bert专题

Pytorch微调BERT实现命名实体识别
《Pytorch微调BERT实现命名实体识别》命名实体识别(NER)是自然语言处理(NLP)中的一项关键任务,它涉及识别和分类文本中的关键实体,BERT是一种强大的语言表示模型,在各种NLP任务中显著... 目录环境准备加载预训练BERT模型准备数据集标记与对齐微调 BERT最后总结环境准备在继续之前,确

BERT 论文逐段精读【论文精读】
BERT: 近 3 年 NLP 最火 CV: 大数据集上的训练好的 NN 模型,提升 CV 任务的性能 —— ImageNet 的 CNN 模型 NLP: BERT 简化了 NLP 任务的训练,提升了 NLP 任务的性能 BERT 如何站在巨人的肩膀上的?使用了哪些 NLP 已有的技术和思想?哪些是 BERT 的创新? 1标题 + 作者 BERT: Pre-trainin
8. 自然语言处理中的深度学习:从词向量到BERT
引言 深度学习在自然语言处理(NLP)领域的应用极大地推动了语言理解和生成技术的发展。通过从词向量到预训练模型(如BERT)的演进,NLP技术在机器翻译、情感分析、问答系统等任务中取得了显著成果。本篇博文将探讨深度学习在NLP中的核心技术,包括词向量、序列模型(如RNN、LSTM),以及BERT等预训练模型的崛起及其实际应用。 1. 词向量的生成与应用 词向量(Word Embedding)

文本分类场景下微调BERT
How to Fine-Tune BERT for Text Classification 论文《How to Fine-Tune BERT for Text Classification?》是2019年发表的一篇论文。这篇文章做了一些实验来分析了如何在文本分类场景下微调BERT,是后面网上讨论如何微调BERT时经常提到的论文。 结论与思路 先来看一下论文的实验结论: BERT模型上面的

机器之心 | 预训练无需注意力,扩展到4096个token不成问题,与BERT相当
本文来源公众号“机器之心”,仅用于学术分享,侵权删,干货满满。 原文链接:预训练无需注意力,扩展到4096个token不成问题,与BERT相当 本文提出了双向门控 SSM(BiGS)模型,结合基于状态空间模型(SSM)的 Routing 层和基于乘法门的模型架构,在不使用注意力的情况下能够复制 BERT 预训练结果,并可扩展到 4096 个 token 的长程预训练,不需要近似。 Tr

解决Can‘t load tokenizer for ‘bert-base-chinese‘.问题
报错提示: OSError: Can't load tokenizer for 'bert-base-chinese'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwi
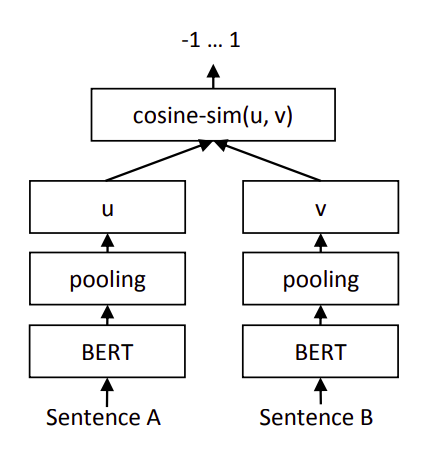
Sentence-BERT实现文本匹配【对比损失函数】
引言 还是基于Sentence-BERT架构,或者说Bi-Encoder架构,但是本文使用的是参考2中提出的对比损失函数。 架构 如上图,计算两个句嵌入 u \pmb u u和 v \pmb v v之间的距离(1-余弦相似度),然后使用参考2中提出的对比损失函数作为目标函数: L = y × 1 2 ( distance ( u , v ) ) 2 + ( 1 − y ) × 1 2

自然语言处理系列五十二》文本分类算法》BERT模型算法原理及文本分类
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《自然语言处理原理与实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】 文章目录 自然语言处理系列五十二文本分类算法》BERT模型算法原理及文本分类BERT中文文本分类代码实战 总结 自然语言处理系列五十二 文本分类算法》BERT模型算法原理及文本分类 BERT是2018年10月由Google

自然语言处理(NLP)-预训练模型:别人已经训练好的模型,可直接拿来用【ELMO、BERT、ERNIE(中文版BERT)、GPT、XLNet...】
预训练模型(Pretrained model):一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型. 在NLP领域,预训练模型往往是语言模型,因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的预训练模型有BERT, GPT, roBERTa, transf


自然语言处理-应用场景-问答系统(知识图谱)【离线:命名实体识别(BiLSTM+CRF>维特比算法预测)、命名实体审核(BERT+RNN);在线:句子相关性判断(BERT+DNN)】【Flask部署】
一、背景介绍 什么是智能对话系统? 随着人工智能技术的发展, 聊天机器人, 语音助手等应用在生活中随处可见, 比如百度的小度, 阿里的小蜜, 微软的小冰等等. 其目的在于通过人工智能技术让机器像人类一样能够进行智能回复, 解决现实中的各种问题. 从处理问题的角度来区分, 智能对话系统可分为: 任务导向型: 完成具有明确指向性的任务, 比如预定酒店咨询, 在线问诊等等.非任务导向型:

