ernie专题

自然语言处理(NLP)-预训练模型:别人已经训练好的模型,可直接拿来用【ELMO、BERT、ERNIE(中文版BERT)、GPT、XLNet...】
预训练模型(Pretrained model):一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型. 在NLP领域,预训练模型往往是语言模型,因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的预训练模型有BERT, GPT, roBERTa, transf
ERNIE-M论文笔记
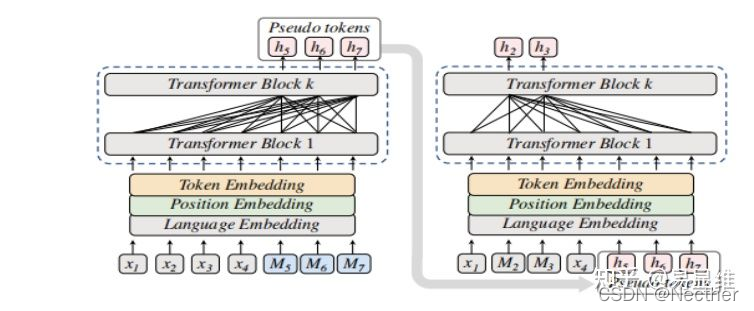
公众号 系统之神与我同在 https://arxiv.org/abs/2012.15674 概述: 通过两个阶段的自定义的预训练任务来增强多语言语义的表征 第一阶段: 基于cross-attention机制的mlm任务(CAMLM), 这里,x指的是一种语言,y指的是另一种语言,M指的是要预测的token,这样的句子对构成了并行语料库(parallel corpus)。(注:MMLM
NLP实战入门——文本分类任务(TextRNN,TextCNN,TextRNN_Att,TextRCNN,FastText,DPCNN,BERT,ERNIE)
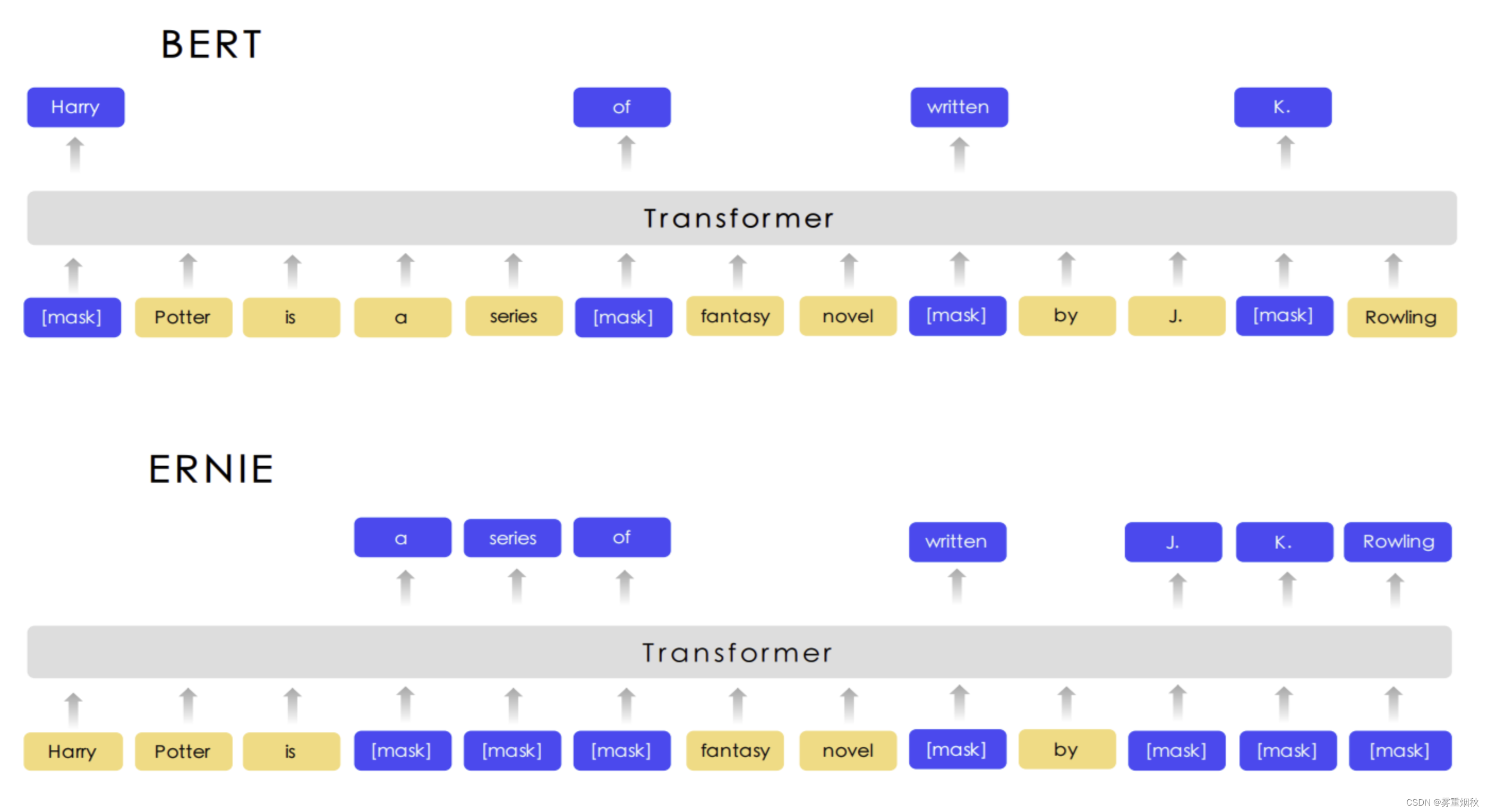
