decoder专题

人工智能-机器学习-深度学习-自然语言处理(NLP)-生成模型:Seq2Seq模型(Encoder-Decoder框架、Attention机制)
我们之前遇到的较为熟悉的序列问题,主要是利用一系列输入序列构建模型,预测某一种情况下的对应取值或者标签,在数学上的表述也就是通过一系列形如 X i = ( x 1 , x 2 , . . . , x n ) \textbf{X}_i=(x_1,x_2,...,x_n) Xi=(x1,x2,...,xn) 的向量序列来预测 Y Y Y 值,这类的问题的共同特点是,输入可以是一个定长或者不

NLP-生成模型-2017-Transformer(一):Encoder-Decoder模型【非序列化;并行计算】【O(n²·d),n为序列长度,d为维度】【用正余弦函数进行“绝对位置函数式编码”】
《原始论文:Attention Is All You Need》 一、Transformer 概述 在2017年《Attention Is All You Need》论文里第一次提出Transformer之前,常用的序列模型都是基于卷积神经网络或者循环神经网络,表现最好的模型也是基于encoder- decoder框架的基础加上attention机制。 2018年10月,Google发出一篇

【MIT-BEVFusion代码解读】第四篇:融合特征fuser和解码特征decoder
文章目录 1. fuser模块2. decoder模块2.1 backbone模块2.2 neck模块 BEVFusion相关的其他文章链接: 【论文阅读】ICRA 2023|BEVFusion:Multi-Task Multi-Sensor Fusion with Unified Bird‘s-Eye View RepresentationMIT-BEVFusion训练
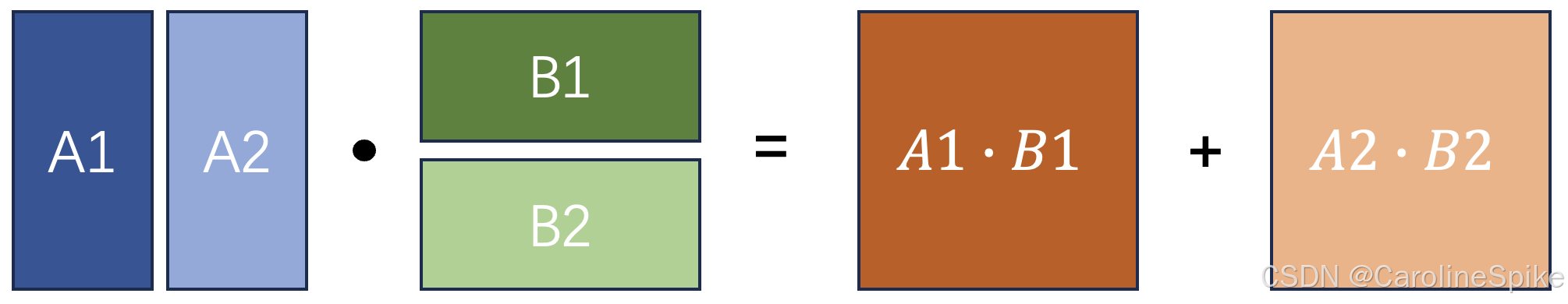
LLM - GPT(Decoder Only) 类模型的 KV Cache 公式与原理 教程
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/141605718 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 在 GPT 类模型中,KV Cache (键值缓存) 是用于优化推理效率的重要技术,基本思想是通过缓存先
seq2seq编码器encoder和解码器decoder详解
编码器 在序列到序列模型中,编码器将输入序列(如一个句子)转换为一个隐藏状态序列,供解码器生成输出。编码层通常由嵌入层和RNN(如GRU/LSTM)等组成 Token:是模型处理文本时的基本单元,可以是词,子词,字符等,每个token都有一个对应的ID。是由原始文本中的词或子词通过分词器(Tokenizer)处理后得到的最小单位,这些 token 会被映射为词汇表中的唯一索引 ID输入: 原始

