contrastive专题

Towards Graph Contrastive Learning: A Survey and Beyond
目录 Towards Graph Contrastive Learning- A Survey and Beyond摘要IntroductionPRELIMINARY符号说明GNN对比学习下游任务 GCL自监督学习增强策略基于规则随机扰动或mask子图采样图扩散 基于学习图结构学习图对抗训练图合理化 对比模式同尺度对比全局上下文局部 跨尺度对比局部-全局局部-上下文上下文-全局 对比优化
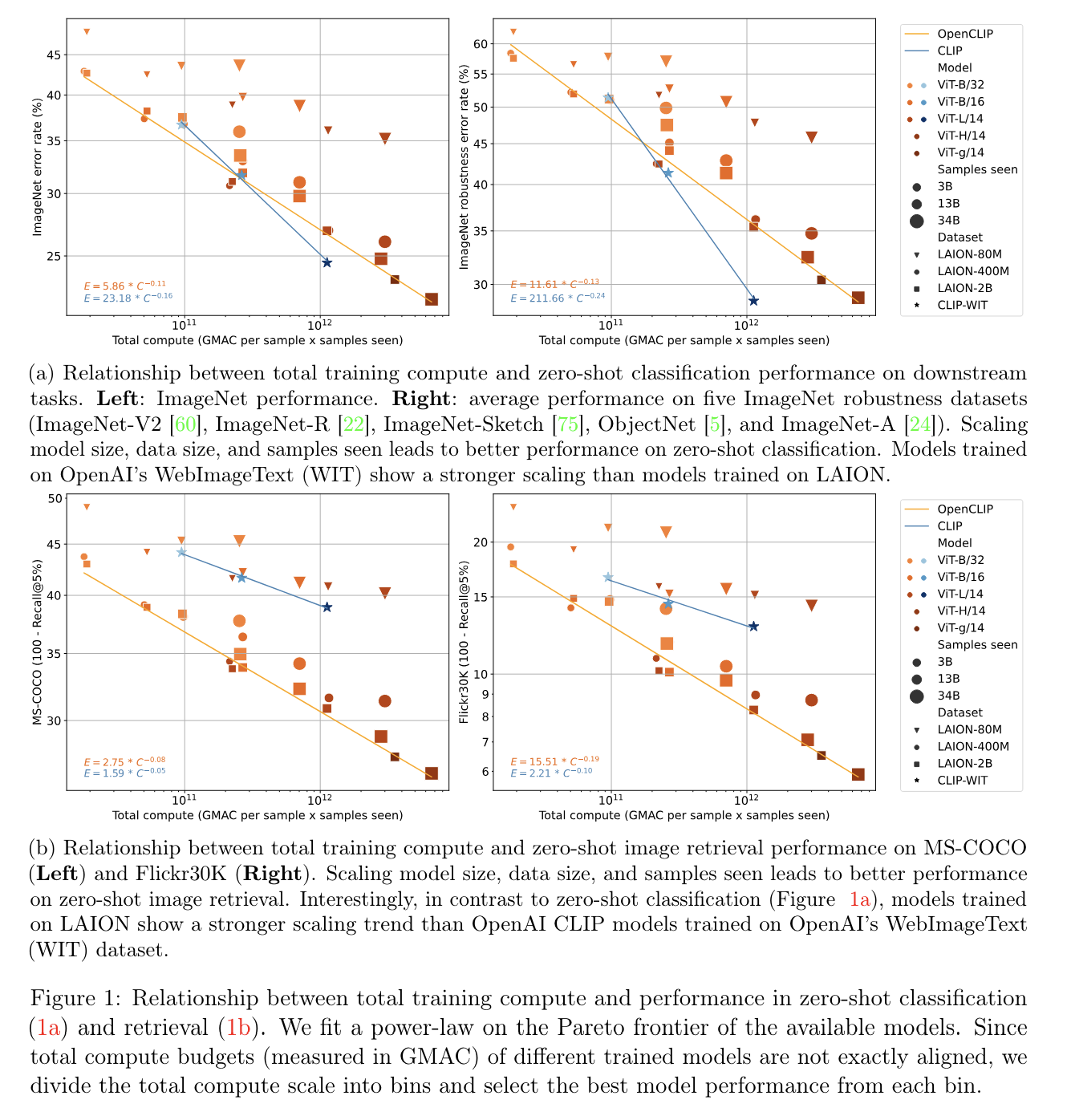
Reproducible scaling laws for contrastive language-image learning
这篇scaling laws横轴是GMAC per sample x samples seen,“GMAC” 是"Giga Multiply-Accumulate" 的缩写,这是计算机部件/系统所能执行的运算量的一种度量方式。一次 “multiply-accumulate” (乘累加) 操作包括一个乘法和一个累加操作。“Giga” 是表示10^9,也就是十亿的前缀。所以,一Giga MAC (GM