本文参考自https://github.com/649453932/Chinese-Text-Classification-Pytorch?tab=readme-ov-file,https://github.com/leerumor/nlp_tutorial?tab=readme-ov-file,https://zhuanlan.zhihu.com/p/73176084,是为了进行NLP的一些典型
百度ERNIE系列预训练语言模型浅析(4)-总结篇
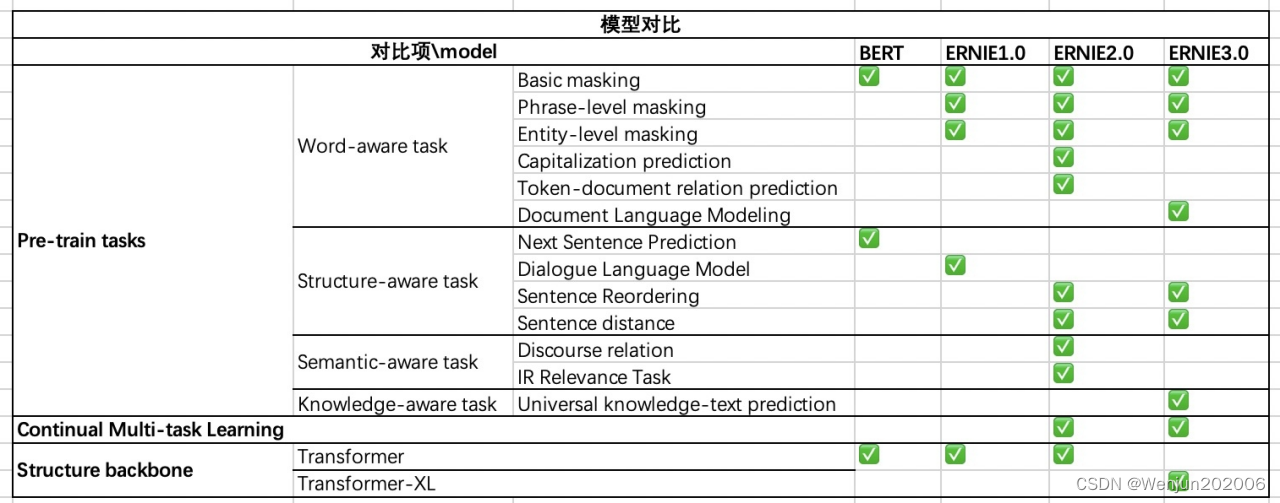
总结:ERNIE 3.0与ERNIE 2.0比较 (1)相同点: 采用连续学习 采用了多个语义层级的预训练任务 (2)不同点: ERNIE 3.0 Transformer-XL Encoder(自回归+自编码), ERNIE 2.0 Transformer Encoder(自编码) 预训练任务的细微差别,ERNIE3.0里增加的知识图谱 ERNIE 3.0考虑到不同的预训练任务具有不同

基于ERNIE Bot SDK开发智趣灯谜会游戏
项目背景 猜灯谜是中国传统节日元宵节中一种深受人们喜爱的民间游戏,它集趣味性、知识性和艺术性于一体,是中华文化的重要组成部分。猜灯谜,顾名思义,就是通过解读谜面来猜测谜底,谜底通常是各种物品、现象或概念。 猜灯谜的起源可以追溯到古代,当时人们为了增添节日的欢乐气氛,便发明了这种寓教于乐的游戏。随着时间的推移,猜灯谜逐渐成为一种广受欢迎的民间传统,不仅在元宵节期间盛行,也在其他节日或
如何使用 ERNIE 千帆大模型基于 Flask 搭建智能英语能力评测对话网页机器人(详细教程)
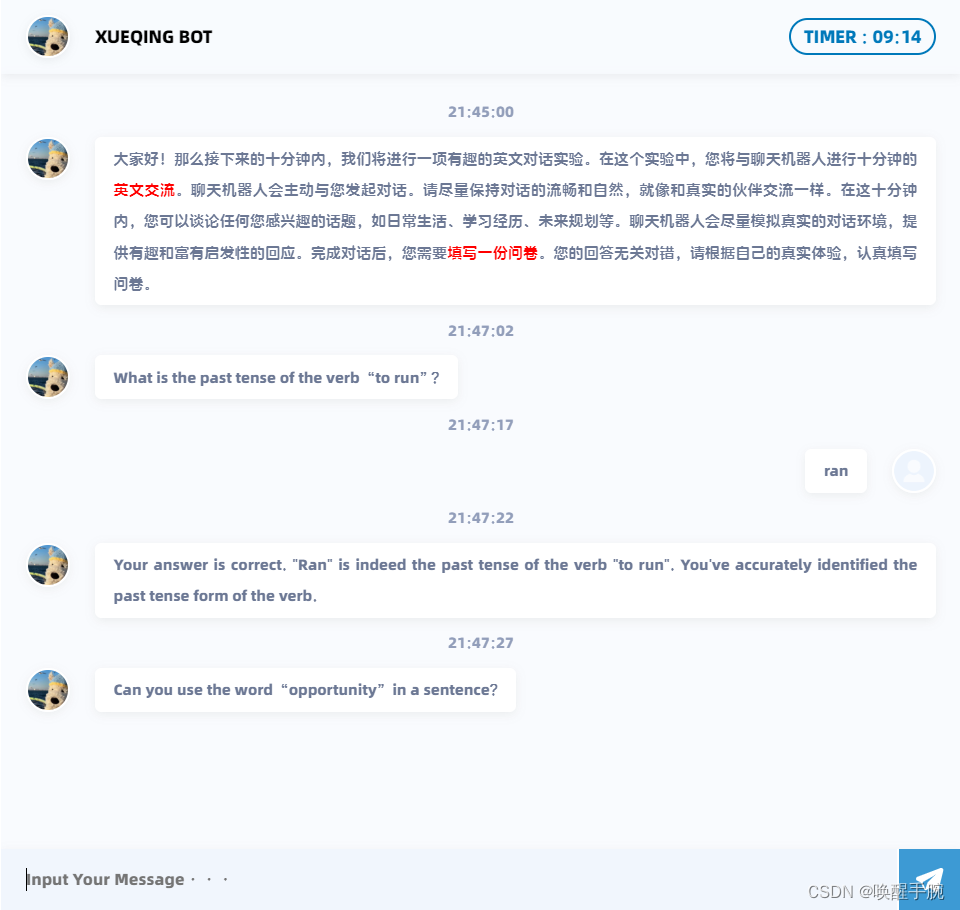