《A DECODER-ONLY FOUNDATION MODEL FOR TIME-SERIES FORECASTING》阅读总结
介绍了一个名为TimeFM的新型时间序列预测基础模型,该模型受启发于自然语言处理领域的大语言模型,通过再大规模真实世界和合成时间序列数据集上的预训练,能够在多种不同的公共数据集上实现接近最先进监督模型的零样本预测性能。 该模型使用真实世界和合成数据集构建的大型时间序列语料库进行预训练,并展示了在不同领域、预测范围和时间粒度的未见数据集上的准确零样本预测能力。 1、引言 时间序列在零售、金融、
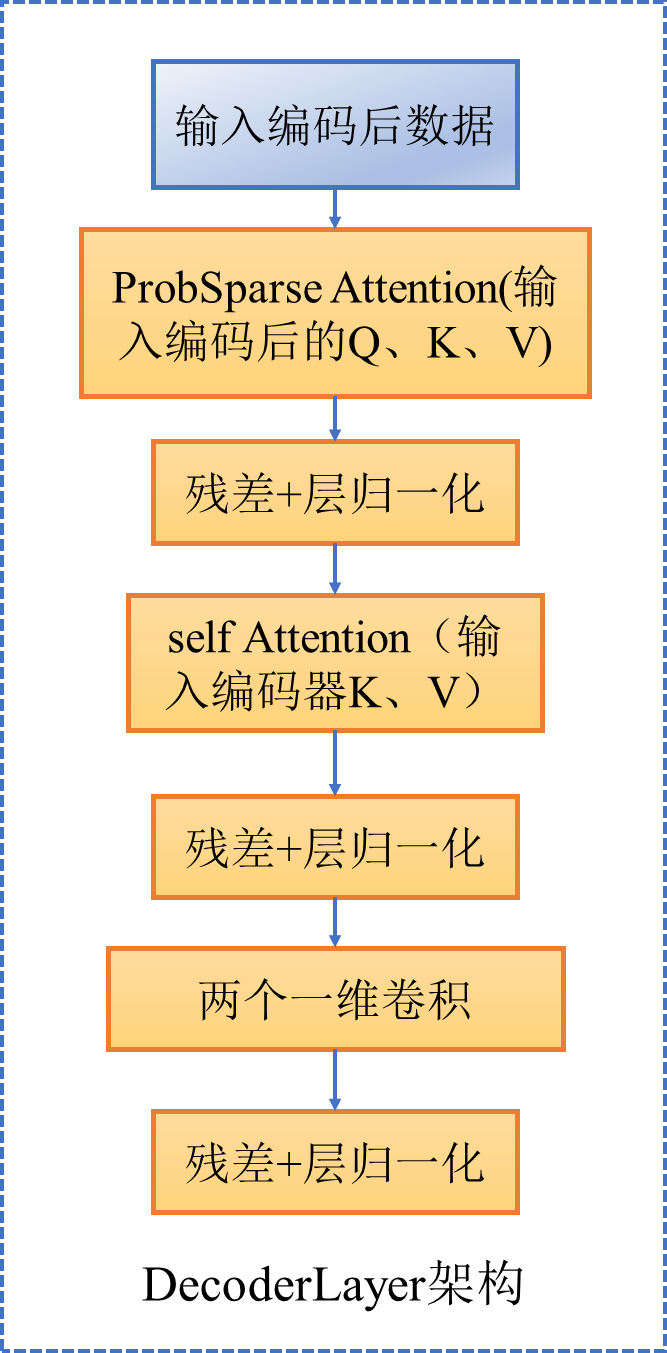
深度学习算法informer(时序预测)(四)(Decoder)
一、DecoderLayer架构如图(不改变输入形状) 二、Decoder整体 包括两部分 1. 多层DecoderLayer 2. 层归一化 代码如下 class DecoderLayer(nn.Module):def __init__(self, self_attention, cross_attention, d_model, d_ff=None,dropout=0.
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读
LLMs:《A Decoder-Only Foundation Model For Time-Series Forecasting》的翻译与解读 导读:本文提出了一种名为TimesFM的时序基础模型,用于零样本学习模式下的时序预测任务。 背景痛点:近年来,深度学习模型在有充足训练数据的情况下已成为时序预测的主流方法,但这些方法通常需要独立在每个数据集上训练。同时,自然语言处理领域的大规模预训练

Transformer系列:图文详解Decoder解码器原理
从本节开始本系列将对Transformer的Decoder解码器进行深入分析。 内容摘要 Encoder-Decoder框架简介shifted right移位训练解码器的并行训练和串行预测解码器自注意力层和掩码解码器交互注意力层和掩码解码器输出和损失函数 Encoder-Decoder框架简介 在原论文中Transformer用于解决机器翻译任务,机器翻译这种Seq2Seq问题通常

You Only Cache Once:YOCO 基于Decoder-Decoder 的一个新的大语言模型架构
这是微软再5月刚刚发布的一篇论文提出了一种解码器-解码器架构YOCO,因为只缓存一次KV对,所以可以大量的节省内存。 以前的模型都是通过缓存先前计算的键/值向量,可以在当前生成步骤中重用它们。键值(KV)缓存避免了对每个词元再次编码的过程,这样可以大大提高了推理速度。 但是随着词元数量的增加,KV缓存占用了大量GPU内存,使得大型语言模型的推理受到内存限制。所以论文的作者改进了这一架构: Y

Minified React error #152; visit https://reactjs.org/docs/error-decoder.html?