对比表征学习(一)Contrastive Representation Learning
对比表征学习(一) 主要参考翁莉莲的Blog,本文主要聚焦于对比损失函数 对比表示学习(Contrastive Representation Learning)可以用来优化嵌入空间,使相似的数据靠近,不相似的数据拉远。同时在面对无监督数据集时,对比学习是一种极其有效的自监督学习方式 对比学习目标 在最早期的对比学习中只有一个正样本和一个负样本进行比较,在当前的训练目标中,一个批次的数
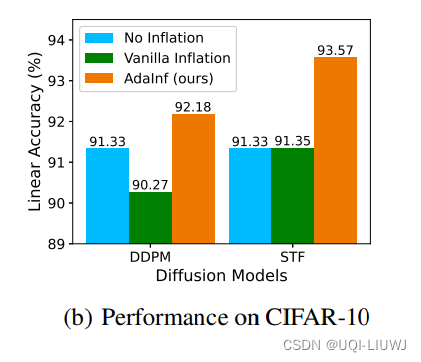
论文速读:Do Generated Data Always Help Contrastive Learning?
在对比学习领域,最近很多研究利用高质量生成模型来提升对比学习 给定一个未标记的数据集,在其上训练一个生成模型来生成大量的合成样本,然后在真实数据和生成数据的组合上执行对比学习这种使用生成数据的最简单方式被称为“数据膨胀”这与数据增强过程正交,其中无论是原始还是生成的图像都会经过手动增强以产生在对比学习中使用的正负样本对 论文发现:生成的数据并不总是有利于对比学习 仅仅将CIFAR-10通过D