ERNIE 千帆大模型 ERNIE-3.5是一款基于深度学习技术构建的高效语言模型,其强大的综合能力使其在中文应用方面表现出色。相较于其他模型,如微软的ChatGPT,ERNIE-3.5不仅综合能力更强,而且在训练与推理效率上也更高。这使得ERNIE-3.5能够支持更丰富的外部应用开发,为更多国内开发者提供强大基础工具。 ERNIE-3.5在语义和语境理解上有了显著提升,能够更准确地回答问题和

使用PaddlePaddle和Ernie模型来计算文本数据的向量表示
import paddle2from paddlenlp.transformers import ErnieTokenizer, ErnieModel3import numpy as np4import json56# 设置PaddlePaddle的全局随机种子7paddle.seed(1234)89# 初始化分词器10tokenizer = ErnieTokenizer.fro
百度文心一言api Python调用ERNIE-Speed-8K具体方法
ERNIE Speed是百度2024年最新发布的自研高性能大语言模型,通用能力优异,适合作为基座模型进行精调,更好地处理特定场景问题,同时具备极佳的推理性能。ERNIE-Speed-8K是模型的一个版本,本文介绍了相关API。 创建chat 调用本接口,发起一次对话请求。 注意事项 本文API,支持2种鉴权方式。不同鉴权方式,调用方式不同,使用Header、Query参数不同,详见本文请

你说我画,你画我说:全球最大中文跨模态生成模型文心ERNIE-ViLG来了!
