本文主要是介绍论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 模型架构
- 3.2 Scene Graph Prediction(SGP)
- 4. 文章亮点
- 5. 原文传送门
- 6. References
1. 文章简介
- 标题:ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
- 作者:Fei Yu, Jiji Tang, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang
- 日期:2021
- 期刊:AAAI
2. 文章概括
文章提出了一种基于Scene Graph Prediction(SGP)来进行多模态模型预训练的方法,得到预训练模型ERNIE-ViL。实验证明,ERNIE-ViL在多个NLP任务中达到了SOTA水平,且在VCR任务上实现3.7%的提升,表明SGP预训练目标对“需求模型理解详细语义对齐”的任务有显著的帮助。
3 文章重点技术
3.1 模型架构
文章的目的是训练一个多模态模型。常用的多模态模型训练方法包括统一的视觉-文本模型和双流Transformer两类。文章选用的是双流跨模态Transformer。具体来说,
- 针对文本部分,文章采用了类BERT架构,通过wordpiece进行分词,输入内容为单词、位置和分隔id的结合,最终通过[CLS]来表示最终的句子嵌入;
- 针对图像部分,文章首先通过一个目标检测器将图像中的目标区域提取出来,假设输入图片的宽度为 W W W,高度为 H H H,检测到的目标的左上角坐标为 ( x 1 , y 1 ) (x_1, y_1) (x1,y1),右上角坐标为 ( x 2 , y 2 ) (x_2, y_2) (x2,y2),则构建每个目标区域的位置向量为 ( x 1 W , y 1 H , x 2 W , y 2 H , ( y 2 − y 1 ) ( x 2 − x 1 ) W H ) (\frac {x_1}W, \frac {y_1}{H}, \frac {x_2}W, \frac {y_2}{H}, \frac {(y_2-y_1)(x_2-x_1)}{WH}) (Wx1,Hy1,Wx2,Hy2,WH(y2−y1)(x2−x1)),包含目标的位置和面积信息,接下来将位置向量投影得到位置特征,再和该区域的视觉特征(图像数组)结合输入到模型。在每个图像的开端增加一个[IMG]token表示该图像的整体信息。
- Vision-Languge Encoder:给定上述图像目标区域输入 { [ I M G ] , v 1 , … , v I } \{[IMG], v_1, \dots, v_I\} {[IMG],v1,…,vI}和文本输入 { [ C L S ] , w 1 , … , w T , [ S E P ] } \{[CLS], w_1, \dots, w_T, [SEP]\} {[CLS],w1,…,wT,[SEP]},我们将两个输入拼接输入到ERNIE-ViL的两个Transformer中,其中每个Transformer采用的是cross-attended方式进行分数计算的,最终得到图像、文本的表示 h [ I M G ] , h [ C L S ] h_{[IMG]}, h_{[CLS]} h[IMG],h[CLS],
3.2 Scene Graph Prediction(SGP)
首先简要介绍下Scene Graph(SG)的概念。Scene Graph指包含视觉场景的结构化知识,其中graph的节点为图像中的目标(对应目标检测中的目标),边为目标之间的关系。Scene graph中包含了很多语义信息。参考ERNIE2.0[1]模型知识掩码的思想,ERNIE-ViL将SG中的信息进行掩码和预测,具体包含目标预测、属性预测和关系预测三个目标,如下图左边所示
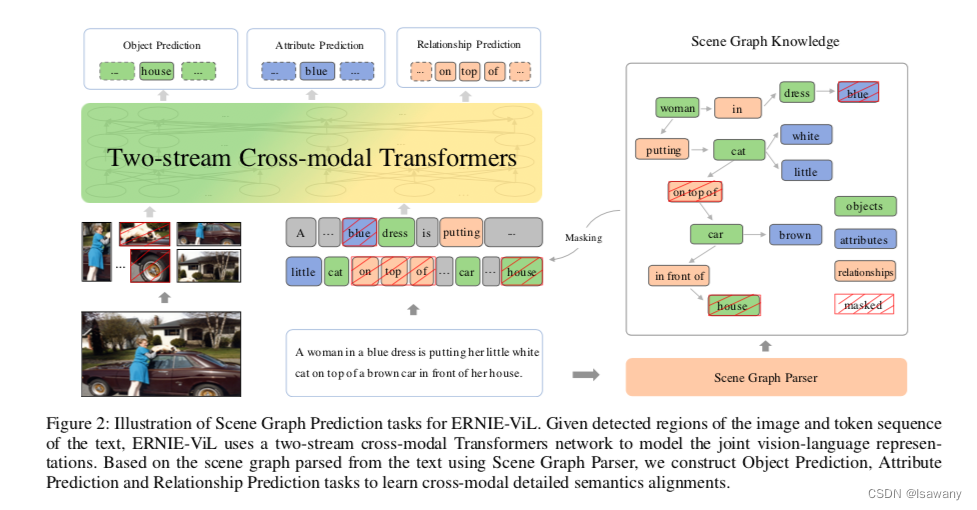
首先文章通过已有的Scene Graph Parser工具从文本中提取出SG,如上图右边所示。具体来说,给定句子 w w w,SG可表示为 G ( w ) = < O ( w ) , E ( w ) , K ( w ) > G(w) = <O(w), E(w), K(w)> G(w)=<O(w),E(w),K(w)>,其中 O ( w ) O(w) O(w)为句子 w w w中出现的目标集合, E ( w ) E(w) E(w)为句子中出现的目标之间关系集合, K ( w ) K(w) K(w)为句子中出现的目标的属性集合。
接下来文章通过三个预测任务来学习SG中出现的高级知识
