representations专题
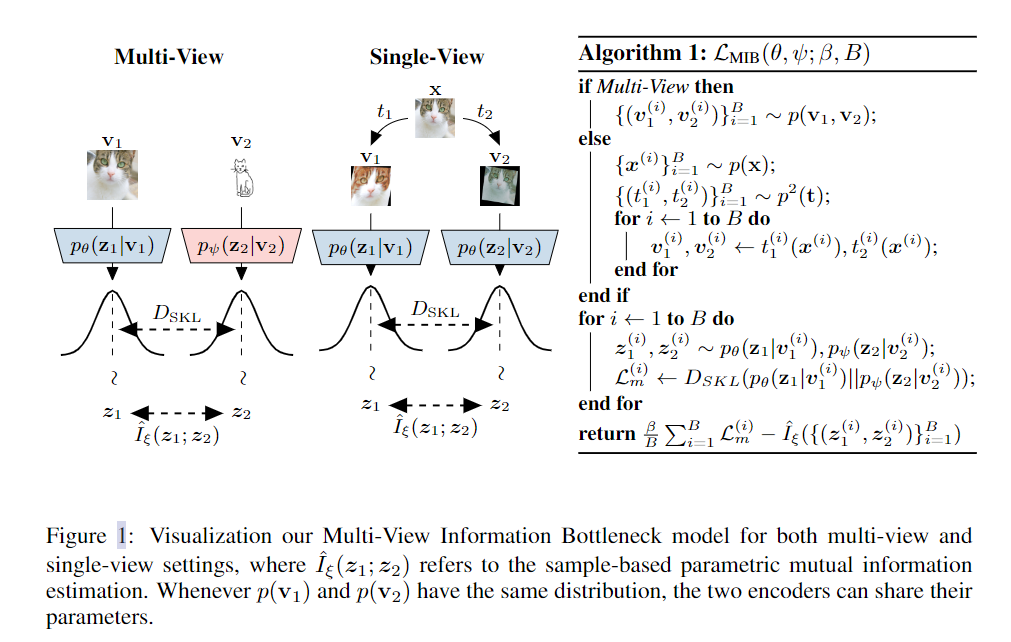
论文学习 Learning Robust Representations via Multi-View Information Bottleneck
Code available at https://github.com/mfederici/Multi-View-Information-Bottleneck 摘要:信息瓶颈原理为表示学习提供了一种信息论方法,通过训练编码器保留与预测标签相关的所有信息,同时最小化表示中其他多余信息的数量。然而,最初的公式需要标记数据来识别多余的信息。在这项工作中,我们将这种能力扩展到多视图无监督设置,其中提供

理解不同层的表示(layer representations)
在机器学习和深度学习领域,特别是在处理音频和自然语言处理(NLP)任务时,"层的表示"(layer representations)通常是指神经网络不同层在处理输入数据时生成的特征或嵌入。这些表示捕获了输入数据的不同层次的信息。 1.层的表示(layer representations) 为了更好地理解这一概念,我们可以从以下几个方面进行解释: 1. 深度神经网络结构 深度神经网络(DNN

AutoNeRF:Training Implicit Scene Representations with Autonomous Agents
论文概述 《AutoNeRF》是由Pierre Marza等人撰写的一篇研究论文,旨在通过自主智能体收集数据来训练隐式场景表示(如神经辐射场,NeRF)。传统的NeRF训练通常需要人为的数据收集,而AutoNeRF则提出了一种使用自主智能体高效探索未知环境,并利用这些经验自动构建隐式地图表示的方法。本文比较了不同的探索策略,包括手工设计的基于前沿的探索、端到端方法以及由高层规

