本文主要是介绍ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:https://arxiv.org/pdf/2301.12597.pdf
代码:GitHub - PaddlePaddle/ERNIE: Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
引言:
-
正如人可以通过不同的描述或图片去认识真实世界一样,图像或文本同样存在多个不同的视角,单一的视角不能很好的构建模态之间的关系
-
本文提出一种多视角的多模态对比学习方法,通过构建多个视角信息去增强模态间/模态内的特征表示。
-
模型优势:
-
首次提出多视角跨模态对比学习方法,提升特征鲁棒性
-
引入实体标签文本序列,有效缩小图像-文本之间的语义鸿沟,简化大规模噪声数据上跨模态对齐的学习。
-
模型结构:

模块组成:
-
双塔结构
-
一个Image Encoder,抽取图像特征
-
一个Text Encoder,抽取文本特征
模块训练:
-
训练数据:图像文本pair对
-
构造了包括图像和文本在内,总共六个视角特征进行训练:
-
图像增强:对图像进行数据增强两次,如随机crop、图片抖动等
-
文本增强:对caption文本进行两次dropout,得到两个不同视角的文本表征
-
特殊文本序列:由固定prompt(如:该图片包含...)和实体标签短语组成(预训练实体检测器得到)的句子,同样进行两次dropout,得到两个不同视角的文本表征。
-
好处:1.特殊文本序列可看作包含粗粒度信息的文本单元,用于连接caption中的细粒度语义和图像中的抽象视觉概念,从而达到简化多模态对齐的目的。2.提供很多caption中遗漏的信息。3.图像特征需要包含更多信息。

-
-
训练Loss:
![]()
其中$(I_{v1}, I_{v2})$和$(T_{v1}, T_{v2})$分别是图像和文本模态内的正样本对,$(I_{v1}, T_{v1})和(I_{v2}, T_{v2})$表示模态间的正样本对,对于caption跟tag文本序列,训练每轮迭代会随机采样取一个

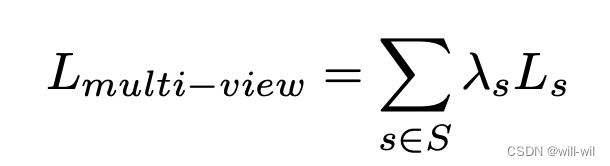
其中x,y为S集合中的某个pair对,最终每个loss加权得到最终的loss
模型实验
消融实验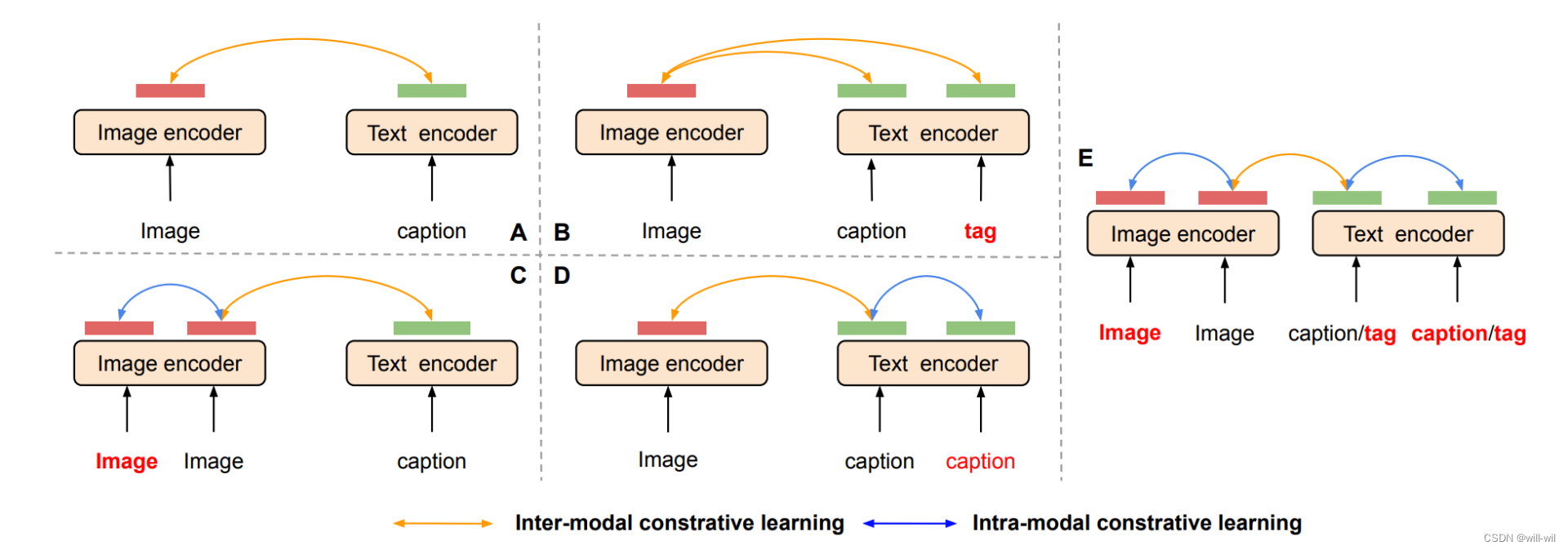

中文图像文本检索
检索样例
这篇关于ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






