encoder专题

人工智能-机器学习-深度学习-自然语言处理(NLP)-生成模型:Seq2Seq模型(Encoder-Decoder框架、Attention机制)
我们之前遇到的较为熟悉的序列问题,主要是利用一系列输入序列构建模型,预测某一种情况下的对应取值或者标签,在数学上的表述也就是通过一系列形如 X i = ( x 1 , x 2 , . . . , x n ) \textbf{X}_i=(x_1,x_2,...,x_n) Xi=(x1,x2,...,xn) 的向量序列来预测 Y Y Y 值,这类的问题的共同特点是,输入可以是一个定长或者不

NLP-生成模型-2017-Transformer(一):Encoder-Decoder模型【非序列化;并行计算】【O(n²·d),n为序列长度,d为维度】【用正余弦函数进行“绝对位置函数式编码”】
《原始论文:Attention Is All You Need》 一、Transformer 概述 在2017年《Attention Is All You Need》论文里第一次提出Transformer之前,常用的序列模型都是基于卷积神经网络或者循环神经网络,表现最好的模型也是基于encoder- decoder框架的基础加上attention机制。 2018年10月,Google发出一篇

Transformer模型-6-Encoder
Encoder是6层结构,每层内部结构相同,都由Multi-Head Attention和Feed Forward组成,而这两层后都带有有一个Add&Norm层,Add&Norm层由 Add 和 Norm 两部分组成, 如下: graph LRA[Input Embedding] --Positional Encoding--> B[Multi-head Attention] --> C[

专业视频编辑和制作软件Adobe Media Encoder(ME)win/mac下载安装和软件介绍
一、软件概述 1.1 软件简介 Adobe Media Encoder(ME)是由Adobe公司开发的一款专业视频编辑和制作软件,全称为Media Encoder,是Creative Cloud套件中的一个重要组件。Adobe ME以其强大的视频编码、转码、调整、剪辑、合成等功能,深受专业视频制作人员、视频制片人和爱好者的喜爱。 1.2 主要功能 视频编辑与管理:提供剪辑、切割、分层、抽取
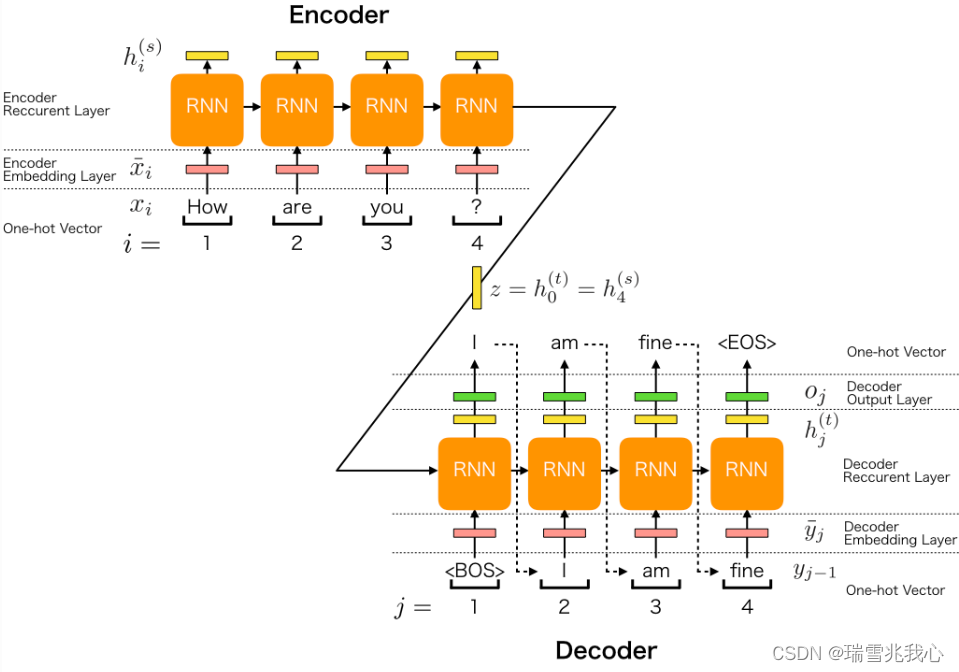
seq2seq编码器encoder和解码器decoder详解
编码器 在序列到序列模型中,编码器将输入序列(如一个句子)转换为一个隐藏状态序列,供解码器生成输出。编码层通常由嵌入层和RNN(如GRU/LSTM)等组成 Token:是模型处理文本时的基本单元,可以是词,子词,字符等,每个token都有一个对应的ID。是由原始文本中的词或子词通过分词器(Tokenizer)处理后得到的最小单位,这些 token 会被映射为词汇表中的唯一索引 ID输入: 原始