Vector Representations of Words
在本教程我们来看一下tensorflow/g3doc/tutorials/word2vec/word2vec_basic.py查看到一个最简单的实现。这个基本的例子提供的代码可以完成下载一些数据,简单训练后展示结果。一旦你觉得已经完全掌握了这个简单版本,你可以查看向量空间模型 (VSMs)将词汇表达(嵌套)于一个连续的向量空间中,语义近似的词汇被映射为相邻的数据点。向量空间模型在自然语言处理领域中

one-hot representations独热编码
数据预处理之独热编码(One-Hot Encoding) **定义** One-Hot Encoding即 One-Hot 编码,也称独热编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。 **解决问题**:由于分类器往往默认数据数据是连续的,并且是有序的,但是在很多机器学习任务中,存在很多离
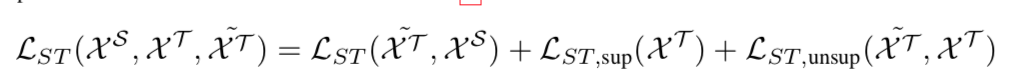
论文笔记:Label Efficient Learning of Transferable Representations across Domains and Tasks
一个使用了对抗网络和semantic transfer的迁移学习网络,用于图片分类任务。 整个网络的目标函数: 1 . 数据分为源域S的标签数据;目标域T的无标签数据;目标域T的有标签数据。 2. 蓝色的网络是基本的分类学习网络,使用S数据学习得到; 3. 绿色网络是针对域T域数据学习网络,初始化为S网络的参数; 4. 对抗网络:使用Multi-layer domain adversarial

Relphormer: Relational Graph Transformer forKnowledge Graph Representations
摘要 Transformers在自然语言处理、计算机视觉和图挖掘等广泛领域取得了显著的成绩。然而,普通的Transformer架构并没有在知识图(KG)表示中产生有希望的改进,在KG表示中,转换距离范式主导着这一领域。注意,普通的Transformer架构很难捕获知识图的内在异构结构和语义信息。为此,我们提出了Transformer的一种新变体,称为Relphormer。具体来说,我们引入了Tr

(表征学习论文阅读)A Simple Framework for Contrastive Learning of Visual Representations
Chen T, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//International conference on machine learning. PMLR, 2020: 1597-1607. 1. 前言 本文作者为了了
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
本文为论文翻译 在这个文章中,我们提出了一个新奇的神经网络模型,叫做RNN Encoder–Decoder,它包括两个RNN。一个RNN用来把一个符号序列编码为固定长度的向量表示,另一个RNN用来把向量表示解码为另外一个符号向量;提出的模型中的编码器和解码器被连接起来用于训练,目的是最大化目标序列相对于原序列的条件概率;基于经验,如果把the RNN Encoder–Decoder作为现存的lo

RCG Self-conditioned Image Generation via Generating Representations
RCG: Self-conditioned Image Generation via Generating Representations TL; DR:将图像的无监督表征作为(自)条件(而非是将文本 prompt 作为条件),生成与原图语义内容一致的多样且高质量结果。视觉训练能不能 / 需不需要摆脱文本,仍有待研究。 引言 就像图像自监督表征学习(对比学习 / 图像掩码建模)成功赶超了有监
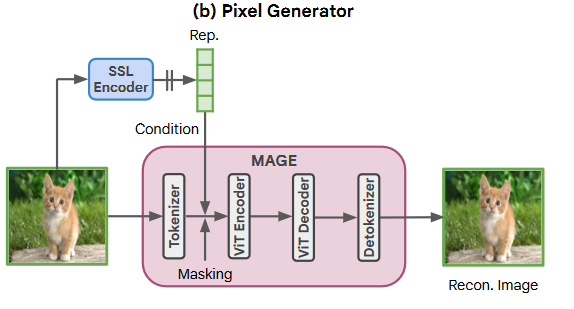
论文阅读:Self-conditioned Image Generation via Generating Representations(RCG)
Self-conditioned Image Generation via Generating Representations(RCG) work 提出的表示条件图像生成(Representation-Conditioned image Generation,RCG),一个简单而有效的框架用于自适应图像生成。 简而言之就是无附加条件生成相同分布的图片。 框架主要分为三步: 使用一个
Learning Representations and Generative Models for 3D Point Clouds
转 计算机小白学习中查看完整翻译. 点击下载英文论文 Abstract Three-dimensional geometric data offer an excellent domain for studying representation learning and generative modeling. In this paper, we look at geometric data
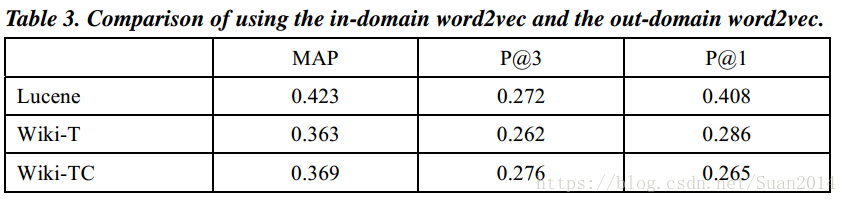
Question Retrieval with Distributed Representations and Participant Reputation in Community QA论文笔记
原文下载地址 摘要 社区问题的难点在于:重复性问题解决上述问题要采用Query retrieval(QR),QR的难点在于:同义词汇本文算法:1)采用continuous bag-of-words(CBoW)模型对词(word)进行 Distributed Representations(分布式表达,词嵌入);2)对given query和存档的query计算tile域和description

