本文主要是介绍BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【3】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是本系列文章中的第3弹,请确保你已经读过并了解之前文章所讲的内容,因为对于已经解释过的概念或API,本文不会再赘述。
本文要利用BERT实现一个“垃圾邮件分类”的任务,这也是NLP中一个很常见的任务:Text Classification。我们的实验环境仍然是Python3+Tensorflow/Keras。
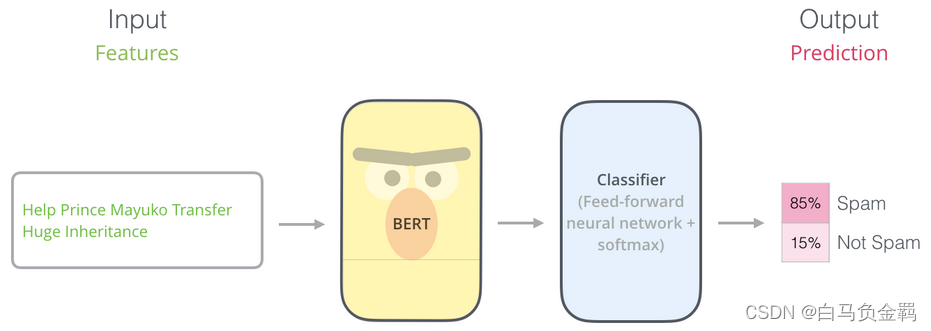
一、数据准备
首先,载入必要的packages/libraries。
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
import numpy as np
import pandas as pd
import seaborn as snfrom sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt接下来,导入数据,这是一个CSV文件,里面包含了很多邮件文本(参见【1】)。
df = pd.read_csv("spam.csv")
df.head(5)这里我们输出前5条数据作为演示:
这篇关于BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【3】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