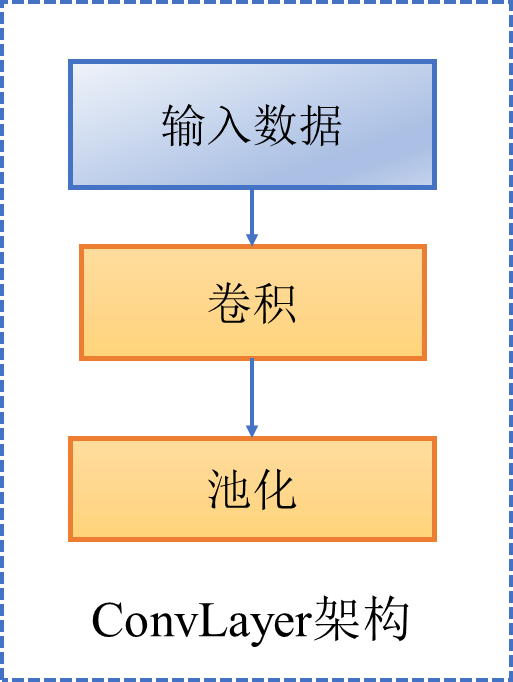
深度学习算法informer(时序预测)(三)(Encoder)
一、EncoderLayer架构如图(不改变输入形状) 二、ConvLayer架构如图(输入形状中特征维度减半) 三、Encoder整体 包括三部分 1. 多层EncoderLayer 2. 多层ConvLayer 3. 层归一化 代码如下 class AttentionLayer(nn.Module):def __init__(self, attention, d_mo
Autoencorder理解(5):VAE(Variational Auto-Encoder,变分自编码器)
reference: http://blog.csdn.net/jackytintin/article/details/53641885 近年,随着有监督学习的低枝果实被采摘的所剩无几,无监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)[1,2] 和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关

RT-DETR 详解之 Efficient Hybrid Encoder
在先前的博文中,博主介绍了RT-DETR在官方代码与YOLOv8集成程序中的训练与推理过程,接下来,博主将通过代码调试的方式来梳理RT-DETR的整个过程。 整体结构 RT-DETR的代码调试大家可以参考博主这篇文章: 在梳理整个代码之前,博主需要说明一下RT-DETR的主要创新点,方便我们在代码调试的过程中有的放矢。 博主首先使用官方代码进行讲解,在后面还会对YOLOv8集成的RT-DE

【Mac】Media Encoder 2022 for Mac(媒体编码器)V22.6.1软件介绍
软件介绍 Media Encoder 2022 for Mac是一款有着十分丰富硬件设备的编码格式设置和专门设计的预设设置功能的媒体编码器软件,Media Encoder Mac版能够帮助用户导出与特定交付媒体兼容的文件,可以很容易地将项目导出到任何屏幕上的可播放内容中。软件同时还支持用户批量处理多个视频和音频剪辑,从而有效地为用户减少大量的时间。 准备工作 重要的事情说三遍! 安装软件
cross-attention里为什么encoder提供的是KV?
依照attention在计算全连接图中有向边权重的思路,KV是中心节点的邻居们的KV,中心节点提供Q,与每个邻居单独交流(指QK),然后根据这个权重聚合邻居的信息(V)。因此,encoder提供KV,是全面抛弃了decoder端input的信息库,只将其作为从encoder中摘取信息的媒介(Q)。所以图without self-loop的图,每一个token的output都从同一个节点集合(enc

Me 2024最新版下载 Adobe Media Encoder视频编辑软件资源包下载安装!
