vil专题

(2024,Vision-LSTM,ViL,xLSTM,ViT,ViM,双向扫描)xLSTM 作为通用视觉骨干
Vision-LSTM: xLSTM as Generic Vision Backbone 公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 2 方法 3 实验 3.1 分类设计 4 结论 0. 摘要 Transformer 被广泛用作计算机视觉中的通用骨干网络,尽管它最初是为自然语言处理引入的。

论文浅尝 | ERNIE-ViL:从场景图中获取结构化知识来学习视觉语言联合表示
笔记整理:朱珈徵,天津大学硕士 链接:https://www.aaai.org/AAAI21Papers/AAAI-6208.YuFei.pdf 动机 现有的视觉语言预训练方法试图通过在大的图像文本数据集上的视觉基础任务来学习联合表示,包括基于随机掩码子词的掩码语言建模、掩码区域预测和图像/文本级别的图像-文本匹配。然而,基于随机掩蔽和预测子词,目前的模型没有区分普通词和描述详细语义的词。

ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
论文:https://arxiv.org/pdf/2301.12597.pdf 代码:GitHub - PaddlePaddle/ERNIE: Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation
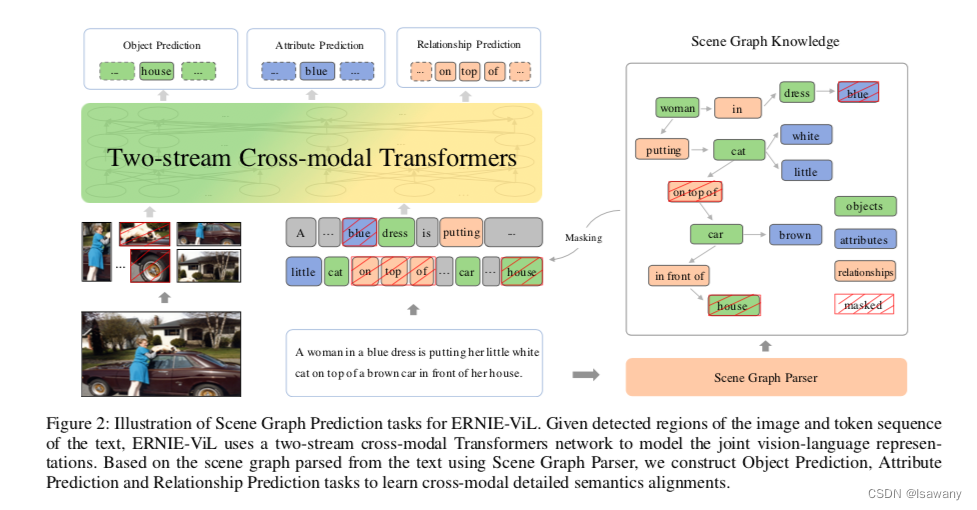
论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs 1. 文章简介2. 文章概括3 文章重点技术3.1 模型架构3.2 Scene Graph Prediction(SGP) 4. 文章亮点5. 原文传送门6. References 1. 文章简介 标题:
剪辑师设计师必备:百度基于ERNIE-ViL大模型的MG风格人物生成器和动画素材生成器
从事MG动画设计和剪辑的朋友,尤其是初学者,经常要花费大量的时间去寻找MG形象素材,或者去购买别人的素材。耗费时间和精力,今天给大家推荐一下百度基于ERNIE-ViL大模型的MG风格人物生成器,和动画素材生成器。 ERNIE-ViL 是业界首个融合场景图知识的多模态预训练模型。ERNIE-ViL将场景图知识融入到视觉-语言模型的预训练过程,学习场景语义的联合表示,显著增强了跨模态的语义理解能力。

论文笔记--ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
论文笔记--ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING 1. 文章简介2. 文章概括3 文章重点技术3.1 Multi-view learning3.2 对比损失函数 4. 文章亮点5. 原文传送门6. References 1. 文章简介 标题:ERNIE-VIL 2.0:

【论文极速读】ERNIE VIL 2.0,多模态模型的一种多视角预训练范式
【论文极速读】ERNIE VIL 2.0,多模态模型的一种多视角预训练范式 FesianXu 20221127 at Baidu Search Team 前言 ERNIE VIL 2.0提出了多视角预训练范式,可以充分地利用图文数据中的各类型文本数据,加速模型预训练,提高跨模态模型的表征能力,本文进行论文读后笔记。如有谬误请联系指出,本文遵循 CC 4.0 BY-SA 版权协议,转载