本文主要是介绍论文浅尝 | ERNIE-ViL:从场景图中获取结构化知识来学习视觉语言联合表示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

笔记整理:朱珈徵,天津大学硕士
链接:https://www.aaai.org/AAAI21Papers/AAAI-6208.YuFei.pdf
动机
现有的视觉语言预训练方法试图通过在大的图像文本数据集上的视觉基础任务来学习联合表示,包括基于随机掩码子词的掩码语言建模、掩码区域预测和图像/文本级别的图像-文本匹配。然而,基于随机掩蔽和预测子词,目前的模型没有区分普通词和描述详细语义的词。这些方法忽略了构建跨视觉和语言的详细语义对齐的重要性,因此训练的模型不能很好地表示真实场景所需的细粒度语义。因此,作者提出了一种知识增强的方法ERNIE-ViL,该方法结合从场景图中获取的结构化知识来学习视觉语言的联合表示。ERNIE-ViL试图跨视觉和语言构建详细的语义连接(对象、对象的属性和对象之间的关系),这对视觉-语言跨模态任务至关重要。利用视觉场景的场景图,ERNIE-ViL在预训练阶段构建场景图预测任务,即对象预测、属性预测和关系预测任务。具体来说,这些预测任务是通过预测句子解析的场景图中不同类型的节点来实现的。因此。ERNIE-ViL可学习描述视觉和语言中详细语义对齐的联合表示法。通过对大规模的图像文本对齐数据集进行预训练,验证了ERNIE-ViL算法在5个跨模态下游任务中的有效性。
亮点
ERNIE-ViL的亮点主要包括:
1.首次探索了场景图模式下,引入结构化知识来加强视觉语言预训练的工作,以获得更好的视觉语言联合表示描述跨模式的详细语义对齐;2.ERNIE-ViL在视觉-语言联合表示的预训练过程中构建场景图预测任务,重点关注跨模态的详细语义对齐。
概念及模型
ERNIE-ViL内部主要有两个主要模块:ERNIE-ViL模型架构和新的场景图预测任务。模型的目标是学习结合了两种模态的信息和模态之间的对齐的联合表示。如下图所示,根据从文本中解析出来的场景图,作者构造了相应的场景图预测任务,包括对象预测任务、属性预测任务和关系预测任务。这些任务迫使ERNIE-ViL对不同模式的详细语义之间的相关性进行建模。
ERNIE-ViL模型具体由三部分构成:
•Sentence Embedding:采用与BERT相似的句子预处理方法,将每个子词token的原始词嵌入、段嵌入和序列位置嵌入相结合,生成子词token的最终嵌入。•Image Embedding:对于图像,首先使用预训练的目标检测器从图像中检测出突出的图像区域。利用多类分类层之前的池化特征作为区域特征,并通过5维向量为区域位置和图像覆盖面积的比例编码每个区域的位置特征。然后将将位置向量投影成位置特征,再与区域视觉特征进行求和。•Vision-Language Encoder:评分预测。
方法整体框架如下:
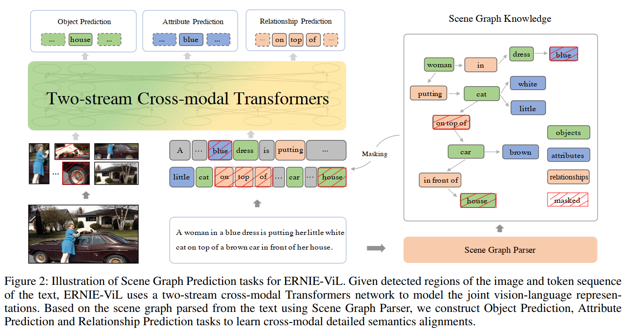
场景图编码各种细粒度的语义信息。ERNIE-ViL利用从场景图中获取的结构化知识,学习跨模态的详细语义对齐。如图所示,根据从文本中解析出来的场景图,构造了相应的场景图预测任务,包括对象预测任务、属性预测任务和关系预测任务。这些任务迫使ERNIE-ViL对不同模式的详细语义之间的相关性进行建模。例如,当关系词“on top of”被掩码时,根据语言上下文,模型可能会预测缺失的词是“under”或“into”。这些词在句子中语法流畅,但与“猫在汽车顶上”的场景不一致。该模型通过训练Relationship Prediction任务,从图像中获得对应对象(“car”、“cat”)的空间关系,从而能够准确预测缺失的单词是“on top of”。通过构建场景图预测任务。ERNIE-ViL学习跨模态的详细语义对齐。
•场景图解析
给定文本句子w,我们将其解析为一个场景图。场景图通过各种关联属性和对象之间的关系更详细地描述对象。因此,集成场景图的知识有助于学习更细粒度的视觉语言联合表示。本文采用Anderson提供的场景图解析器将文本解析为场景图。为了更直观地理解,我们从下表中的文本中举例说明已解析场景图的一个具体案例。

