本文主要是介绍反着用scaling law验证数据:群聊场景指代消歧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文作者:白牛
我们之前开源了 LLM 群聊助手茴香豆(以下简称豆哥),它的特点是:
- 设计了一套拒答 pipeline,实用于群聊场景。能够有效抵抗各种文本攻击、过滤无关话题,累计面对 openmmlab 数千用户运行半年( 17 个群、7w 条群消息)。这个过程确认了 text2vec 模型更适合反着用
- 工业级开源。除算法 pipeline 外,还实现对应的 android、web service, License 支持商用
- 成本低。配合 LLM API 只需要 1.5G 显存
此外我们还工程优化了 ReRoPE,llama2 13B 在 A100 单卡上不训练,就可以从 8k 外推到 40k token。
上海AI Lab推出“茴香豆”:群聊场景中的领域知识助手
然而在群聊中,豆哥往往会遇到类似对话:
张三:mmpose 支持移动端部署么?
李四:搭车问一下,怎么把它部署到 TX2 ?
王二:你们说的是哪家的算法框架?显然 “它” 应该替换成 "mmpose",然而豆哥处理李四的问题时,不能直接输入所有人的对话,否则会影响 pipeline 精度;受成本约束,也不能每一句都消,所以整件事第一步是,判断应不应该消歧。
项目链接:
https://github.com/internlm/huixiangdou
(文末点击阅读原文可直达,欢迎点亮小星星)
为了解决上述问题,我们使用的方法是手工标注 + SFT 优化 LLM,也就是 NLPer 常见地,用 LLM 优化下游 NLP 任务。
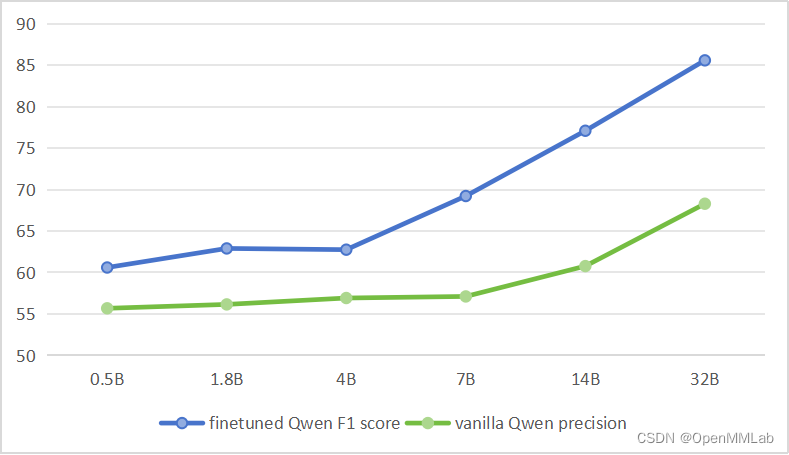
最终结果如上图,“0.5B 媲美 14B”。
绿色的是训练前的 precision 曲线,证明反反复复标一周没白干,确实能靠 scaling law 明确问题和训数据;
蓝色的是训练后的 F1 score 曲线。
- 14B 的 recall 是最高的、能达到 92.11
- 32B 的 F1 score 最高,到了85.58
- 额外地,MoE-2.7B 涨了 +29.07,详见见 arXiv 里的表格
| 本文贡献是: 1.如何证明标注本身没有 bias ? 我们使用 scaling law 定义问题、确认标注可靠。 scaling law 是说数据内容不变,精度随参数量和训练数据量线性增大。 反过来想,取一组相同架构的 LLM(qwen 0.5~32B)不变,prompt 和数据标注变化。如果数据的精度表现,随模型体积而改善,那是不是证明了数据标得好 ? 当然这个 “标得好” 更多的是和 qwen 更契合,更容易 finetune、更适合 GPU-poor。 2.数据来自微信群聊——卷卷群(ncnn contributors group),我们开源了 2.3k 手工标注数据和对应的 LoRA weights,授权见末尾。 3.所有实验均可复现,trick 已在论文中注明。 |
|---|
1.数据准备
数据来源。选 ncnn 卷卷群是因为:
- 群友背景复杂,当老板的打工的读书的都有、软件硬件女装啥都会。 AKA 数据范化性强。
- ncnn 不是某个 team 维护的,大小事情是靠爱发电,导致平均群活跃高达 87 条/人月。