文章目录 问题描述报错原因解决感谢 问题描述 今天修改了个 React 项目,部署到线上的时候报了个错误,报错信息如下: 报错原因 return 后面是不可以直接写注释的 解决 删掉、或者移动 return 后的注释 // 正则表达式\(\s*\n?\s*// 我的截图: 感谢 百度了一下,从 这个帖子 里找到的答案,大哥牛逼。

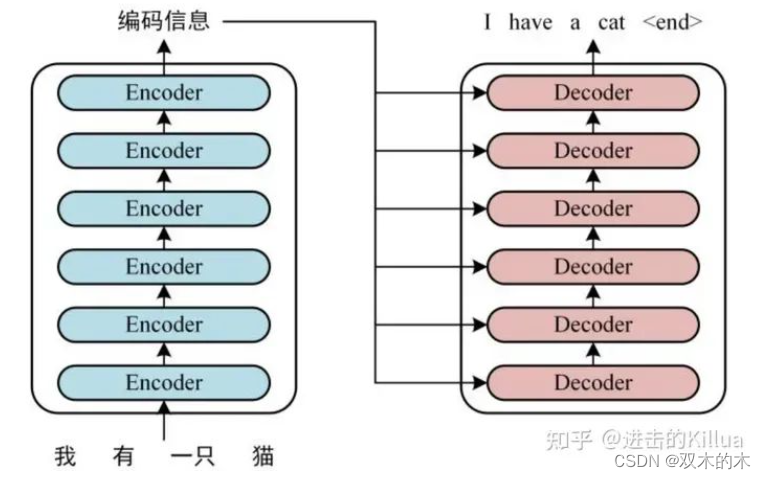
Encoder——Decoder工作原理与代码支撑
神经网络算法 :一文搞懂 Encoder-Decoder(编码器-解码器)_有编码器和解码器的神经网络-CSDN博客这篇文章写的不错,从定性的角度解释了一下,什么是编码器与解码器,我再学习+笔记补充的时候,讲一下原理+代码实现。 简单来说 编码器就是把抽象问题转化为计算机能识别计算的数学问题 解码器就是将计算机计算好的数学问题转化成为最终结果能看懂的形式 以下是一个不错的PPT图 1.
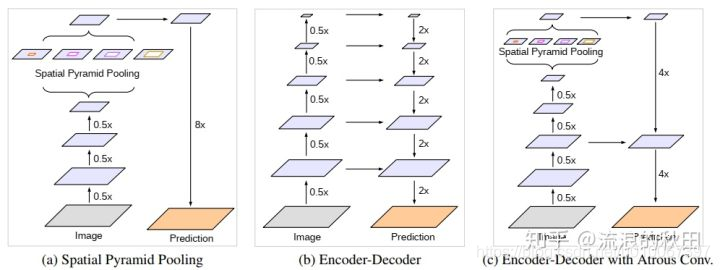
Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation
when ECCV 2018 what 空间金字塔池模块或编码 - 解码器结构用于深度神经网络中解决语义分割任务。前一种网络能够通过利用多个速率和多个有效视场的过滤器或池化操作探测输入特征来编码多尺度上下文信息,而后一种网络可以通过逐渐恢复空间信息来捕获更清晰的对象边界。在这项工作中,我们建议结合两种方法的优点。具体来说,我们提出的模型DeepLabv3 +通过添加一个简单而有效的解码