(表征学习论文阅读)A Simple Framework for Contrastive Learning of Visual Representations
Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607. 1. 前言 本文作者为了了
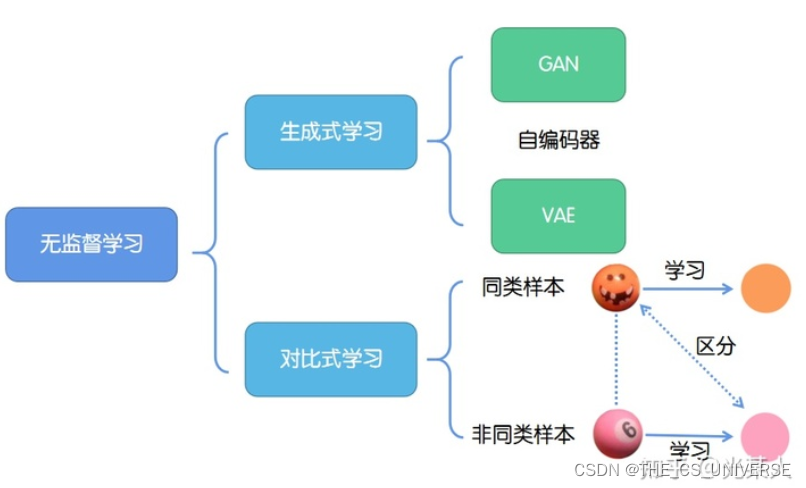
Contrastive Learning——对比学习
1.定义 对比式学习着重于学习同类实例之间的共同特征,区分非同类实例之间的不同之处。 与生成式学习比较,对比式学习不需要关注实例上繁琐的细节,只需要在抽象语义级别的特征空间上学会对数据的区分即可,因此模型以及其优化变得更加简单,且泛化能力更强。 对比学习的目标是学习一个编码器,此编码器对同类数据进行相似的编码,并使不同类的数据的编码结果尽可能的不同。 2.基本思想 缩小正样本的距离,扩大与负样
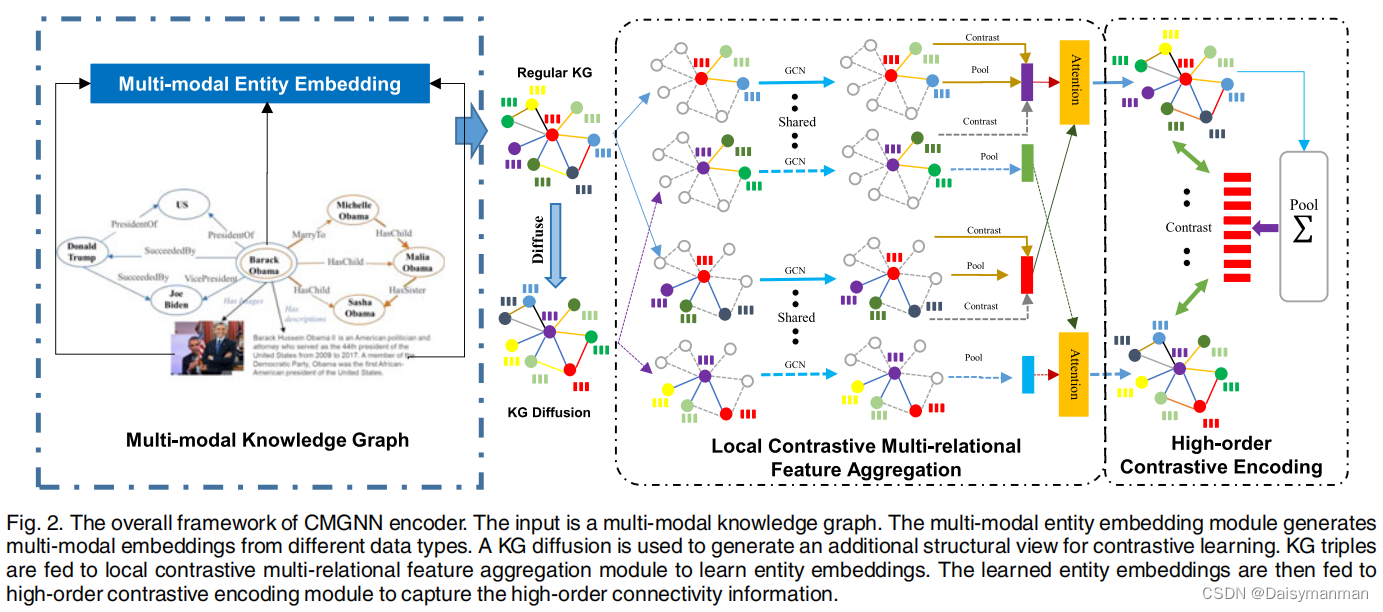
论文笔记:Contrastive Multi-Modal Knowledge GraphRepresentation Learning
论文来源:IEEE Transactions on Knowledge and Data Engineering 2023 论文地址:Contrastive Multi-Modal Knowledge Graph Representation Learning | IEEE Journals & Magazine | IEEE Xplorehttps://ieeexplore.ieee.or

ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
论文:https://arxiv.org/pdf/2301.12597.pdf 代码:GitHub - PaddlePaddle/ERNIE: Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation
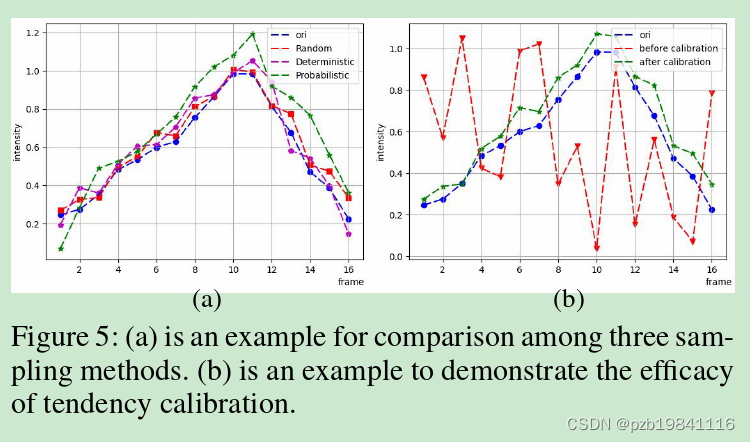
CMNet:Contrastive Magnification Network for Micro-Expression Recognition 阅读笔记
AAAI 2023的一篇文章,东南大学几位老师的工作,用于做微表情识别中的运动增强工作, 以下是阅读时记录的笔记。 摘要: However,existing magnification strategies tend to use the features offacial images that include not only intensity clues as inten-

【论文阅读笔记】Contrastive Learning with Stronger Augmentations
Contrastive Learning with Stronger Augmentations 摘要 基于提供的摘要,该论文的核心焦点是在对比学习领域提出的一个新框架——利用强数据增强的对比学习(Contrastive Learning with Stronger Augmentations,简称CLSA)。以下是对摘要的解析: 问题陈述: 表征学习(representation lear
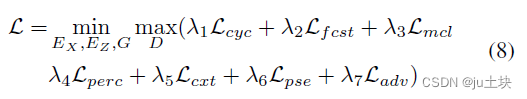
Marginal Contrastive Correspondence for Guided Image Generation(MCL-Net)论文翻译
论文链接:https://arxiv.org/abs/2204.00442 摘要 基于范例的图像翻译在来自于不同域的条件输入和范例图像之间建立密集的对应关系,旨在使用详细的范例风格实现真实的图像翻译。现有的研究通过最小化两个域的特征集距离,隐式的建立跨域对应。然而,这些方法由于没有明确利用域不变特征,因此可能不能有效减小域间隔,从而导致经常出现次优的对应和图像翻译。我们设计了一个边缘对比学习网
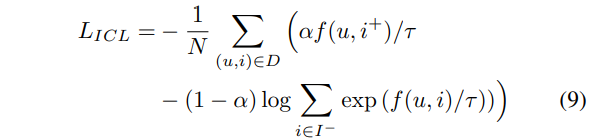
Multi-Sample based Contrastive Loss for Top-kRecommendation(IR 2021)
在 CL 中,将同一批次中的所有非正样本作为负样本,可以简单的快速获取大量负样本,CL_loss 意在最大化正对的相似性并最小化负对的相似性。而BPR 一般采用随机抽取的方式使用一个或几个负样本,BPR_loss意在最大化正样本和负样本之间的距离。它们都是通过对比过程学习的,所以BPR 损失也可以看成对比损失的一种。 为解决 CL 中正负样本不均衡的问题,作者提出了多采样正样本的 CL ,如

【论文阅读笔记】Time Series Contrastive Learning with Information-Aware Augmentations
Time Series Contrastive Learning with Information-Aware Augmentations 摘要 背景:在近年来,已经有许多对比学习方法被提出,并在实证上取得了显著的成功。 尽管对比学习在图像和语言领域非常有效和普遍,但在时间序列数据上的应用相对较少。 对比学习的关键组成部分: 对比学习的一个关键组成部分是选择适当的数据增强(augmenta