Adobe Media Encoder,早已在影视制作、音频处理以及多媒体编辑等领域崭露头角。它不仅是专业影视编辑人员的得力助手,更是广大视频爱好者的理想之选。 这款软件具备强大的视频编辑功能,用户可以轻松地对视频进行剪辑、合并、分割以及添加特效等操作。 无论是调整视频的亮度、对比度,还是添加滤镜、转场效果,Adobe Media Encoder都能助你一臂之力。此外,它还支持多
oneapi离线在docker部署时提示failed to get gpt-3.5-turbo token encoder
one-api部署在docker中,一直都正常。项目上线正式服务器后,发现one-api容器无法启动,日志发现其无限重启,错误原因是failed to get gpt-3.5-turbo token encoder,看来它肯定是需要联网下载数据,我的正式服务器是无法上网的。 最后在github找到这么一个原因: failed to get gpt-3.5-turbo token encoder
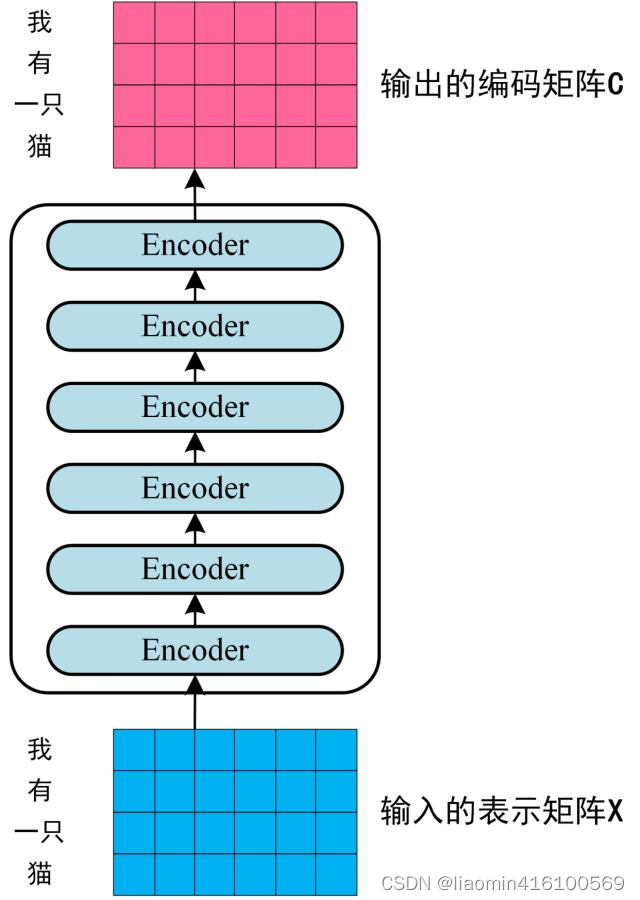
Transformer模型详解04-Encoder 结构
文章目录 简介基础知识归一化作用常用归一化 残差连接 Add & NormFeed Forward组成 Encoder代码实现 简介 Transformer 模型中的 Encoder 层主要负责将输入序列进行编码,将输入序列中的每个词或标记转换为其对应的向量表示,并且捕获输入序列中的语义和关系。 具体来说,Transformer Encoder 层的作用包括: 词嵌入(Wo
【免费】AME最新Adobe Media Encoder电脑软件安装包2024-2018支持WIN和MAC
Adobe MediaEncoder「Me」2024是一款功能强大的转码和媒体处理软件,它不仅能轻松应对各种媒体文件的编码和导出需求,还支持多种视频格式和分辨率,让你的视频处理变得更加高效。此外,该软件界面简洁明了,操作简便,即使是初学者也能快速上手。 Adobe MediaEncoder「Me」2024还支持批量处理,让你一次性完成多个文件的转码和导出,大大提高了工作效率。如果你经常需要处理大
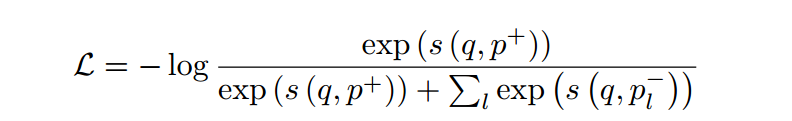
信息检索(36):ConTextual Masked Auto-Encoder for Dense Passage Retrieval
ConTextual Masked Auto-Encoder for Dense Passage Retrieval 标题摘要1 引言2 相关工作3 方法3.1 初步:屏蔽自动编码3.2 CoT-MAE:上下文屏蔽自动编码器3.3 密集通道检索的微调 4 实验4.1 预训练4.2 微调4.3 主要结果 5 分析5.1 与蒸馏检索器的比较5.2 掩模率的影响5.3 抽样策略的影响5.4 解码器

Encoder——Decoder工作原理与代码支撑
神经网络算法 :一文搞懂 Encoder-Decoder(编码器-解码器)_有编码器和解码器的神经网络-CSDN博客这篇文章写的不错,从定性的角度解释了一下,什么是编码器与解码器,我再学习+笔记补充的时候,讲一下原理+代码实现。 简单来说 编码器就是把抽象问题转化为计算机能识别计算的数学问题 解码器就是将计算机计算好的数学问题转化成为最终结果能看懂的形式 以下是一个不错的PPT图 1.