GiantPandaCV | FasterTransformer Decoding 源码分析(二)-Decoder框架介绍
本文来源公众号“GiantPandaCV”,仅用于学术分享,侵权删,干货满满。 原文链接:FasterTransformer Decoding 源码分析(二)-Decoder框架介绍 作者丨进击的Killua 来源丨https://zhuanlan.zhihu.com/p/669303360 编辑丨GiantPandaCV Decoder模块是FasterTransformer Deco

【Transformer】detr之decoder逐行梳理(三)
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?type=blog 0. 前言 detr之decoder逐行梳理 1. 整体 decoder由多个decoder layer串联构成 输入 tgt: query是一个shape为(n,bs,embed
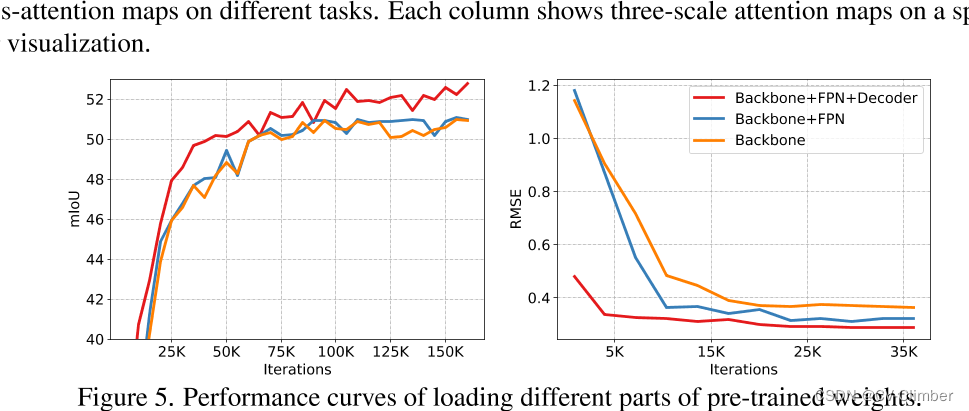
GLID: Pre-training a Generalist Encoder-Decoder Vision Model
