separable专题
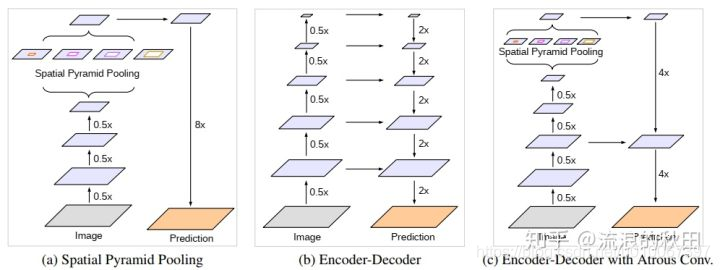
Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation
when ECCV 2018 what 空间金字塔池模块或编码 - 解码器结构用于深度神经网络中解决语义分割任务。前一种网络能够通过利用多个速率和多个有效视场的过滤器或池化操作探测输入特征来编码多尺度上下文信息,而后一种网络可以通过逐渐恢复空间信息来捕获更清晰的对象边界。在这项工作中,我们建议结合两种方法的优点。具体来说,我们提出的模型DeepLabv3 +通过添加一个简单而有效的解码

Deep separable convolutional network for remaining useful life prediction of machinery
文章目录 BackgroundMethod ProposedDS模型SE模块可分离的卷积构件DSCN构架 Experiment评价指标:数据预处理z-score划窗: 实验结果 Background 数据驱动的剩余寿命预测(RUL)主要包括:数据采集,特征提取和选择,退化行为学习和RUL 目前基于深度学习的机械RUL存在两个问题: 1、过分依赖于手工提取的特征。 2、没有考虑
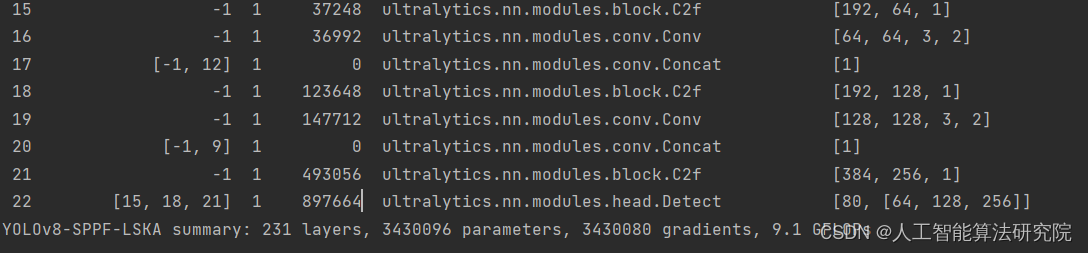
YOLOv8算法改进【NO.92】使用大核分离卷积注意力模块Large Separable Kernel Attention(LSKA)改进SPPF模块
前 言 YOLO算法改进系列出到这,很多朋友问改进如何选择是最佳的,下面我就根据个人多年的写作发文章以及指导发文章的经验来看,按照优先顺序进行排序讲解YOLO算法改进方法的顺序选择。具体有需求的同学可以私信我沟通: 第一,创新主干特征提取网络,将整个Backbone改进为其他的网络,比如这篇文章中的整个方法,直接将Backbone替换掉,理由是这种改进如果有效果,那么改进点就很

深度学习中组卷积(Group convolution)、深度卷积(Depthwise Convolution)以及深度可分离卷积(Depthwise Separable Convolution)的区别
在轻量化网络中,经常使用组卷积、深度卷积或是深度可分离卷积来降低FLOPs,那么三者的区别在哪里呢?下面总结一下。 一、标准卷积 下面是用一个卷积核对输入特征做一次卷积,得到的输出特征的通道为1。 二、组卷积 组卷积是将输入特征按通道分为g组,每组特征中的通道数为 C i n g \frac{C_{in}}{g} gCin,所以相应的卷积核的大小也变了,通道数变少了。每次卷积后的特征按通

轻量化网络(四)Xception: Deep Learning with Depthwise Separable Convolutions
论文链接 Pytorch实现 Tensorflow实现 Xception是2017年由Keras作者和谷歌著名人工智能专家Francois Chollet提出,是在 Inception modules 进行改进。Xception和Inception V3相比,网络参数并没有增加,只是更加合理得使用了参数导致了性能的提升。 一、The Inception hypothesis 在Figure 1中

深入浅出理解深度可分离卷积(Depthwise Separable Convolution)
一、参考资料 详细且通俗讲解轻量级神经网络——MobileNets【V1、V2、V3】 详细且通俗讲解轻量级神经网络——MobileNets【V1、V2、V3】 卷积神经网络中的Separable Convolution 深度学习中常用的几种卷积(下篇):膨胀卷积、可分离卷积(深度可分离、空间可分离)、分组卷积(附Pytorch测试代码) 二、相关介绍 1. 标准卷积 标准卷积,利用若干个

【读点论文】Separable Self-attention for Mobile Vision Transformers,通过引入隐变量将Q矩阵和K矩阵的算数复杂度降低成线性复杂度,分步计算注意力。
Separable Self-attention for Mobile Vision Transformers Abstract 移动视觉transformer(MobileViT)可以在多个移动视觉任务中实现最先进的性能,包括分类和检测。虽然这些模型的参数较少,但与基于卷积神经网络的模型相比,它们具有较高的延迟。MobileViT的主要效率瓶颈是transformer中的多头自我注意(MH