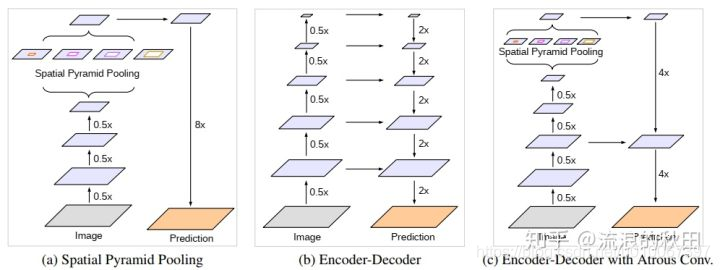
Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation
when ECCV 2018 what 空间金字塔池模块或编码 - 解码器结构用于深度神经网络中解决语义分割任务。前一种网络能够通过利用多个速率和多个有效视场的过滤器或池化操作探测输入特征来编码多尺度上下文信息,而后一种网络可以通过逐渐恢复空间信息来捕获更清晰的对象边界。在这项工作中,我们建议结合两种方法的优点。具体来说,我们提出的模型DeepLabv3 +通过添加一个简单而有效的解码
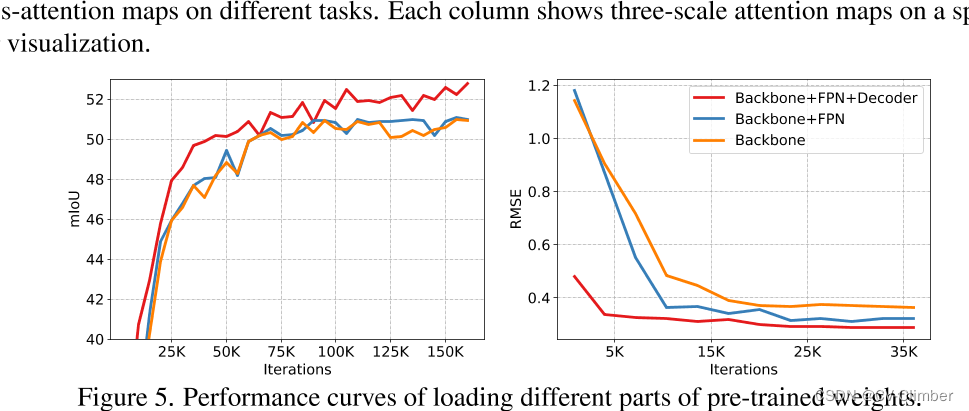
GLID: Pre-training a Generalist Encoder-Decoder Vision Model
1 研究目的 现在存在的问题是: 目前,尽管自监督预训练方法(如Masked Autoencoder)在迁移学习中取得了成功,但对于不同的下游任务,仍需要附加任务特定的子架构,这些特定于任务的子架构很复杂,需要在下游任务上从头开始训练,这使得大规模预训练的好处无法得到充分利用,制了预训练模型的通用性和效率。 为了解决这个问题,论文提出了: GLID预训练方法,该方法通过统一预训练和
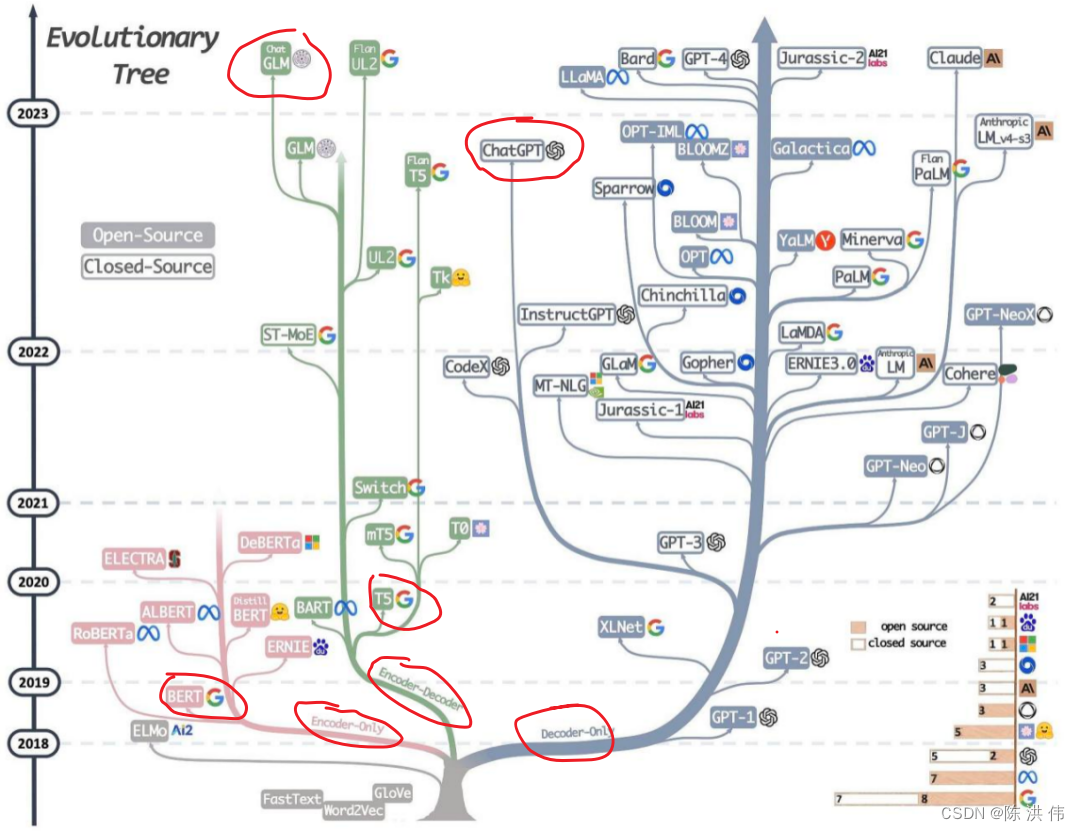
大模型LLM架构--Decoder-Only、Encoder-Only、Encoder-Decoder
目录 1 LLM演变进化树 2 每种架构的优缺点 2.1 Decoder-Only 架构 2.2 Encoder-Only 2.3 Encoder-Decoder 参考文献: 1 LLM演变进化树 基于 Transformer 模型以非灰色显示:decoder-only 模型在右边的浅蓝色分支,encoder-only 模型在粉色分支,encoder-decoder 模