图像降噪:Zero-shot Blind Image Denoising via Implicit Neural Representations
文章目录 Zero-shot Blind Image Denoising via Implicit Neural Representations1.作者首先指出 blind-spot denoising 策略的缺点2.Implicit Neural Representations2.1 策略一:early stopping 标准2.2 策略二:Selective Weight Decay
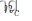
简要论文笔记:Conformer: Local Features Coupling Global Representations for Visual Recognition
作者团队: Zhiliang Peng,Wei Huang,Shanzhi Gu,Lingxi Xie,Yaowei Wang,Jianbin Jiao,Qixiang Ye国科大,华为,鹏城实验室 在下面我们将简要总结一下介绍一下Conformer,有兴趣的读者可以看下原文:论文原文 VIT后很多工作都是想办法把transforemer和convolution结合起来,希望同时享受各自的优
Conformer: Local Features Coupling Global Representations for Visual Recognition
摘要 在卷积神经网络(CNN)中,卷积运算擅长提取局部特征,但难以捕获全局表示。在visual transformer中,级联的自注意模块可以捕获长距离的特性依赖关系,但不幸的是会恶化本地特性细节。在本文中,我们提出了一种混合网络结构,称为Conformer,以利用卷积操作和自注意机制来增强表示学习。Conformer起源于特征耦合单元(Feature Coupling Unit, FCU)