两种对比学习损失:contrastive loss 和 infoNCE loss
对比损失(contrastive loss)和信息最大化非条件估计损失(infoNCE loss)是两种常用于对比学习的损失函数。 不同点: 对比损失是通过将同类样本靠近、异类样本远离的方式进行训练,而infoNCE损失则是通过最大化正样本的概率和最小化负样本的概率来进行训练。对比损失通常使用欧氏距离或余弦距离作为相似性度量,而infoNCE损失则使用信息论中的互信息来度量样本之间的相关性。在

【论文阅读】Perceiving Stroke-Semantic Context: Hierarchical Contrastive Learning for Robust Scene Text Re
Perceiving Stroke-Semantic Context: Hierarchical Contrastive Learning for Robust Scene Text Recognition 作者:Hao Liu1†, Bin Wang1, Zhimin Bao1, Mobai Xue1,2‡, Sheng Kang1,2‡, Deqiang Jiang1, Yinsong Li
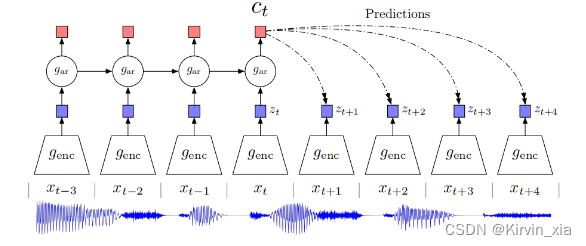
【论文阅读笔记】 Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding 摘要 这段文字是论文的摘要,作者讨论了监督学习在许多应用中取得的巨大进展,然而无监督学习并没有得到如此广泛的应用,仍然是人工智能中一个重要且具有挑战性的任务。在这项工作中,作者提出了一种通用的无监督学习方法,用于从高维数据中提取有用的表示,被称为“对比预测编码”(Contra

Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
通过视觉对比解码减轻大型视觉语言模型中的物体幻觉 Abstract 大视觉语言模型(LVLM)已经取得了长足的进步,将视觉识别和语言理解交织在一起,生成不仅连贯而且与上下文相协调的内容。尽管取得了成功,LVLM 仍然面临物体幻觉的问题,即模型生成看似合理但不正确的输出,其中包括图像中不存在的物体。为了缓解这个问题,我们引入了视觉对比解码(VCD),这是一种简单且无需训练的方法,可以对比源自原始

