convolution专题

【tensorflow 使用错误】tensorflow2.0 过程中出现 Error : Failed to get convolution algorithm
如果在使用 tensorflow 过程中出现 Error : Failed to get convolution algorithm ,这是因为显卡内存被耗尽了。 解决办法: 在代码的开头加入如下两句,动态分配显存 physical_device = tf.config.experimental.list_physical_devices("GPU")tf.config.experiment
![[深度学习]转置卷积(Transposed Convolution)](https://img-blog.csdn.net/20171016205530158?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzI1MDQxNg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)
[深度学习]转置卷积(Transposed Convolution)
一.写在前面 在GAN(Generative Adversarial Nets, 直译为生成式对抗网络)中,生成器G利用随机噪声Z,生成数据。那么,在DCGAN中,这部分是如何实现呢?这里就利用到了Transposed Convolution(直译为转置卷积),也称为Fractional Strided Convolution。那么,接下来,从初学者的角度,用最简单的方式介绍什么是转置卷积,以及

python 实现convolution neural network卷积神经网络算法
convolution neural network卷积神经网络算法介绍 卷积神经网络(Convolutional Neural Networks, CNN)是一种包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks, FNN),是深度学习的代表算法之一。以下是关于卷积神经网络算法的详细解释: 基本原理 CNN的核心思想是通过模拟人类视觉系统的工作

每日Attention学习16——Multi-layer Multi-scale Dilated Convolution
模块出处 [CBM 22] [link] [code] Do You Need Sharpened Details? Asking MMDC-Net: Multi-layer Multi-scale Dilated Convolution Network For Retinal Vessel Segmentation 模块名称 Multi-layer Multi-scale Dilate

一文彻底搞懂CNN - 卷积和池化(Convolution And Pooling)
Convolutional Neural Network CNN(卷积神经网络)最核心的两大操作就是卷积(Convolution)和池化(Pooling)。卷积用于特征提取,通过卷积核在输入数据上滑动计算加权和;池化用于特征降维,通过聚合统计池化窗口内的元素来减少数据空间大小。 Convolution And Pooling 一、_卷积(Convolution) 卷积(Convol
改进YOLO系列 | Microsoft 团队 | Dynamic Convolution :自适应地调整卷积参数
改进YOLO系列:Microsoft团队的Dynamic Convolution——自适应调整卷积参数的计算机视觉方法(中文综述) 简介 YOLO(You Only Look Once)是一种目标检测算法,以其速度和精度著称。 本文将介绍YOLO系列的改进,包括Microsoft团队提出的Dynamic Convolution(动态卷积)。Dynamic Convolution通过自适应调整卷
convolution backbone network——GCNet
GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond paper: https://arxiv.org/pdf/1904.11492.pdf github: https://github.com/xvjiarui/GCNet 单位: 清华,香港科技大学,微软 摘要: 非局域网(NLNet)通过将查询特定的全局上