•对象预测
对象是视觉场景的主导元素,在构建语义信息表示中起着重要的作用。预测对象迫使模型在对象级建立视觉语言连接。对于对象预测,ERNIE-ViL将基于他们周围的单词w和所有图像区域v,通过最小化负对数似然,恢复这些被掩码的对象标记 w_{oi}:
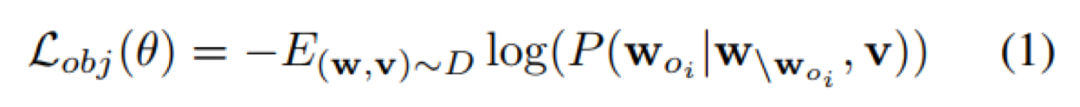
•属性预测
属性描述了视觉对象的特定信息,如颜色或形状。因此,对象在更细粒度的层次上代表了视觉场景中的详细信息。给定宾语词 w_o,在属性对<w_{oi}, w_{ai}>中,属性预测是为了恢复属性对的掩码符号w_{ai}。属性预测基于对象标记w_{oi}、其他周边单词w和所有图像区域v,使负对数似然最小化:
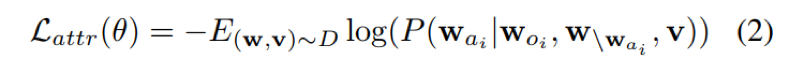
•关系预测
关系预测关系描述了视觉场景中物体之间的动作(语义)或相对位置(几何),有助于区分物体相同但关系不同的场景。因此,ERNIE-ViL构建了关系预测任务来学习跨模态关系连接。具体来说,给定对象,Woi在关系三元组中,该任务恢复被掩码关系令牌,预测每个被掩码关系令牌的概率。因此,预测的上下文是给定的对象标记,从文本和所有图像区域的其他周围的单词v。这项任务的损失是:
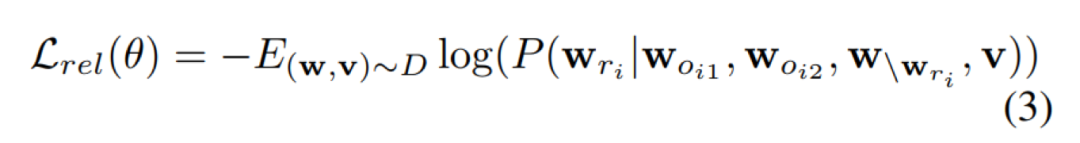
理论分析
实验
作者首先采用了2个公开数据集进行预训练,分别是:Conceptual Captions (CC)、SBU Captions (SBU)。然后在视觉常识推理(VCR)、视觉问答(VQA)、RefCOCO+、图像检索和文本检索这五个下游任务上进行试验。
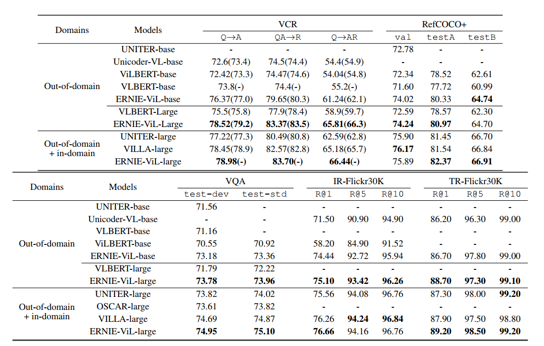
实验将ERNIE-ViL与其他跨模态训练前模型进行比较,结果如上表所示。在同一数据集(CC和SBU)上预训练的方法上,ERNIE-ViL在所有5个下游任务中获得最佳性能。在视觉推理任务中,ERNIE-ViL-large比VLBERT-large在VCR (O→AR)任务和VQA (test-std)任务上分别提高了6.60%和1.74%。在视觉任务上,ERNIE-ViL-large在RefCOCO+任务上的testA split和testB split都比VLBERT-large提高了2.40%。在跨模式检索任务中,没有大型模型在数据集上预训练的结果。与Unicoder-VL-base相比, ERNIE-ViLbase的图像检索在R@1上提高了2.94%,文本检索在R@1上提高了0.50%。
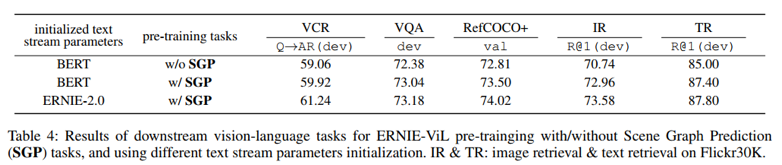
为了验证场景图预测(SGP)任务的有效性,实验首先基于BERT初始化的文本参数进行ERNIE-ViL-base设置实验。如下表所示,在ERNIEViL中使用SGP任务进行预培训,可以显著改善所有下游任务。特别是ground refer Expressions和Retrieval任务,这些任务需要理解详细的语义对齐,SGP任务在RefCOCO+上的准确率提高了0.69%,在Flickr30K上的图像检索准确率提高了2.22%。注意,从ERNIE 2.0初始化的文本参数可以导致对所有任务的进一步改进,以及对VCR任务的相对较大的改进。作者认为通过对各种训练前任务的持续学习2.0学习了更多对VCR工作有帮助的常识知识。
总结
万丈提出ERNIE-ViL来学习视觉和语言的联合表征。在传统的MLM跨模态预训练的基础上,作者引入了场景图预测任务来描述跨模态的详细语义对齐。在各种下游任务上的实验结果表明,在跨模态预训练过程中,结合从场景图中获得的结构化知识的改进。在未来的工作中,从图像中提取的场景图也可以纳入到跨模态预训练中。此外,还可以考虑集成更结构化知识的图神经网络。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
这篇关于论文浅尝 | ERNIE-ViL:从场景图中获取结构化知识来学习视觉语言联合表示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