预处理。原始输入取了 58,000 条,直接标注能标死我。所以做了 concat 和 filter 两步预处理:一来是用户确实发 2 句话才讲 1 个事; 二来大部分内容也不是问题,豆哥并不关心陈述句。预处理后得到 2,302 句问题。
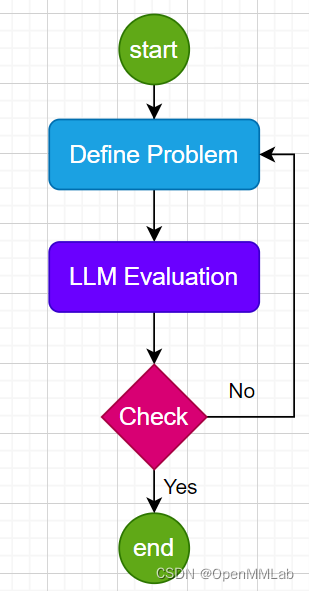
标注过程是个循环,不是手工标一次搞定的。
- STEP1. 按指代消歧的定义构造 prompt,想清了问题再手动标
- STEP2. 标好了用 7 个 vanilla LLM 跑精度
- STEP3. 如果 precision 不随参数量增长,检查 prompt 和问题定义,看哪里没明确。重复 STEP1
如此重复 5 轮,得到 alpaca.json
2. 训练
参照知乎其他人的 finetune 经验, 2k 数据量上不了 further pretrain,fp16 的 SFT 也未必好。
虽然 LoRA 不靠谱,可听人劝吃饱饭。我们用的 axolotl,顺手发了个 typo PR。
第一轮 LoRA epoch=1,lr=2e-4,rank=64,4B F1 score 掉点 -12,其他模型都在涨。
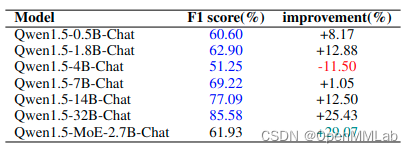
想象中,4B 的 F1 score 应该在 62.9 到 69.22 之间。
那咋整?继续治疗呗..
我们尝试了 lr=2e-5;不同的 rank;换 LoRA+,也就改 lr 能让损失缩小到 -3。

注意缩小 lr 对其他模型(7B、1.8B、2.7B)都没用,并不是个可靠方法。
果然 LoRA 不靠谱,继续遍历参数已经没有意义。我们也尝试过全量微调,2 个 epoch 后模型会退化为下游 NLP 任务中的分类器,尽管 F1 score 高达 71.38,全量微调后的模型已经失去通用能力。
3. 结论
现在看来 base 模型和数据是可靠的,但训练方法不太行。
- 检查 weight ,看训练方法为啥不行,即 4B 上 low-rank 前提被满足了多少?
- 现在有个 recall 92 的模型,只是应用的第一步。我估计后面实用还都是坑 qaq。
附录
论文地址:https://arxiv.org/abs/2405.02817
alpaca 训练数据:https://huggingface.co/datasets/tpoisonooo/HuixiangDou-CR/tree/main
LoRA 14B 权重:https://huggingface.co/tpoisonooo/HuixiangDou-CR-LoRA-Qwen-14B
LoRA 32B 权重:https://huggingface.co/tpoisonooo/HuixiangDou-CR-LoRA-Qwen-32B
WanDb 实验记录:https://wandb.ai/tpoisonooo/huixiangdou-cr
复现步骤:https://github.com/InternLM/HuixiangDou/tree/main/sft
卷卷群隐私授权,我是群主我说了算(逃
这篇关于反着用scaling law验证数据:群聊场景指代消歧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




