本文主要是介绍Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

when
- ECCV 2018
what
- 空间金字塔池模块或编码 - 解码器结构用于深度神经网络中解决语义分割任务。
- 前一种网络能够通过利用多个速率和多个有效视场的过滤器或池化操作探测输入特征来编码多尺度上下文信息,而后一种网络可以通过逐渐恢复空间信息来捕获更清晰的对象边界。
- 在这项工作中,我们建议结合两种方法的优点。具体来说,我们提出的模型DeepLabv3 +通过添加一个简单而有效的解码器模块来扩展DeepLabv3,以优化分割结果,尤其是沿着对象边界。我们进一步探索Xception模型并将深度可分离卷积应用于Atrous Spatial Pyramid Pooling和解码器模块,从而产生更快更强的编码器-解码器网络。
- 我们证明了所提出的模型在PASCAL VOC 2012语义图像分割数据集上的有效性,并且在没有任何后处理的情况下在测试集上实现了89%的性能。我们的论文附有Tensorflow中提出的模型的公开参考实现。
who (动机)
-
语义分割的目的是为图像中的每个像素分配语义标签[17,25,13,83,5],这是计算机视觉中的基本主题之一。 基于完全卷积神经网络[64,49]的深度卷积神经网络[41,38,64,68,70]显示出依赖于手工制作特征的系统在基准任务上的显着改进[28,65,36,39,22,79]。在这项工作中,我们考虑使用空间金字塔池模块[23,40,26]或编码器-解码器结构[61,3]进行语义分割的两种类型的神经网络,其中前者通过在不同的分辨率上汇集特征来捕获丰富的上下文信息。而后者能够获得锐利的物体边界。
-
为了捕获多个尺度的上下文信息,DeepLabv3 [10]应用具有不同速率的几个并行的atrous卷积(称为Atrous Spatial Pyramid Pooling,或ASPP),而PSPNet [81]执行不同网格尺度的池化操作。即使在最后的特征映射中编码了丰富的语义信息,由于在网络主干内具有跨步操作的池化或卷积,因此缺少与对象边界相关的详细信息。通过应用atrous卷积来提取更密集的特征映射可以减轻这种情况。然而,考虑到现有神经网络[38,68,70,27,12]的设计和有限的GPU内存,提取比输入分辨率小8甚至4倍的输出特征映射在计算上是禁止的。以ResNet-101 [27]为例,当应用atrous卷积提取比输入分辨率小16倍的输出特征时,最后3个残余块(9层)内的特征必须扩大。更糟糕的是,如果需要比输入小8倍的输出特征,则会影响26个残余块(78层!)。因此,如果为这种类型的模型提取更密集的输出特征,则计算密集。另一方面,编码器 - 解码器模型[61,3]使其自身在编码器路径中更快地计算(因为没有特征被扩张)并且逐渐恢复解码器路径中的尖锐对象边界。试图结合两种方法的优点,我们建议通过结合多尺度上下文信息来丰富编码器 - 解码器网络中的编码器模块。
-
特别是,我们提出的模型,称为DeepLabv3 +,通过添加一个简单但有效的解码器模块来扩DeepLabv3[10],以恢复对象边界,如图1所示。丰富的语义信息在DeepLabv3的输出中进行编码,带有atrous卷积允许人们根据计算资源的预算来控制编码器特征的密度。 此外,解码器模块允许详细的对象边界恢复。
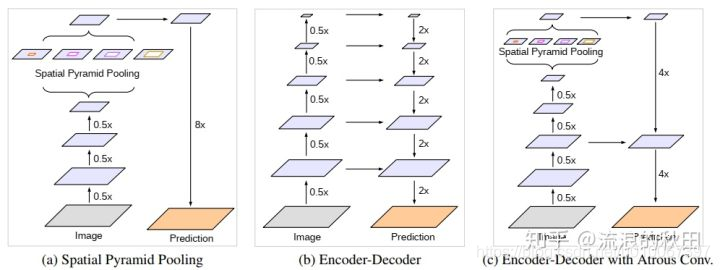
- 由于最近深度可分离卷积的成功[67,71,12,31,80],对于语义分割的任务我们也通过调整Xception模型[12]来探索这种操作,并在速度和准确性方面表现出改进,类似于[60],并将atrous可分离卷积应用于ASPP和解码器模块。最后,我们证明了所提出的模型在PASCAL VOC 2012语义分割基准测试中的有效性,并且在没有任何后处理的情况下在测试集上获得了89.0%的性能,从而创造了一种新的最新技术。
where
看点
- 实验部分写的很精彩
创新点
- 我们提出了一种新颖的编码器-解码器结构,它采用DeepLabv3作为功能强大的编码器模块和简单而有效的解码器模块。
- 在我们提出的编码器 - 解码器结构中,可以通过atrous卷积任意控制提取的编码器特征的分辨率,以折中精度和运行时间,这对于现有的编码器解码器模型是不可能的。
- 我们将Xception模型用于分割任务,并将深度可分离卷积应用于ASPP模块和解码器模块,从而产生更快更强的编码器-解码器网络。
- 我们提出的模型在PASCAL VOC 2012数据集上获得了新的最新性能。我们还提供设计选择和模型变体的详细分析。
- 我们公开提供基于Tensorflow的提议模型实现。
相关工作
这篇关于Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