低秩矩阵在机器视觉中的理解--Low-Rank representations
阅读论文Learning Structured Low-rank Representations for Image Classification 文章主要有两个创新点 1.在普通的低秩表示外另外加了对低秩表示的系数需要稀疏,这个的物理意义就是使得得出的低秩表示矩阵更有有分类性,更加表征它属于哪一类。 2。加入了一个低秩的约束,先给出了一个理想化的低秩表示的形式,再使得我们求解的低秩表示接近
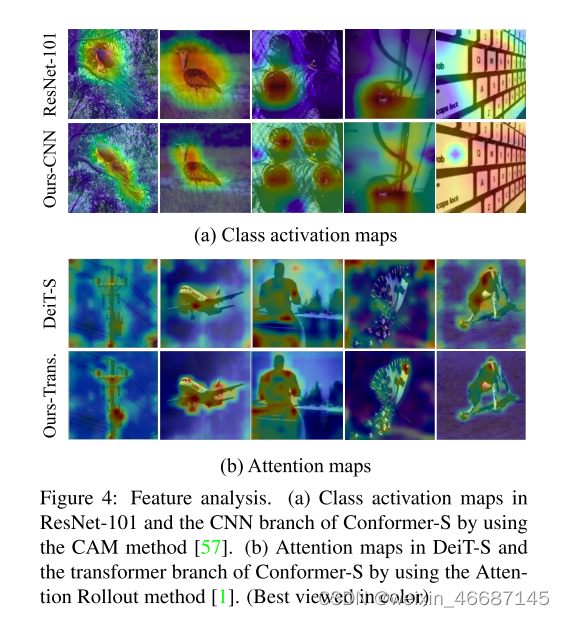
CVPR 2020 ActBERT: Learning Global-Local Video-Text Representations
动机 目前已有许多视频和语言任务来评估模型在视频-文本联合表征学习中的能力,视频数据是学习跨模态表征的自然来源。文本描述由现成的自动语音识别(ASR)模型自动生成。这对于模型在实际应用程序中的部署更具有可缩放性和通用性。在本文中,作者致力于以一种自监督的方式学习联合视频-文本表示。尽管监督学习在各种计算机视觉任务中取得了成功,但近年来,基于无标记数据的自监督表征学习引起了越来越多的关注。在自监督
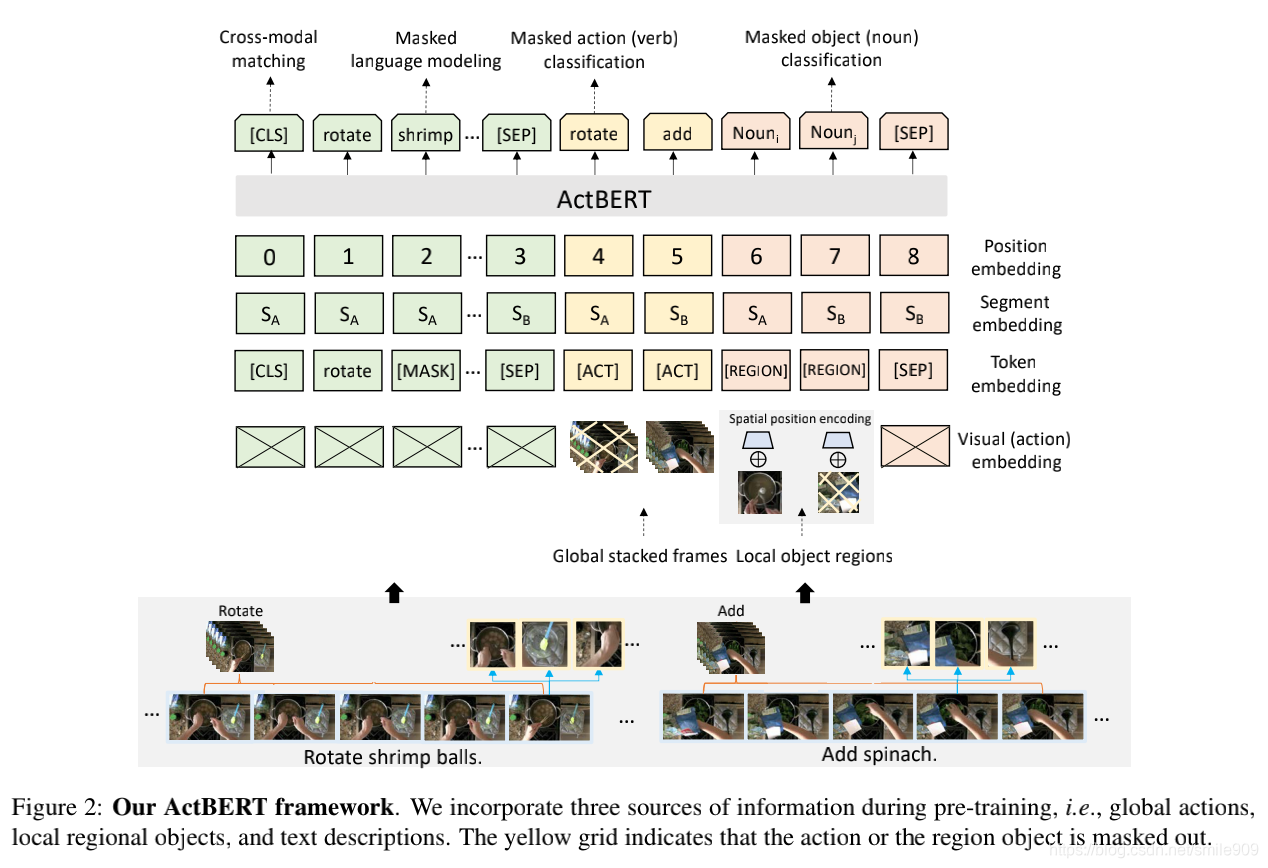
BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【3】
这是本系列文章中的第3弹,请确保你已经读过并了解之前文章所讲的内容,因为对于已经解释过的概念或API,本文不会再赘述。 本文要利用BERT实现一个“垃圾邮件分类”的任务,这也是NLP中一个很常见的任务:Text Classification。我们的实验环境仍然是Python3+Tensorflow/Keras。 一、数据准备 首先,载入必要的packages/libraries。

BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【1】
预训练模型:A pre-trained model is a saved network that was previously trained on a large dataset, typically on a large-scale image-classification task. You either use the pretrained model as is or use tran

论文笔记:SoundNet: Learning Sound Representations from Unlabeled Video
论文笔记:SoundNet: Learning Sound Representations from Unlabeled Video SoundNet: Learning Sound Representations from Unlabeled Video Yusuf Aytar∗ Carl Vondrick∗ Antonio Torralba 2016 NIPS 这篇文章是顺着一维卷积相
论文笔记:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
论文学习:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation 这篇论文算是 Seq2Seq(Sequenc to Sequence) 的经典论文了。文中提出了一种新的RNN模型结构用于机器翻译等工作,此外,作为LSTM单元的变种和简化版本 GRU 单元也是在文章

ALBERT:A LITE BERT FOR SELF-SUPERVISED LEAARNINGOF LANGUAGE REPRESENTATIONS
ABSTRACT Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. 预训练自然语言表示的时候,增加模型的大小经常导致下游任务的表现提升。 However,at some point fur
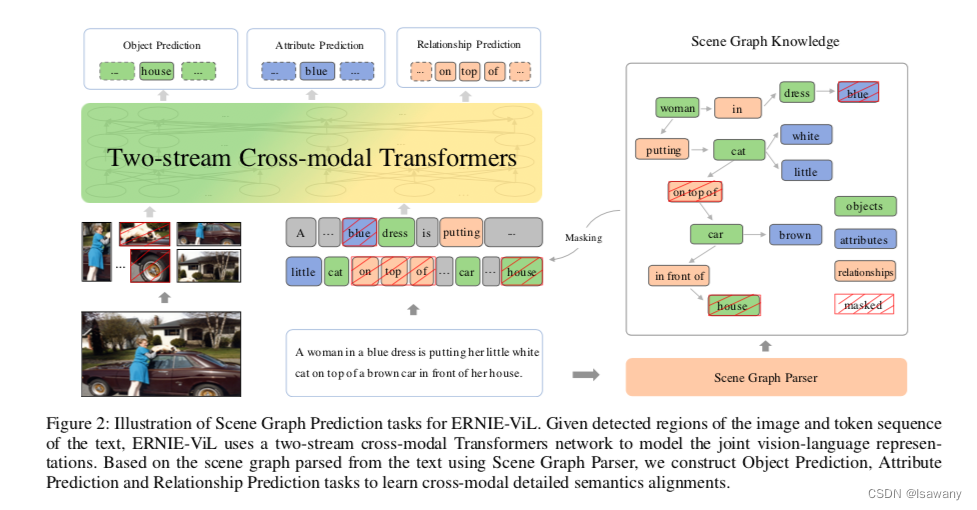
论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs
论文笔记--ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs 1. 文章简介2. 文章概括3 文章重点技术3.1 模型架构3.2 Scene Graph Prediction(SGP) 4. 文章亮点5. 原文传送门6. References 1. 文章简介 标题:
![[CBOW and Skip-gram]论文实现:Efficient Estimation of Word Representations in Vector Space](https://img-blog.csdnimg.cn/129e3cde2d0c49e8ab25cf6cda7bf7b4.png)
[CBOW and Skip-gram]论文实现:Efficient Estimation of Word Representations in Vector Space
Efficient Estimation of Word Representations in Vector Space 一、完整代码二、论文解读2.1 两个框架2.1.1 CBOW2.1.2 Skip-gram 2.2 两种加速2.2.1 Hierarchical Softmax2.2.2 Negative Sampling 三、过程实现3.1 Huffman 树 构建3.1.1 CBO
BERT-Bidirectional Encoder Representations from Transformers
BERT, or Bidirectional Encoder Representations from Transformers BERT是google最新提出的NLP预训练方法,在大型文本语料库(如维基百科)上训练通用的“语言理解”模型,然后将该模型用于我们关心的下游NLP任务(如分类、阅读理解)。 BERT优于以前的方法,因为它是用于预训练NLP的第一个**无监督,深度双向**系统。