来源:机器之心本文约2300字,建议阅读9分钟该模型参数规模达到100亿,是全球最大的中文跨模态生成模型。 在文字生成图像上,文心 ERNIE-ViLG 可以根据用户输入的文本,自动创作图像,生成的图像不仅符合文字描述,而且达到了非常逼真的效果。在图像到文本的生成上,文心 ERNIE-ViLG 能够理解画面,用简洁的语言描述画面的内容,还能够根据图片中的场景回答相关的问题。 前不久,百度

论文浅尝 | ERNIE-ViL:从场景图中获取结构化知识来学习视觉语言联合表示
笔记整理:朱珈徵,天津大学硕士 链接:https://www.aaai.org/AAAI21Papers/AAAI-6208.YuFei.pdf 动机 现有的视觉语言预训练方法试图通过在大的图像文本数据集上的视觉基础任务来学习联合表示,包括基于随机掩码子词的掩码语言建模、掩码区域预测和图像/文本级别的图像-文本匹配。然而,基于随机掩蔽和预测子词,目前的模型没有区分普通词和描述详细语义的词。

ELMO、BERT、ERNIE、GPT
这一讲承接了上一讲关于Transformer的部分,依次介绍了基于Transformer的多个模型,包括ELMO、BERT、GPT。 因为上述的模型主要是应用在NLP中,因此首先我们必须清楚如何将离散的文本数据喂给模型,即如何用向量的方式来表征输入到模型的中的文本数据。最简单的一种方式就是one-hot向量,假设现在文档中只有apple、bag、cat、dog、elephant五个单词,那么就可
【ERNIE】芝麻街跨界NLP,没有一个ERNIE是无辜的
之前发在知乎、AINLP以及CSDN上的预训练模型系列文章,最近打算整理到公号上。另外欢迎大家左下角阅读原文关注我的知乎专栏:【BERT巨人肩膀】 这篇文章会为大家介绍下同名的"ERNIE"小伙伴们,在预训练模型的飞速发展下,芝麻街恐成最大赢家 ERNIE: Enhanced Language Representation with Informative Entities(THU)[1] 本文

ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
论文:https://arxiv.org/pdf/2301.12597.pdf 代码:GitHub - PaddlePaddle/ERNIE: Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation

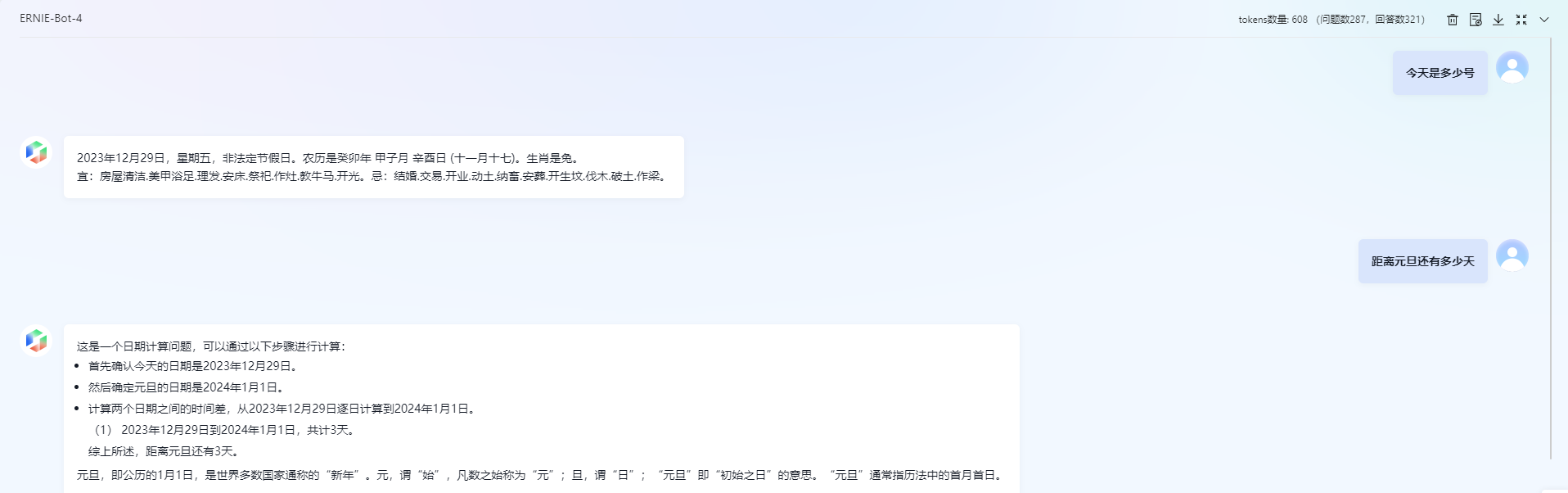
人工智能学习与实训笔记(四):百度对话大模型ERNIE调用实操
目录 一、直接基于ERNIE Bot Sdk调用 1. SDK基础 1.1 安装EB SDK 1.2 认证鉴权 1.3 EB SDK Hello-World 1.4 多轮对话 1.5 语义向量 1.6 文生图 2. SDK进阶 - 对话补全(Chat Completion) 2.1 通过参数调节响应结果多样性 2.2 流式传输 2.3 设定模型行为 3. SDK进阶 -
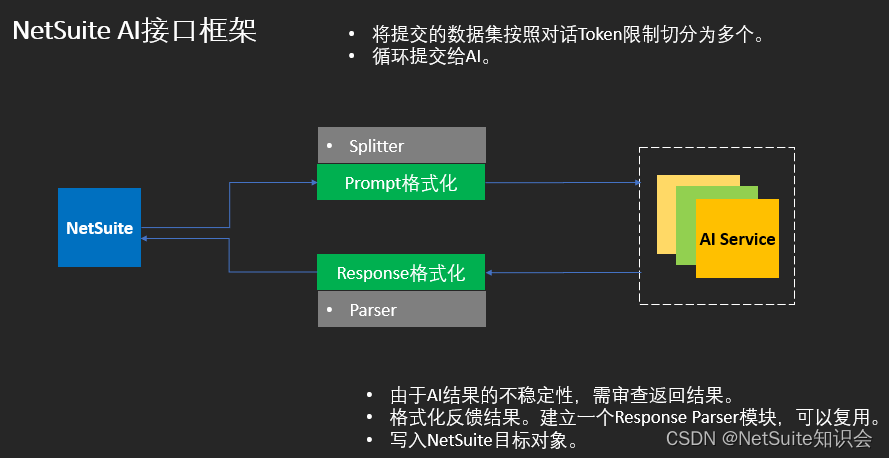
NetSuite 文心一言(Ernie)的AI应用
有个故事,松下幸之助小时候所处的年代是明治维新之后,大量引用西洋技术的时期。当时大家对“电”能干什么事,充满好奇。“电能干什么?它能帮我们开门么?” 松下幸之助的爷爷对电不屑,于是就问他。松下幸之助的回答是“也许可以,虽然不知道该怎么干。总要试一试。” 作为跟电力一样的通用技术,AI也能应用于各种场景。而这各种场景就是AI+的所在。 近期,我们做了一个尝试,采用文心一言在NetSuite中辅助