1 研究目的 现在存在的问题是: 目前,尽管自监督预训练方法(如Masked Autoencoder)在迁移学习中取得了成功,但对于不同的下游任务,仍需要附加任务特定的子架构,这些特定于任务的子架构很复杂,需要在下游任务上从头开始训练,这使得大规模预训练的好处无法得到充分利用,制了预训练模型的通用性和效率。 为了解决这个问题,论文提出了: GLID预训练方法,该方法通过统一预训练和
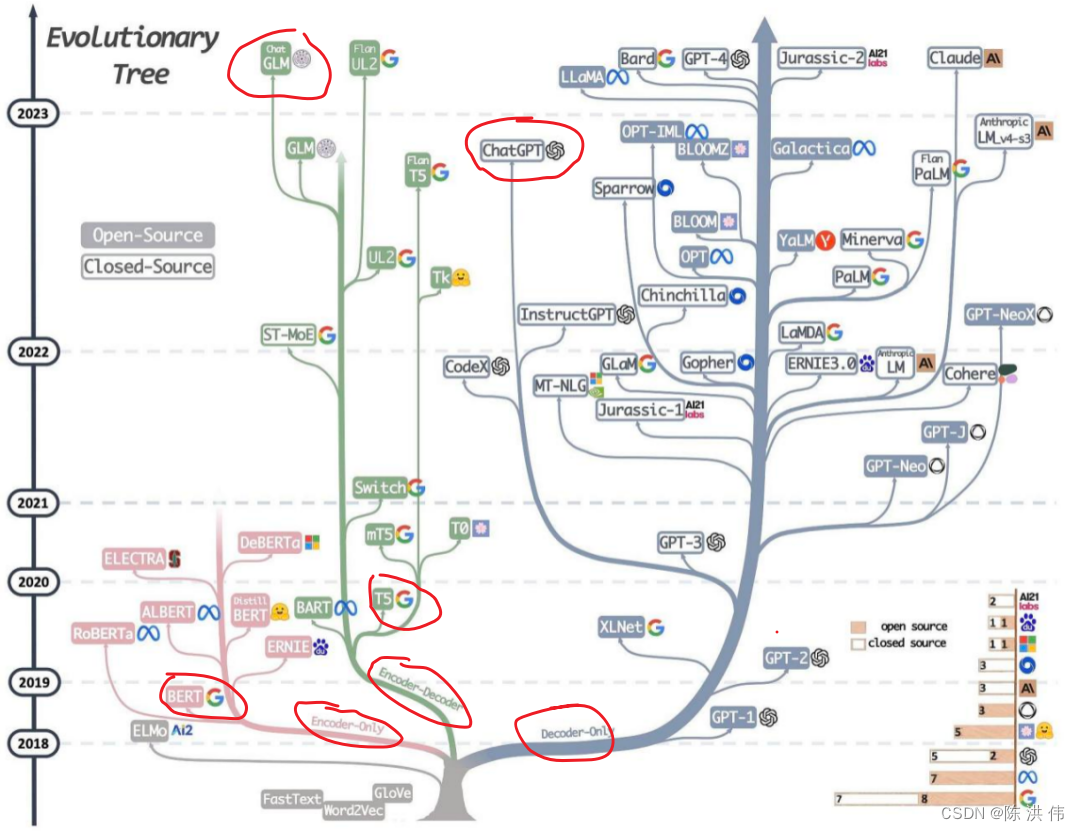
大模型LLM架构--Decoder-Only、Encoder-Only、Encoder-Decoder
目录 1 LLM演变进化树 2 每种架构的优缺点 2.1 Decoder-Only 架构 2.2 Encoder-Only 2.3 Encoder-Decoder 参考文献: 1 LLM演变进化树 基于 Transformer 模型以非灰色显示:decoder-only 模型在右边的浅蓝色分支,encoder-only 模型在粉色分支,encoder-decoder 模
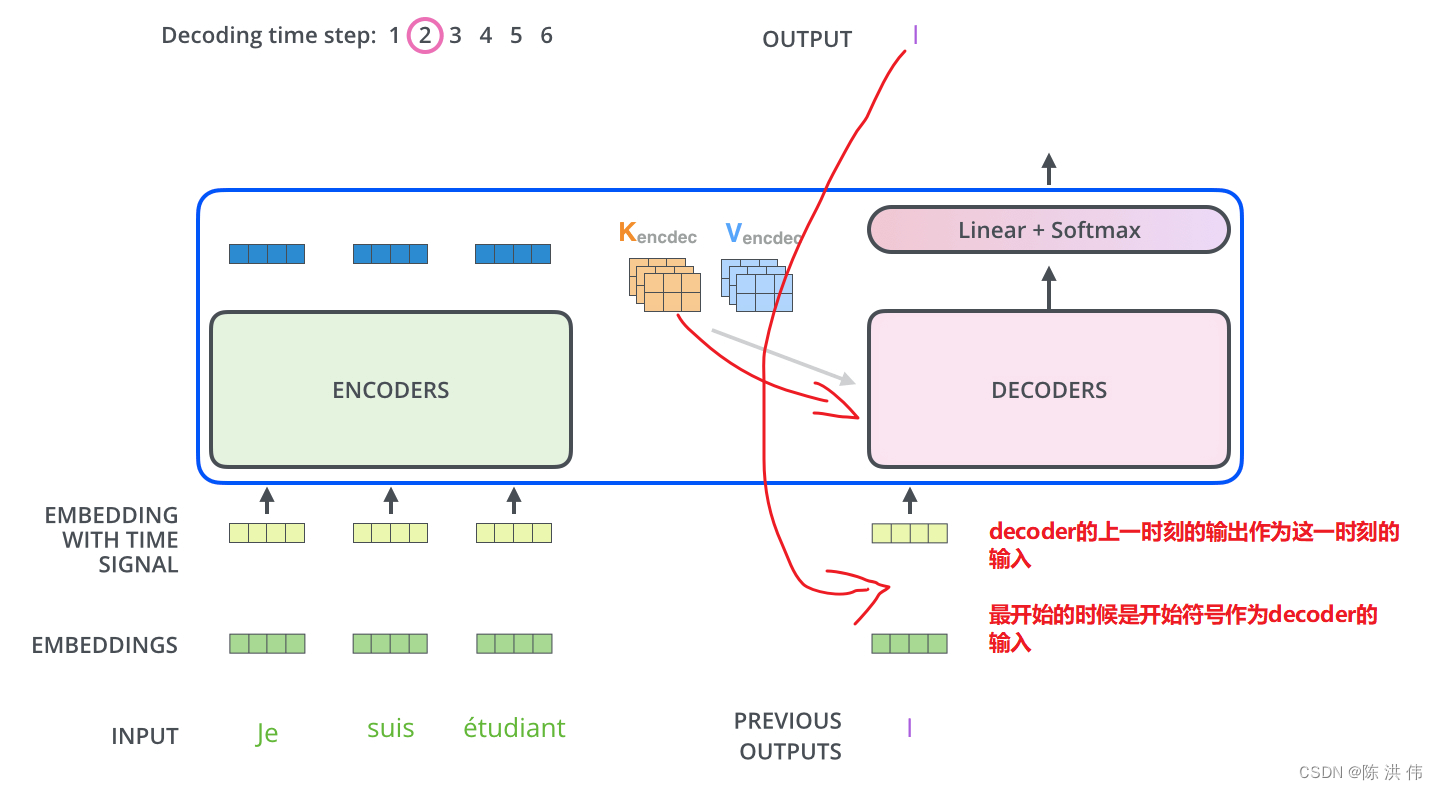
Transformer的Decoder的输入输出都是什么
目录 1 疑问:Transformer的Decoder的输入输出都是什么 2 推理时Transformer的Decoder的输入输出 2.1 推理过程中的Decoder输入输出 2.2 整体右移一位 3 训练时Decoder的输入 参考文献: 1 疑问:Transformer的Decoder的输入输出都是什么 几乎所有介绍transformer的文章中都有下面这个图