- Object prediction:通过对目标节点的掩码来增强模型对目标级别的视觉-语言联系的学习。首先随机选择30%的目标,对这些目标 a) 80%的概率用[MASK]替换 b) 10%的概率用任意随机token进行替换 c) 10%的概率不变。然后通过目标 w o i w_{o_i} woi的上下文 w \ o i w_{\backslash o_i} w\oi和全部输入的图像 v v v预测目标 w o i w_{o_i} woi,损失函数为 L o b j ( θ ) = − E ( w , v ) ∼ D log P ( w o i ∣ w \ o i , v ) . \mathcal{L}_{obj}(\theta) = - E_{(w, v) \sim D} \log P(w_{o_i} | w_{\backslash o_i}, v). Lobj(θ)=−E(w,v)∼DlogP(woi∣w\oi,v).
- Attribute Prediction:通过对目标属性的掩码来增强模型学习到视觉场景中的更高级的特征。首先从SG中随机选择30%的属性对,掩码策略同上。注意这里保留属性连接的目标节点信息,只是掩码掉被选中的属性token(s) w a i w_{a_i} wai,然后通过目标节点信息 w o i w_{o_i} woi和属性的上下文信息 w \ a i w_{\backslash a_i} w\ai以及全部的输入图像 v v v预测被掩码的属性,损失函数为 L a t t r ( θ ) = − E ( w , v ) ∼ D log P ( w a i ∣ w o i , w \ a i , v ) . \mathcal{L}_{attr}(\theta) = - E_{(w, v) \sim D} \log P(w_{a_i} | w_{o_i}, w_{\backslash a_i},v). Lattr(θ)=−E(w,v)∼DlogP(wai∣woi,w\ai,v).
- Relationship Prediction:通过对目标之间的关系掩码来增强模型对相同物体不同关系的视觉场景的区分。给定SG三元组 < w o i , 1 , w r i , w o i , 2 > <w_{o_{i,1}}, w_{r_i}, w_{o_{i,2}}> <woi,1,wri,woi,2>中的两个目标节点,我们将关系token(s) w r i w_{r_i} wri进行掩码,通过目标节点 w o i , 1 , w o i , 2 w_{o_{i,1}}, w_{o_{i,2}} woi,1,woi,2和关系的上下文 w \ r i w_{\backslash r_i} w\ri以及整个图像输入 v v v来预测被掩码的关系,损失函数为 L r e l ( θ ) = − E ( w , v ) ∼ D log P ( w r i ∣ w o i , 1 , w o i , 2 , w \ r i , v ) . \mathcal{L}_{rel}(\theta) = - E_{(w, v) \sim D} \log P(w_{r_i} | w_{o_{i,1}},w_{o_{i,2}}, w_{\backslash r_i},v). Lrel(θ)=−E(w,v)∼DlogP(wri∣woi,1,woi,2,w\ri,v).
最终模型采用上述预训练任务结合MLM、MRM、ITM训练得到一个统一的模型ERNIE-ViL,其中 - MLM: Masked Language Modeling,随机对文本进行掩码,尝试还原掩码文本。详见BERT模型[2]
- MRM: Masked Region Prediction,随机对图像进行掩码,尝试还原掩码图像。掩码方式同MLM
- ITM:Image-Text Matching,判断图像-文本对是否匹配,即分类任务。具体将 < I M G > <IMG> <IMG>token和 < C L S > <CLS> <CLS>token进行element-wise点积然后增加一层MLP进行分类。
4. 文章亮点
文章提出了ERNIE-ViL模型,首次将Scene Graph知识引入到预训练的多模态模型,在包括VCR等下游任务中超过SOTA。
5. 原文传送门
ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
6. References
[1] 论文笔记–ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding
[2] 论文笔记–BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
这篇关于论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