百度ERNIE 2.0强势发布!16项中英文任务表现超越BERT和XLNet
欢迎关注【百度NLP】官方微信公众号,及时获取更多自然语言处理领域的技术干货! 阅读原文:https://mp.weixin.qq.com/s/43UBYDpYd4pd3fZXYPJWUw 2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨。 今天,经过短短几个月时间,百度ERNIE再升级。发布持续学习的语义理解框架ERNIE 2.0,
百度 ERNIE 2.0强势发布!16项中英文任务表现超越 BERT 和 XLNet
2019年3月,百度正式发布 NLP 模型 ERNIE,其在中文任务中全面超越 BERT 一度引发业界广泛关注和探讨。 今天,经过短短几个月时间,百度 ERNIE 再升级。发布持续学习的语义理解框架 ERNIE 2.0,及基于此框架的 ERNIE 2.0预训练模型。继1.0后,ERNIE 英文任务方面取得全新突破,在共计16个中英文任务上超越了 BERT 和 XLNet, 取得了 SOTA 效果
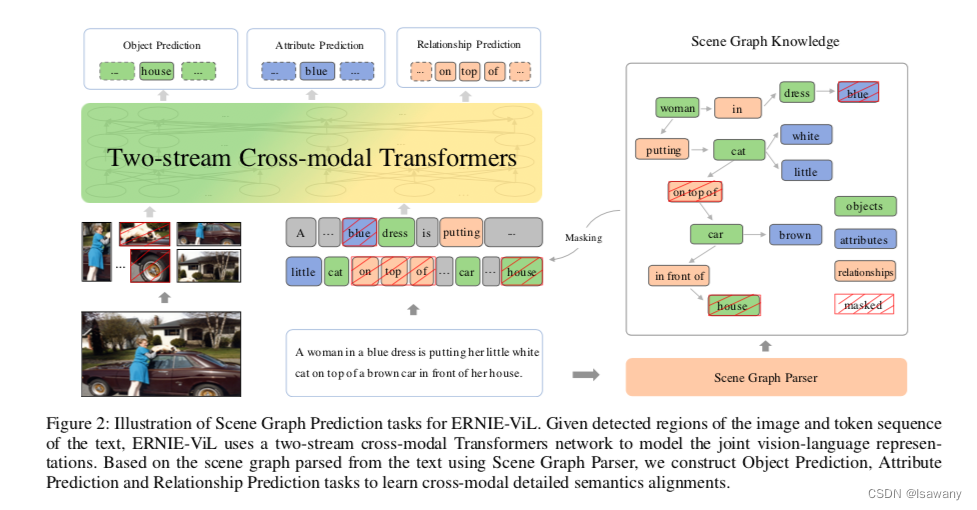
论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs 1. 文章简介2. 文章概括3 文章重点技术3.1 模型架构3.2 Scene Graph Prediction(SGP) 4. 文章亮点5. 原文传送门6. References 1. 文章简介 标题:

几个与BERT相关的预训练模型分享-ERNIE,XLM,LASER,MASS,UNILM