深度学习体系结构——CNN, RNN, GAN, Transformers, Encoder-Decoder Architectures算法原理与应用
1. 卷积神经网络 卷积神经网络(CNN)是一种特别适用于处理具有网格结构的数据,如图像和视频的人工神经网络。可以将其视作一个由多层过滤器构成的系统,这些过滤器能够处理图像并从中提取出有助于进行预测的有意义特征。 设想你手头有一张手写数字的照片,你希望计算机能够识别出这个数字。CNN的工作原理是在图像上逐层应用一系列过滤器,每一层都能够提取出从简单到复杂的不同特征。初级过滤器负责识别图像中的基

Transformer模型-decoder解码器,target mask目标掩码的简明介绍
今天介绍transformer模型的decoder解码器,target mask目标掩码 背景 解码器层是对前面文章中提到的子层的包装器。它接受位置嵌入的目标序列,并将它们通过带掩码的多头注意力机制传递。使用掩码是为了防止解码器查看序列中的下一个标记。它迫使模型仅使用之前的标记作为上下文来预测下一个标记。然后,它再通过另一个多头注意力机制,该机制将编码器层的输出作为额外的输入。最后,它

Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
本文为论文翻译 在这个文章中,我们提出了一个新奇的神经网络模型,叫做RNN Encoder–Decoder,它包括两个RNN。一个RNN用来把一个符号序列编码为固定长度的向量表示,另一个RNN用来把向量表示解码为另外一个符号向量;提出的模型中的编码器和解码器被连接起来用于训练,目的是最大化目标序列相对于原序列的条件概率;基于经验,如果把the RNN Encoder–Decoder作为现存的lo