点云语义分割:论文阅读简记 -Spatial Transformer Point Convolution
[1] Spatial Transformer Point Convolution 为了满足点云置换不变性问题,以往的方法通过max或者sum来进行特征聚合,但是这种操作是各向同的,不能更好的建模局部几何结构。本文提出spatial transformer point convolution试图实现各相异性的滤波器。引入空间方向字典来捕获点云的几何结构。利用方向字典学习将无序的邻居转换成规范有序
cubic convolution interpolation (三次卷积插值)
算法来源:Cubic convolution interpolation for digital image processing 文章只对一维情形进行分析,二维类似。 许多插值函数能够写成形式(其中是插值点,u是基函数(文章中叫插值核),h是采样间隔,是参数) 通过插值,用来近似。 cubic convolution interpolation 中插值核u定义为子区间(-2,
【图像超分】论文精读:Deep Convolution Networks for Compression Artifacts Reduction(ARCNN)
第一次来请先看这篇文章:【超分辨率(Super-Resolution)】关于【超分辨率重建】专栏的相关说明,包含专栏简介、专栏亮点、适配人群、相关说明、阅读顺序、超分理解、实现流程、研究方向、论文代码数据集汇总等) 文章目录 前言Abstract1. IntroductionII. RELATED WORKIII. METHODOLOGYA. Review of SRCNNB. Convo
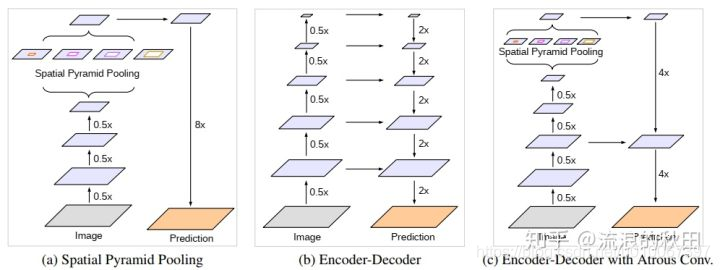
Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation
when ECCV 2018 what 空间金字塔池模块或编码 - 解码器结构用于深度神经网络中解决语义分割任务。前一种网络能够通过利用多个速率和多个有效视场的过滤器或池化操作探测输入特征来编码多尺度上下文信息,而后一种网络可以通过逐渐恢复空间信息来捕获更清晰的对象边界。在这项工作中,我们建议结合两种方法的优点。具体来说,我们提出的模型DeepLabv3 +通过添加一个简单而有效的解码

Revisiting-Dilated-Convolution-A-Simple-Approach-for-Weakly-and-Semi-Supervised
when 魏云超组的18年cvpr spot who 弱监督语义分割问题的新方法,用扩张卷积得到注意力图,可能能够在GAIN的大框架上面修改 why 提出 尽管弱监督分割方法取得了显着的进步,但仍然不如全监督的方法。我们认为性能差距主要来自他们学习从图像级监督产生高质量密集对象定位图的限制。为了弥补这种差距,我们重新审视了空洞卷积[1]并揭示了如何以一种新颖的方式利用它来有效地克服弱
Convolution Networks 和Deconvolution Networks
一.卷积的概念 卷积是分析数学中的一种重要运算,英文convolution。需要注意的是,以下我们考虑都是离散情况下的卷积操作。从概念上说,卷积是线性情况的下的滤波处理,性滤波处理经常被称为“掩码与图像的卷积”[1]。具体的操作则是,卷积是两个变量在某范围内相乘后求和的结果。如果卷积的变量是序列x(n)和h(n),则卷积的结果。 其中*表示卷积。 那对于二维图像上的卷积操作,是计
deep_learning_month4_week1_convolution_model_step_by_step
deep_learning_month4_week1_convolution_model_step_by_step 标签: 机器学习深度学习 代码已上传github: https://github.com/PerfectDemoT/my_deeplearning_homework 说明:本文解释了如何一步步建立CNN的卷积层,不过只包含一步步建立的函数,并没有形成一个能够使用的模型,如

论文阅读:Adaptive Graph Convolution for Point Cloud analysis
自适应图卷积用于点云分析 论文地址: https://arxiv.org/pdf/2108.08035. 代码地址: https://github.com/hrzhou2/AdaptConv-master. 作者:Zhou Haoran 单位:南京航空航天大学 作为初入图卷积网络的小白,我就根据自己的理解来读这篇文章。 摘要: 问题:从二维网格域推广出来的三维点云的卷积已被广泛研究,但远

语义分割--PANet和Understanding Convolution for Semantic Segmentation
语义分割 PAN Pyramid Attention Network for Semantic Segmentation FCN作为backbone的结构对小型目标预测不佳,论文认为这存在两个挑战。 物体因为多尺度的原因,造成难以分类。针对这个问题,PSPNet和DeepLab引入了PSP和ASPP模块引入多尺度信息。论文引入了像素级注意力用于帮助提取精准的high-level 特征。**h

Dilated Convolution膨胀卷积感受野详解
重温Dilated Convolution膨胀卷积,对论文《MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS》中采用Dilation后的感受野计算示意图产生了迷惑,于是自己重新画图琢磨了一番。 可以看到作者的感受野计算是递进式的,即F1在F0的基础上经3x3,dilation=1卷积得到,即F2在F1的基础上经3x3,dilation