【深度学习:(Contrastive Learning) 对比学习】深入浅出讲解对比学习
对比学习允许模型从未标记的数据中提取有意义的表示。通过利用相似性和不相似性,对比学习使模型能够在潜在空间中将相似的实例紧密地映射在一起,同时将那些不同的实例分开。这种方法已被证明在计算机视觉、自然语言处理 (NLP) 和强化学习等不同领域都是有效的。 在本综合指南中,我们将探讨: 【深度学习:(Contrastive Learning) 对比学习】深入浅出讲解对比学习 什么是对比学习
论文笔记:Contrastive Learning for Image Captioning
原文链接:Contrastive Learning for Image Captioning Introduction 本文的提出的Contrastive Learning (CL) 主要是为了解决Image Caption任务中生成的Caption缺少Distinctiveness的问题。 这里的Distinctiveness可以理解为独特性,指的是对于不同的图片,其caption也应
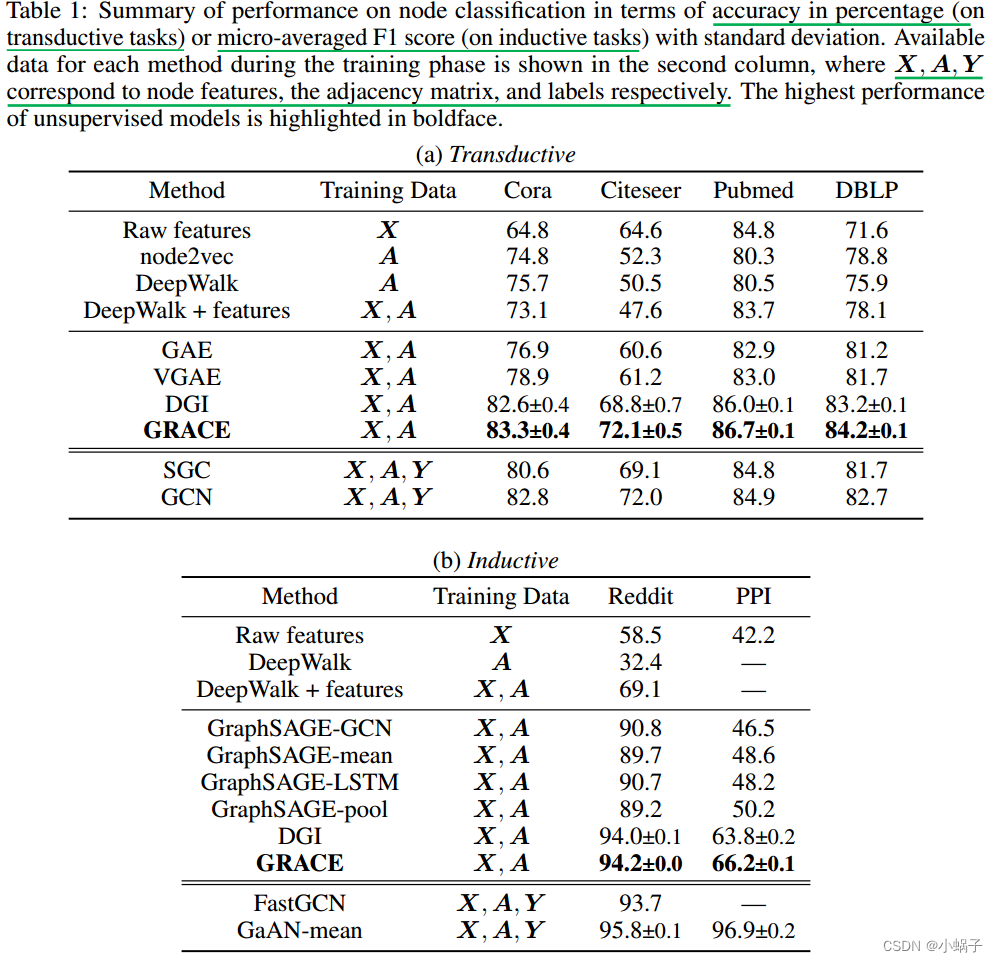
Deep Graph Contrastive Representation Learning
摘要 如今,图表示学习已成为分析图结构数据的基础。受最近成功的对比方法的启发,在本文中,我们提出了一种新的无监督图表示学习框架,该框架利用节点级别的对比目标。具体来说,我们通过破坏生成两个图视图,并通过最大化这两个视图中节点表示的一致性来学习节点表示。为了为对比目标提供不同的节点上下文,我们提出了一种混合方案,用于在结构和属性级别both structure and attribute leve

