有预训练模型的常用技术,它将最新知识注入模型,避免由于分布变化而导致性能下降。此外,研究人员还应用持续预训练来重用现有模型参数来构建不同架构的模型。那么数据混合定律应用于在持续预训练会起作用吗?
作者对持续预训练的典型场景进行实验,在原始预训练数据和目标域数据的混合上训练模型。例如,使用 Pile 和 Python 代码的混合持续预训练 Pythia-70M 模型,其中前者是基础模型的原始预训练数据。为了验证数据混合法则是否适用于持续预训练,作者在 4 种混合物上训练 10B tokens的模型并使用Pile 和 python 代码数据通过等式6来拟合loss。结果如图8所示:
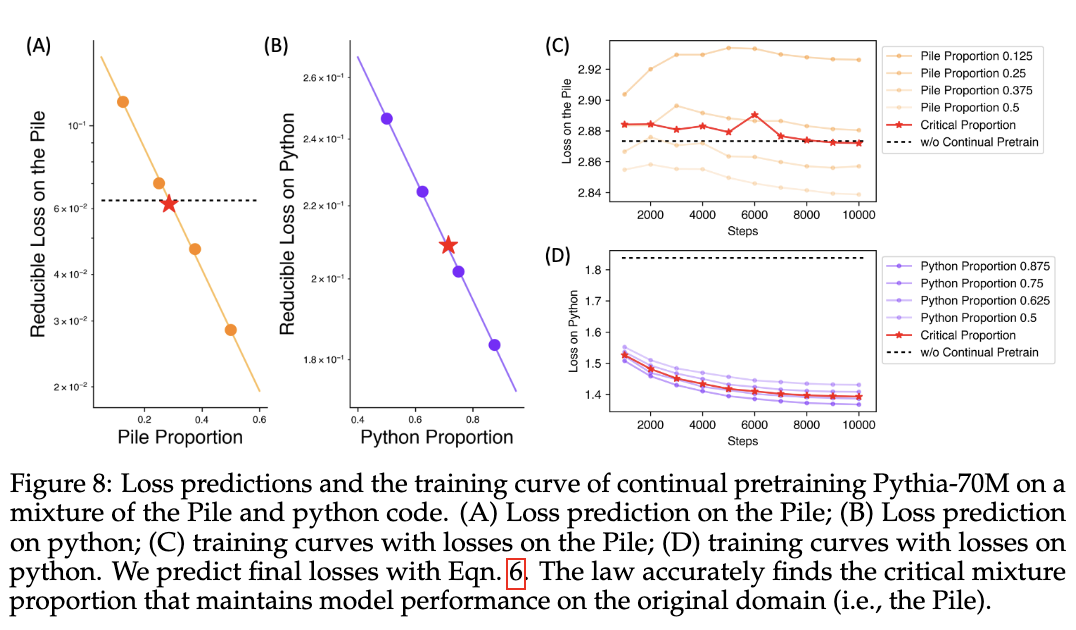
在持续的预训练过程中,目标数据的比例太大会损害原始数据的性能。混合优化目标是保持通用能力(在Pile上的losses)不变。为此,使用拟合过的数据混合定律,预测与连续预训练之前相同的损失的关键比例。图 8 展示了预测的成功,发现的比例与持续预训练之前的模型相比具有相似的性能,同时在目标域中获得了改进。
作者认为持续预训练对于数据计划的设计具有重要意义。通常,持续预训练适用于预训练模型,而对连续预训练模型进一步持续预训练也是很自然的,即多阶段预训练。在每个阶段,训练数据的混合比例甚至域成分都可以不同。
当训练阶段的数量接近无限极限时,这将成为动态数据计划。因此,数据混合定律在持续训练中的成功应用标志着使用它来设计动态数据计划(一种更全面的数据管理范式)的广阔前景。
参考文献:
[1] https://arxiv.org/pdf/2403.16952.pdf
[2] https://github.com/yegcjs/mixinglaws
[3] https://arxiv.org/abs/2303.08774
这篇关于LLM漫谈(六)| 复旦MOSS提出数据配比scaling law的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




