本文主要是介绍论文笔记--ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文笔记--ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 Multi-view learning
- 3.2 对比损失函数
- 4. 文章亮点
- 5. 原文传送门
- 6. References
1. 文章简介
- 标题:ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
- 作者:Bin Shan Weichong Yin Yu Sun Hao Tian Hua Wu Haifeng Wang
- 日期:2022
- 期刊:arxiv preprint
2. 文章概括
文章提出了基于Multi-view进行预训练的多模态模型ERNIE-ViL 2.0,更高效地捕捉到模态内部和模态之间的特征。文章通过引入sequence of object tags作为一种特殊view,来提升模型对语义-图像的对齐能力。实验表明,ERNIE-ViL 2.0在多个下游多模态任务上取得了SOTA水平。
3 文章重点技术
3.1 Multi-view learning
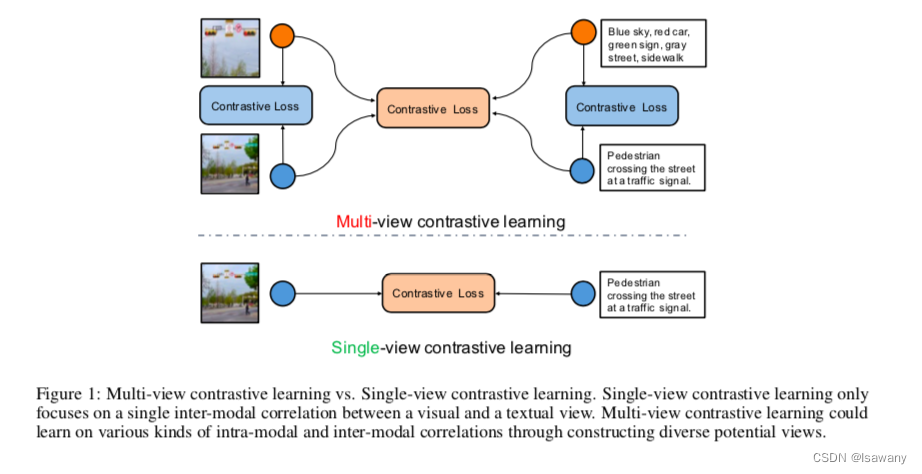
文章的整体架构基于多视角学习(Multi-view learning),简单来说就是将一个物体的多个角度的输入互为补充,比如3D物体的不同角度,比如不同组合方式,比如指纹的不同录入角度等。
首先,文章构建了各种不同的视角:
- I2I(image-image):针对输入的图片,我们通过图像增强方式来构造图像的多种视角。具体增强方法为对图片进行随机的剪裁、翻转或高斯模糊,得到图像的两个不同视角 I v 1 , I v 2 I_{v_1}, I_{v_2} Iv1,Iv2。
- T2T(text-text):针对输入的文本,文章参考SimCSE[2]的dropout方法,即对输入的文本进行随机的dropout mask对其中一部分token进行掩码,得到文本的不同视角 T v 1 , T v 2 T_{v_1}, T_{v_2} Tv1,Tv2。
- I2T(image-text)/T2I(text-image):针对输入的图片-文本对,我们引入special text sequence。具体来说,通过pretrained object detector对输入的图片进行目标检测,得到目标 o 1 , … , o k o_1, \dots, o_k o1,…,ok,然后生成prompt:This picture contains o 1 , o 2 , … , o k o_1, o_2, \dots, o_k o1,o2,…,ok。通过这个特殊的sequence对图片标题中缺失的文本信息进行补充
整体架构如下所示
3.2 对比损失函数
为了让模型学习到上述四种view,文章构建统一的损失函数将上述view结合。给定4种view的集合 S = { ( I v 1 , I v 2 ) , ( T v 1 , T v 2 ) , ( I v 1 , T v 1 ) , ( T v 1 , I v 1 ) } S = \{(I_{v_1}, I_{v_2}), (T_{v_1}, T_{v_2}), (I_{v_1}, T_{v_1}), (T_{v_1}, I_{v_1})\} S={(Iv1,Iv2),(Tv1,Tv2),(Iv1,Tv1),(Tv1,Iv1)},我们计算最小化每一个view pair的损失: L ( x , y ) = − 1 N ∑ i N log exp h x i T h y i / τ ∑ j = 1 N exp h x i T h y j / τ L_{(x, y)} = -\frac 1N \sum_i^N \log \frac {\exp h_x^{i^T} h_y^i /\tau}{\sum_{j=1}^N \exp h_x^{i^T} h_y^j /\tau} L(x,y)=−N1i∑Nlog∑j=1NexphxiThyj/τexphxiThyi/τ,其中 x , y x, y x,y表示 S S S的任意一个元素的两个view, h h h表示对应的encoder编码结果, τ \tau τ为温度, N N N为batch size。该损失函数的目的是让 h x i h_x^i hxi和 h y i h_y^i hyi尽可能相似,即每一种view中的两个view要比较接近(点积尽可能大),而每两个不同对中的两个view尽可能远。
最终模型通过最小化如下损失函数进行参数更新: L m u l t i − v i e w = ∑ s ∈ S λ s L s L_{multi-view} = \sum_{s \in S} \lambda_s L_s Lmulti−view=s∈S∑λsLs。
4. 文章亮点
文章基于multi-view learning训练得到了多模态模型ERNIE-Vil 2.0,ERNIE-ViL 2.0仅通过开源数据训练在英文跨模态检索任务上实现了zero-shot任务的显著提升,在中文跨模态检索任务上也达到了SOTA。下图展示了ERNIE-ViL 2.0 可以有效支撑一些复杂的跨模态检索任务。此外,文章通过引入目标检测信息,弥补了部分文本信息缺失的情况,更高效地实现模型对图像-文本对齐的学习。

5. 原文传送门
ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING
6. References
[1] 论文笔记–ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
[2] 论文笔记–SimCSE: Simple Contrastive Learning of Sentence Embeddings
这篇关于论文笔记--ERNIE-VIL 2.0: MULTI-VIEW CONTRASTIVE LEARNING FOR IMAGE-TEXT PRE-TRAINING的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