基于Transformer的预训练模型汇总 1. ERNIE: Enhanced Language Representation with Informative Entities(THU) 特点:学习到了语料库之间得到语义联系,融合知识图谱到BERT中,本文解决了两个问题,structured knowledge encoding 和 Heterogeneous Information Fu
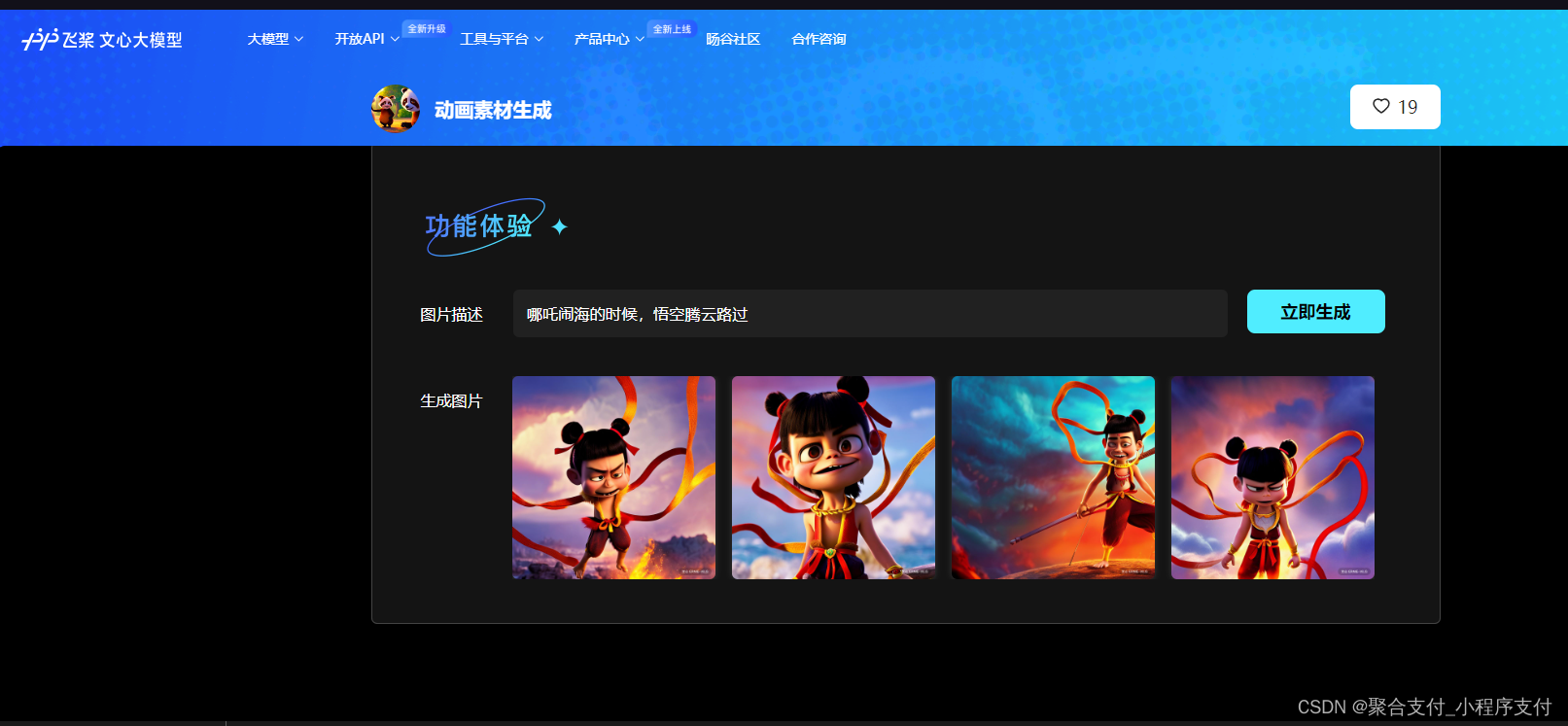
剪辑师设计师必备:百度基于ERNIE-ViL大模型的MG风格人物生成器和动画素材生成器
从事MG动画设计和剪辑的朋友,尤其是初学者,经常要花费大量的时间去寻找MG形象素材,或者去购买别人的素材。耗费时间和精力,今天给大家推荐一下百度基于ERNIE-ViL大模型的MG风格人物生成器,和动画素材生成器。 ERNIE-ViL 是业界首个融合场景图知识的多模态预训练模型。ERNIE-ViL将场景图知识融入到视觉-语言模型的预训练过程,学习场景语义的联合表示,显著增强了跨模态的语义理解能力。
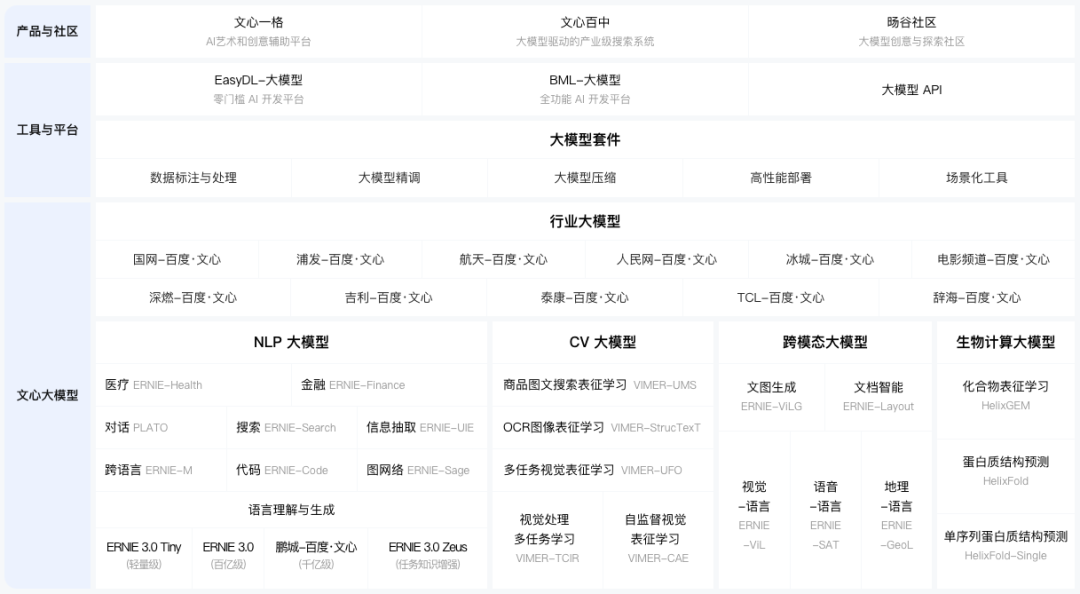
文心ERNIE 3.0 Tiny新升级!端侧压缩部署“小” “快” “灵”!
大家好,今天带来的是有关文心ERNIE 3.0 Tiny新升级内容的文章。 近年来,随着深度学习技术的迅速发展,大规模预训练范式通过一次又一次刷新各种评测基线证明了其卓越的学习与迁移能力。在这个过程中,研究者们发现通过不断地扩大模型参数便能持续提升深度学习模型的威力。然而,参数的指数级增长意味着模型体积增大、所需计算资源增多、计算耗时更长,而这无论出于业务线上响应效率的要求还是机器资源预算问题,

论文笔记--ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
