本文主要是介绍Reproducible scaling laws for contrastive language-image learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇scaling laws横轴是GMAC per sample x samples seen,“GMAC” 是"Giga Multiply-Accumulate" 的缩写,这是计算机部件/系统所能执行的运算量的一种度量方式。一次 “multiply-accumulate” (乘累加) 操作包括一个乘法和一个累加操作。“Giga” 是表示10^9,也就是十亿的前缀。所以,一Giga MAC (GMAC) 可以表示一部分硬件在一秒内可以执行十亿次乘累加操作。
GMAC可以由thop包中的profile来统计
from thop import profile
input = torch.randn(1, 3, 224, 224) # 这只是一个例子,你可能需要根据你模型的输入尺寸来更改# 下面这行假设 model 是加载有所需参数的模型
macs, params = profile(model, inputs=(input, ))gmacs = macs / (10**9) # 转换为Giga MACs
gmacs_per_sample = gmacs / input.size(0) # 计算每个样本的 Giga MACs
整个论文中的scaling law是通过from scratch来验证的,Open CLIP有weights但是没有数据,OpenCLIP有数据,同时论文中用了LAION 5B的数据
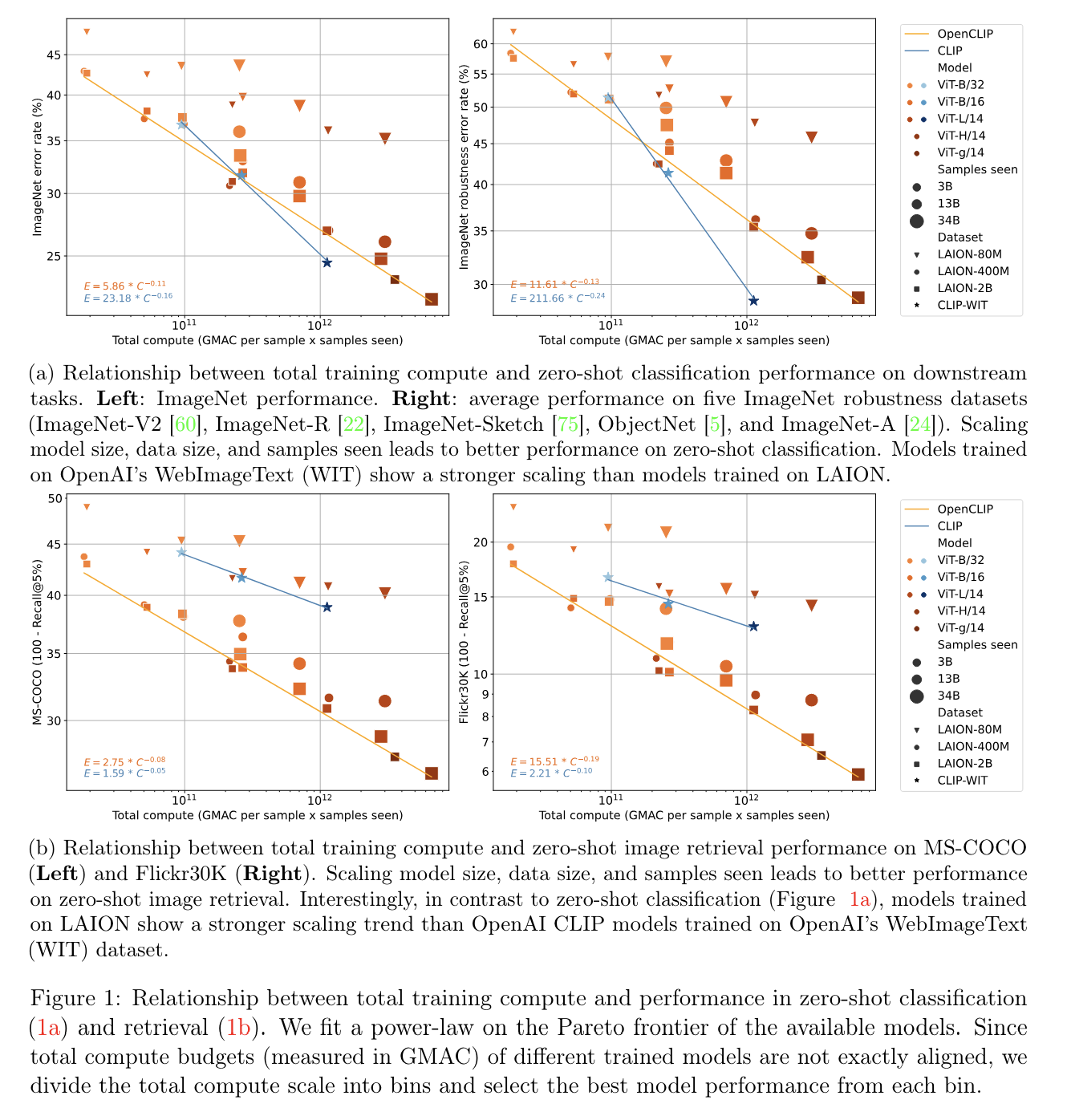
这篇关于Reproducible scaling laws for contrastive language-image learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)