深度学习体系结构——CNN, RNN, GAN, Transformers, Encoder-Decoder Architectures算法原理与应用
1. 卷积神经网络 卷积神经网络(CNN)是一种特别适用于处理具有网格结构的数据,如图像和视频的人工神经网络。可以将其视作一个由多层过滤器构成的系统,这些过滤器能够处理图像并从中提取出有助于进行预测的有意义特征。 设想你手头有一张手写数字的照片,你希望计算机能够识别出这个数字。CNN的工作原理是在图像上逐层应用一系列过滤器,每一层都能够提取出从简单到复杂的不同特征。初级过滤器负责识别图像中的基

hitfilm 导出视频 the sample Rate (XXX Hz) is not supported by encoder
解决办法:File->projectSettings中,修改sample rate 为 48000 Hz。
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
本文为论文翻译 在这个文章中,我们提出了一个新奇的神经网络模型,叫做RNN Encoder–Decoder,它包括两个RNN。一个RNN用来把一个符号序列编码为固定长度的向量表示,另一个RNN用来把向量表示解码为另外一个符号向量;提出的模型中的编码器和解码器被连接起来用于训练,目的是最大化目标序列相对于原序列的条件概率;基于经验,如果把the RNN Encoder–Decoder作为现存的lo
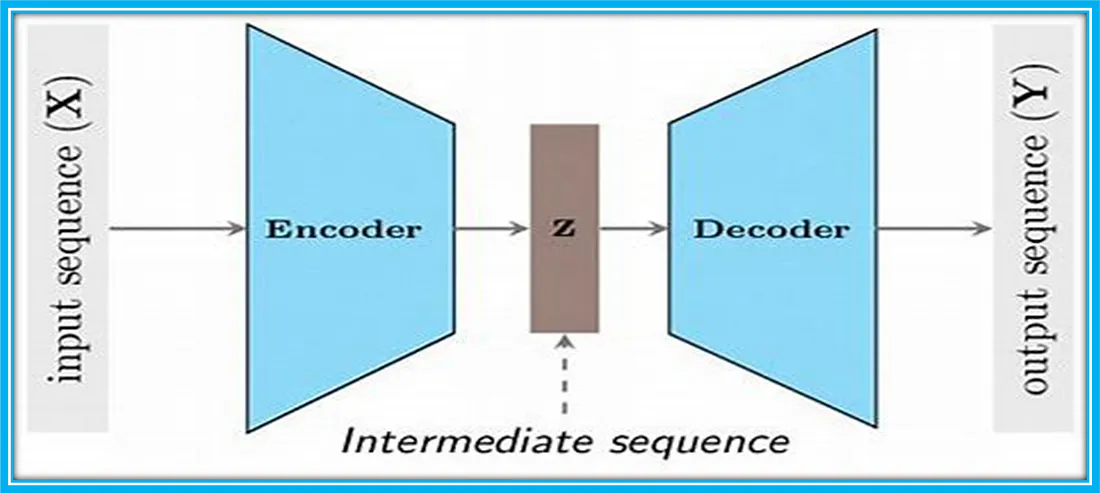
深度学习中的Encoder-Decoder框架(编码器-解码器框架)
深度学习中的Encoder-Decoder框架(编码器-解码器框架) 一、概述二、介绍 一、概述 Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图1是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。 图1 文本处理领域的Encoder-Decoder框架 二、介绍 文本处理领域的Encoder-Decod