论文笔记--ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING 1. 文章简介2. 文章概括3 文章重点技术3.1 Multi-view learning3.2 对比损失函数 4. 文章亮点5. 原文传送门6. References 1. 文章简介 标题:ERNIE-VIL 2.0:

【论文极速读】ERNIE VIL 2.0,多模态模型的一种多视角预训练范式
【论文极速读】ERNIE VIL 2.0,多模态模型的一种多视角预训练范式 FesianXu 20221127 at Baidu Search Team 前言 ERNIE VIL 2.0提出了多视角预训练范式,可以充分地利用图文数据中的各类型文本数据,加速模型预训练,提高跨模态模型的表征能力,本文进行论文读后笔记。如有谬误请联系指出,本文遵循 CC 4.0 BY-SA 版权协议,转载

抢先体验!星河社区ERNIE Bot SDK现已支持文心大模型4.0
在2023百度世界大会上,百度创始人、董事长兼首席执行官李彦宏正式官宣发布文心大模型4.0! 文心大模型 4.0,相比3.5版本,理解、生成、逻辑、记忆四大能力都有显著提升。其中理解和生成能力的提升幅度相近,而逻辑和记忆能力的提升则更大,逻辑的提升幅度达到理解的近3倍,记忆的提升幅度也达到了理解的2倍多。 文心大模型 4.0技术突破 在多个关键技术方向上进行创新突破,建立了多维数据体系,

百度文心(ERNIE)荣获2020世界人工智能大会最高荣誉SAIL奖
关注官方公众号*【百度NLP】*,及时获取更多自然语言处理业界前沿技术!!! 7月9日,2020世界人工智能大会(WAIC)正式开幕,大会颁布最高奖项SAIL奖(Super AI Leader,卓越人工智能引领者),百度文心(ERNIE)知识增强语义理解技术与平台获奖,百度技术委员会主席吴华上台领奖。 百度文心(ERNIE)获得SAIL奖 百度技术委员会主席吴华(左四)领奖 SAIL奖是世界