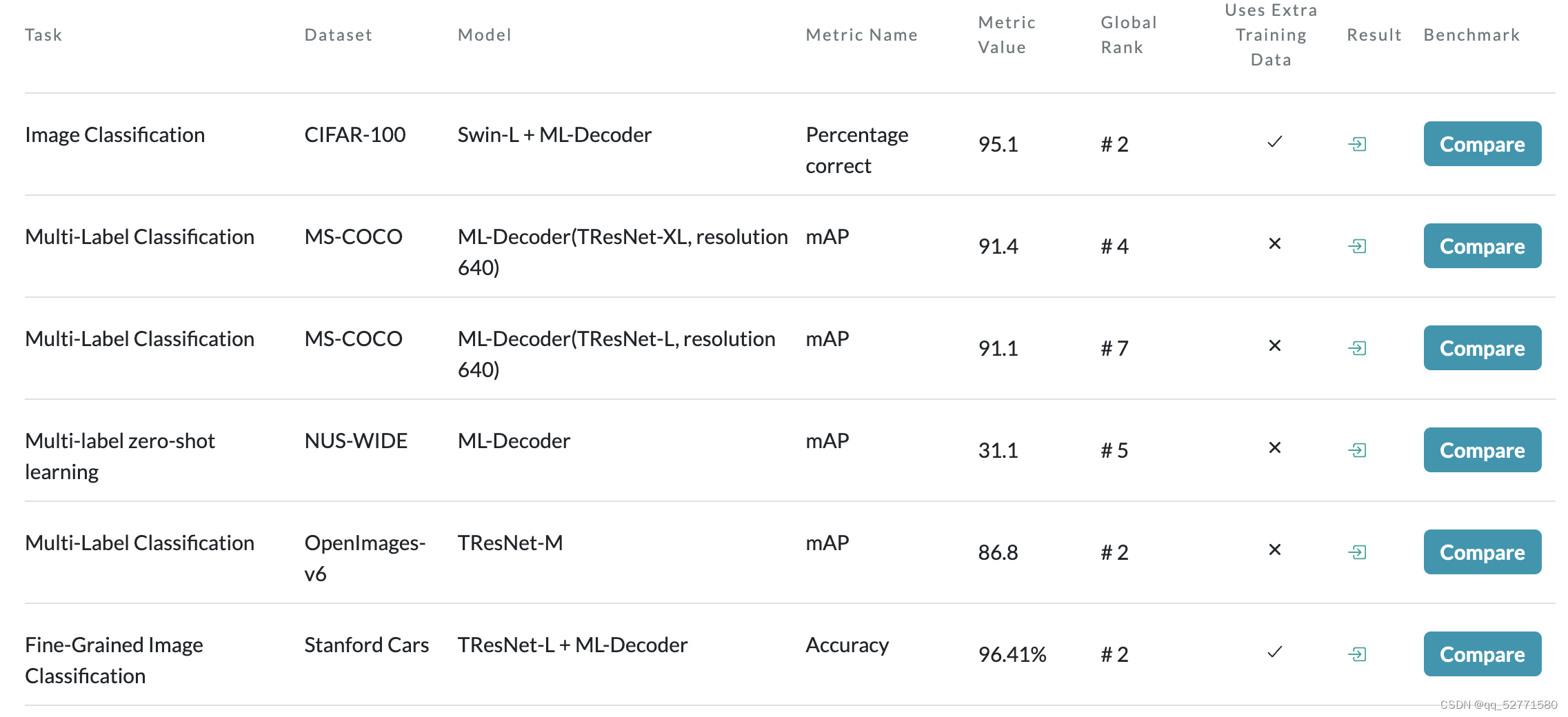
ML-Decoder: Scalable and Versatile Classification Head
1、引言 论文链接:https://openaccess.thecvf.com/content/WACV2023/papers/Ridnik_ML-Decoder_Scalable_and_Versatile_Classification_Head_WACV_2023_paper.pdf 因为 transformer 解码器分类头[1] 在少类别多标签分类数据集上表现得很好,但
silk-v3-decoder将sil转为mp3
一、新建临时目录 新建临时目录,可自定义,本次新建目录为 /opt/packages mkdir /opt/packages 二、下载、安装lame # cd /opt/packages# wget http://downloads.sourceforge.net/lame/lame-3.100.tar.gz# tar -zxvf lame-3.100.tar.gz# cd lame-3
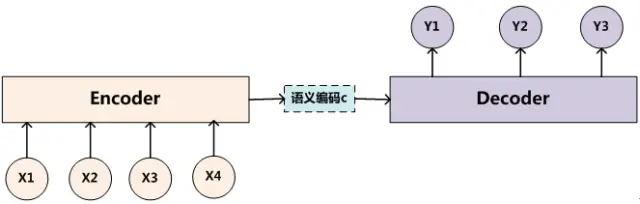
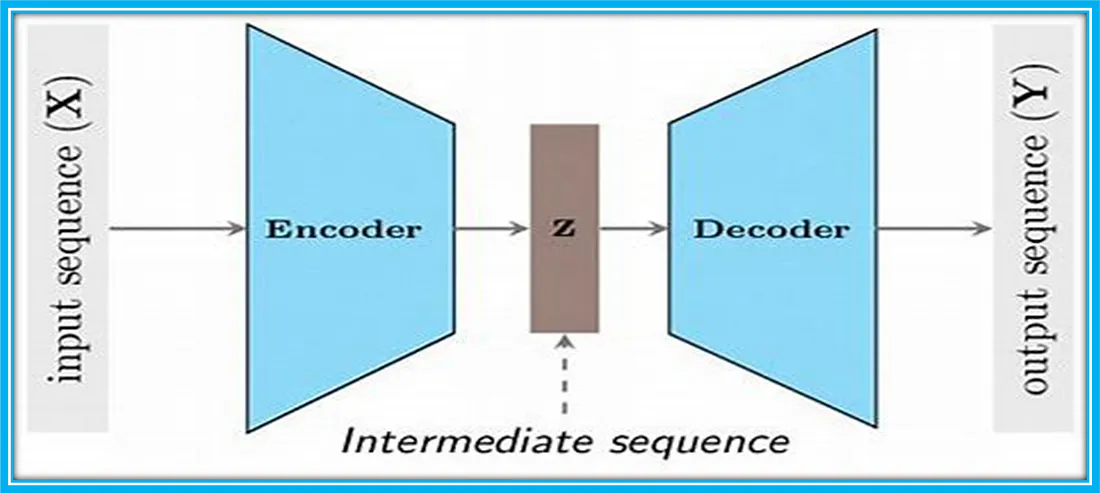
深度学习中的Encoder-Decoder框架(编码器-解码器框架)