CNN中难点分析--对卷积层(Convolution)与池化层(Pooling)的理解
传统机器学习通过特征工程提取特征,作为Input参数进行输入,从而拟合一个相对合适的w参数,而CNN利用卷积层感知局部特征,然后更高层次对局部进行综合操作,从而得到全局信息,池化层层提取主要特征,从而自动提取特征。 1、池化层的理解 pooling池化的作用则体现在降采样:保留显著特征、降低特征维度,增大kernel的感受野。另外一点值得注意:pooling也可以提供一些旋转不变性。 池化

2D image convolution(二维图像卷积)
在学习cnn的过程中,对convolution的概念真的很是模糊,本来在学习图像处理的过程中,已对convolution有所了解,它与correlation是有不同的,因为convolution = correlation + filp over in both horizontal + vertical 但在CNN中,明明只是进行了correlation,但却称之为convolution,实在

theano中对图像进行convolution 运算
(1) 定义计算过程中需要的symbolic expression 1 """ 2 定义相关的symbolic experssion 3 """ 4 # convolution layer的输入,根据theano,它应该是一个4d tensor 5 input = T.tensor4(name='input') 6 # 共享权值W,它的shape为2,3,9,9 7 w_sh

UniFormer: Unifying Convolution and Self-attention for Visual Recognition
paper链接: https://arxiv.org/abs/2201.09450 UniFormer: Unifying Convolution and Self-attention for Visual Recognition 一、引言二、实现细节(一)、Local MHRA(二)、全局MHR(三)、动态位置嵌入 三、框架设计四、实验(一)、图像分类(二)、视频分类(三)、目标检测(三)
[HDU6057]Kanade’s convolution
Kanade's convolution 题解 我们要求的式子是。 长得极其丑陋。。。 于是我们考虑将其变形一下,令,于是条件。因为y有的1的位置x肯定都有,所以。由于可以构成这样的数对的数对总共有个,我们需要在加时乘上一个。并且加上满足条件。 于是原式就成了 。看起来好像FWT呀,可是这个条件该怎么做呢? 我们发现由于x,y它们之间的关系并且,故。而与又可以代表它里面1的个数,我们

Sparse Convolution 讲解
文章目录 1. 标准卷积与Sparse Conv对比(1)普通卷积(2) 稀疏卷积(3) 改进的稀疏卷积(subm) 2 Sparse Conv 官方API3. Sparse Conv 计算3. 1 Sparse Conv 计算流程3. 2 案例3.2.1 普通稀疏卷积3.2.2 subm模式的稀疏卷积 3D点云数据非常稀疏,尤其体素化处理后(比如200k的点放在1440 1

Convolution-CNN卷积
Convolution-CNN卷积 文章目录 Convolution-CNN卷积CNN总览Conv层的作用Conv就是FC去掉部分链接!Flatten 参考 CNN总览 可以看到,对于一张图片,CNN首先要做的事Conv(卷积)+Max Pooling(池化),用以提取特征,然后经过Flatten之后扔到FC(全链接)里面做分类。 Conv层的作用 首先

YOLOv9独家原创改进|加入幽灵卷积Ghost Convolution模块,轻量化!
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,主力高效涨点!!! 一、论文摘要 由于内存和计算资源有限,在嵌入式设备上部署卷积神经网络是困难的。特征图中的冗余是那些成功的细胞神经网络的一个重要特征,但在神经结构设计中很少进行研究。本文提出了一种新的Ghost模块,通过少量的计算生成更多的特征图。基于一组内在特征图,我们以低廉的成本应用一系列线性变换来

【CVPR2021】Dynamic Region-Aware Convolution
论文:https://arxiv.org/pdf/2003.12243.pdf 代码:https://github.com/shallowtoil/DRConv-PyTorch (非官方实现) 这个论文的核心词是:动态网络。作者认为,传统卷积对于不同样本使用相同的 filter,如果能够对不同区域的特征使用不同的卷积核可以显著提升特征表达能力。如下图所示,把图像分割为不同区域,对不同区