【论文】self-contrastive learning: Single-viewed Supervised Contrastive Framework using Sbu-network
Review: SelfCon: Framework: Idea: Paper:
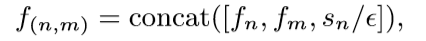
Group-aware Contrastive Regression for Action Quality Assessment
arXiv:2108.07797v1 [cs.CV] 17 Aug 2021 思路 根据样本和参考视频的相关性来提供重要的线索(因为同一个数据集的视频变化很小),以至于更准确的进行动作质量评估。使用一个Contrastive Regression (CoRe) 来成对的对比。 尽管对比回归框架可以预测相对分数∆s,∆s通常取值范围很广(例如,对于潜水,∆s∈[−30,30])。因此,直接预测∆s
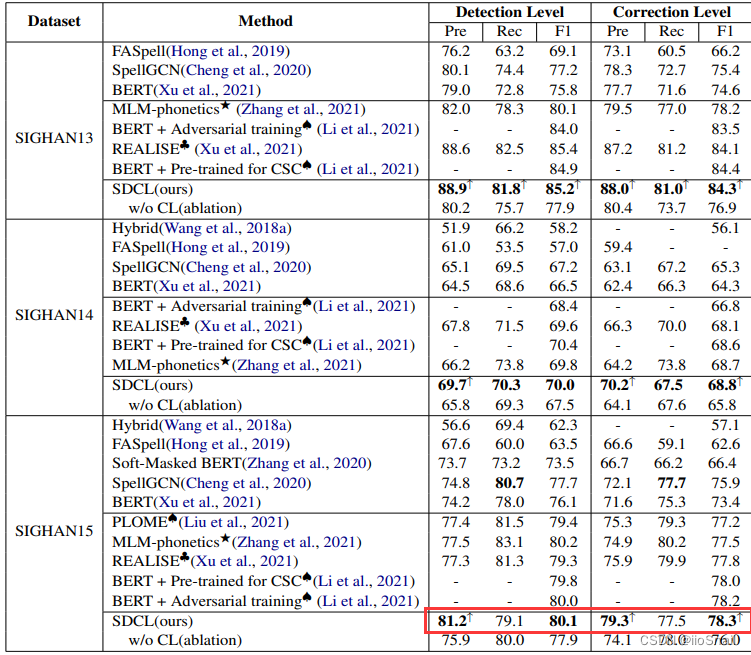
【论文笔记】SDCL: Self-Distillation Contrastive Learning for Chinese Spell Checking
文章目录 论文信息Abstract1. Introduction2. Methodology2.1 The Main Model2.2 Contrastive Loss2.3 Implementation Details(Hyperparameters) 3. Experiments代码实现个人总结值得借鉴的地方 论文信息 论文地址:https://arxiv.org/pdf/

Multi-view Graph Contrastive Representation Learning for Drug-Drug Interaction Prediction
Multi-view Graph Contrastive Representation Learning for Drug-Drug Interaction Prediction 基本信息 博客创建者 鲁智深 博客贡献人 鲁智深:主要内容介绍 作者 Yingheng Wang, Yaosen Min, Xin Chen, and Ji Wu 标签 multi-view graph

# Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding 尽管监督学习在许多应用中取得了巨大进展,但无监督学习尚未得到如此广泛的采用,仍然是人工智能的重要和具有挑战性的努力。在这项工作中,我们提出了一种通用的无监督学习方法来从高维数据中提取有用的表示,我们称之为对比预测编码。 我们模型的关键见解是通过使用强大的自回归模型在潜空间中预测
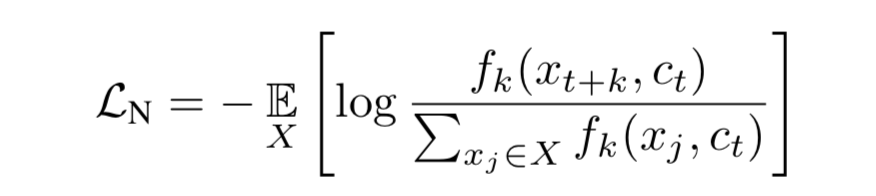
论文阅读:Representation Learning with Contrastive Predictive Coding
Representation Learning with Contrastive Predictive Coding 参考一些NLP方法 理解Contrastive Learning CPC Motivation: 该论文认为,随着预测未来更多的帧,一些noisy的低层信息会被忽略掉,更多的共享信息(该论文称之为slow features)会被提取到,这也是一些更应被关注的信息。论文举了几