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出
深度学习速通系列:Bert模型vs大型语言模型(LLM)
什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型? 选择使用Bert模型、LLaMA模型或ChatGLM模型等大型语言模型(LLM)时,应根据具体的应用场景、任务需求、资源限制和预期目标来决定。以下是更详细的指导原则: Bert模型适用情况: 通用文本理解任务:Bert模型适用于需要理解文本语义的各种任务,如文本分类、情感分析、问答系统等。多语言支持:Bert有多种版本支

【王树森】BERT:预训练Transformer模型(个人向笔记)
前言 BERT:Bidirectional Encoder Representations from TransformerBERT是用来预训练Transformer模型的encoder的本节课只讲述主要思想BERT用两个主要思想来训练Transformer的encoder网络:①随机遮挡单词,让encoder根据上下文来预测被遮挡的单词。②把两句话放在一起,让encoder判断是不是原文相邻的

什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?
什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选? 答:Bert 的模型由多层双向的Transformer编码器组成,由12层组成,768隐藏单元,12个head,总参数量110M,约1.15亿参数量。NLU(自然语言理解)任务效果很好,单卡GPU可以部署,速度快,V100GPU下1秒能处理2千条以上。 ChatGLM-6B, LLaMA-7B模型分别是60亿参数量和

(一)bert环境搭建
最近接了一个任务关于bert生成变量,下面就踩雷事件具体描述一下,小白之间也要互相学习啊。 环境配置: 1,安装tensorflow 2,安装package pip install bert-serving-server pip install bert-serving-client 3,下载中文bert预训练的模型(https://github.com/google-rese

【大模型系列篇】预训练模型:BERT GPT
2018 年,Google 首次推出 BERT(Bidirectional Encoder Representations from Transformers)。该模型是在大量文本语料库上结合无监督和监督学习进行训练的。 BERT 的目标是创建一种语言模型,可以理解句子中单词的上下文和含义,同时考虑到它前后出现的单词。 2018 年,OpenAI 首次推出 GPT(Generative P

深度学习--词嵌入方法:GloVe和BERT详解
GloVe 1. 概念 GloVe(Global Vectors for Word Representation)是一种静态词嵌入方法,用于将词汇表示为固定长度的向量。它是由斯坦福大学的研究人员在2014年提出的,用于捕捉单词之间的语义关系并表示为向量空间中的点。 2. 作用 GloVe的主要作用是将单词转换为稠密的向量表示,这些向量可以捕捉到单词之间的语义相似性和关系。这些词向量可以在各
深度学习--Transformer和BERT区别详解
Transformer的概念、作用、原理及应用 概念 Transformer是一种基于注意力机制(Attention Mechanism)的神经网络架构,由Vaswani等人在2017年提出。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer完全摒弃了循环和卷积结构,依赖于自注意力机制和并行化的处理方式,极大地提高了模型的训练效率和效果。 作用 Transf

用序列模型(GPT Bert Transformer等)进行图像处理的调研记录
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction 北大和字节团队的一篇VLM,在生成任务上,用GPT范式,声称在FID上超过了DIT,SD3和SORA。开源。首先是multi-scale的VQVAE,然后是VAR transformer,如下图所示。每个尺度其实并不是GPT范式的

Can‘t load tokenizer for ‘bert-base-uncased‘
先下载https://storage.googleapis.com/bert_models/2020_02_20/uncased_L-12_H-768_A-12.zip 我上传了一个:https://download.csdn.net/download/LEE18254290736/89652982?spm=1001.2014.3001.5501 下载完了解压缩。 之后在项目工程新建一
Colab来训练bert模型
Colab使用 1.切换tensorflow版本号 %tensorflow_version 1.x 2.查看tensorflow版本 !pip show tensorflow 3.训练模型 !python /content/drive/My\ Drive/bert/run_english_classify.py --task_name=mypro --do_train=true
Bert+中文文本分类实现及参数解析
实现 bert模型已经被封装好了,直接使用就可以了。 但是需要自定义一个实体类,用来处理自己的数据。 直接在run_classify.py中加入下面类就可以 自定义MyDataProcessor类,传入 class MyDataProcessor(DataProcessor):"""Base class for data converters for sequence classifica
Pytorch如何获取BERT模型最后一层隐藏状态的CLS的embedding?
遇到问题 BERT模型中最后一层的句子的CLS的embedding怎么获取? 来源于阅读 An Interpretability Illusion for BERT这篇论文 We began by creating embeddings for the 624,712 sentences in our four datasets. To do this, we used the BERT-b
bert文本分类微调笔记
Bert实现文本分类微调Demo import randomfrom collections import namedtuple'''有四种文本需要做分类,请使用bert处理这个分类问题'''# 使用namedtuple定义一个类别(Category),包含两个字段:名称(name)和样例(samples)Category = namedtuple('Category',