NVIDIA视频编码器 ffmpeg -h encoder=h264_nvenc
NVIDIA视频编码器 h264_nvenc 编码配置参数 Encoder h264_nvenc [NVIDIA NVENC H.264 encoder]:General capabilities: delay hardware Threading capabilities: noneSupported pixel formats: yuv420p nv12 p010le yuv444p p01
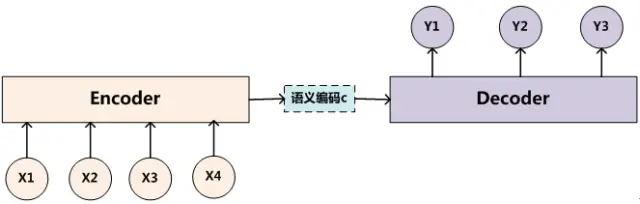
十、编码器-解码器模型(Encoder-Decoder)
参考 Encoder-Decoder 模型架构详解 编码,就是将输入序列转化成一个固定长度向量。解码,就是将之前生成的固定长度向量再转化出输出序列。 编码器-解码器有 2 点需要注意: 不管输入序列和输出序列长度是多少,中间的向量长度都是固定的。不同的任务可以选择不同的编码器和解码器 (如RNN,CNN,LSTM,GRU)。 1 序列到序列模型(Seq2Seq) Encod
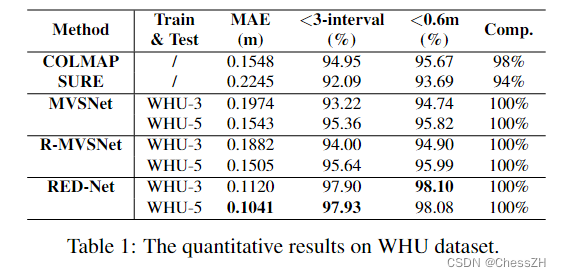
【论文阅读笔记】A Novel Recurrent Encoder-Decoder Structure for Large-Scale Multi-view Stereo Reconstruction
A Novel Recurrent Encoder-Decoder Structure for Large-Scale Multi-view Stereo Reconstruction from An Open Aerial Dataset 目录 主要贡献摘要RED-Net细节二维特征提取cost map递归编解码器正则化loss计算 实验结果 主要贡献 摘要 近年来的大量