深度学习中的Encoder-Decoder框架(编码器-解码器框架) 一、概述二、介绍 一、概述 Encoder-Decoder框架可以看作是一种深度学习领域的研究模式,应用场景异常广泛。图1是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示。 图1 文本处理领域的Encoder-Decoder框架 二、介绍 文本处理领域的Encoder-Decod
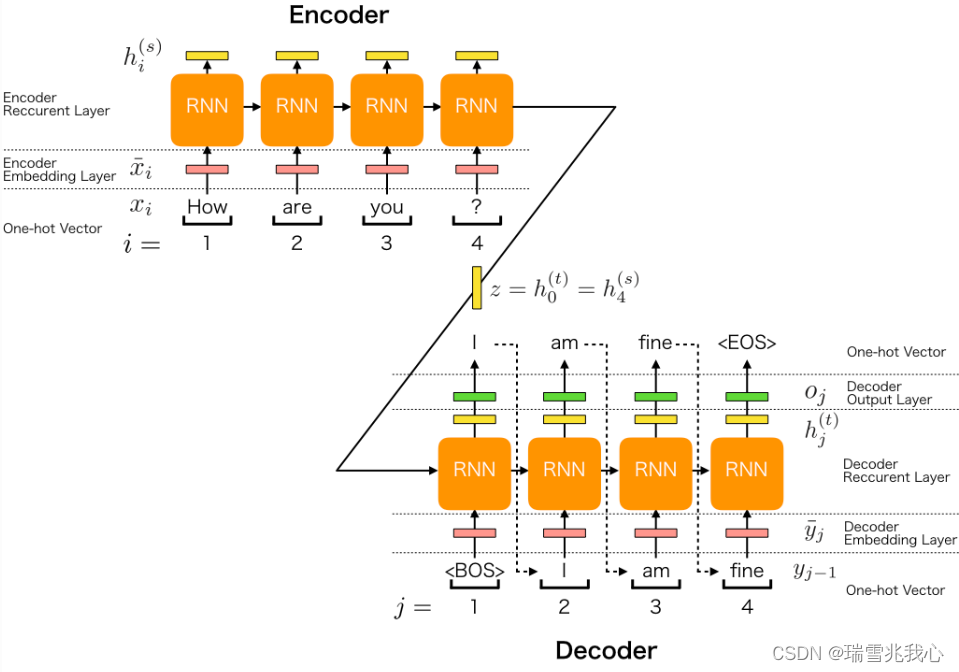
十、编码器-解码器模型(Encoder-Decoder)
参考 Encoder-Decoder 模型架构详解 编码,就是将输入序列转化成一个固定长度向量。解码,就是将之前生成的固定长度向量再转化出输出序列。 编码器-解码器有 2 点需要注意: 不管输入序列和输出序列长度是多少,中间的向量长度都是固定的。不同的任务可以选择不同的编码器和解码器 (如RNN,CNN,LSTM,GRU)。 1 序列到序列模型(Seq2Seq) Encod
Decoder API
public class Decoder extends AbstractDecoder 原始解码器类。 @S4Integer(defaultValue= 100000) public final static String PROP_FEATURE_BLOCK_SIZE ="featureBlockSize"; private int featureBlockSize;定