本文主要是介绍信息检索(36):ConTextual Masked Auto-Encoder for Dense Passage Retrieval,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ConTextual Masked Auto-Encoder for Dense Passage Retrieval
- 标题
- 摘要
- 1 引言
- 2 相关工作
- 3 方法
- 3.1 初步:屏蔽自动编码
- 3.2 CoT-MAE:上下文屏蔽自动编码器
- 3.3 密集通道检索的微调
- 4 实验
- 4.1 预训练
- 4.2 微调
- 4.3 主要结果
- 5 分析
- 5.1 与蒸馏检索器的比较
- 5.2 掩模率的影响
- 5.3 抽样策略的影响
- 5.4 解码器层数的影响
- 5.5 解码器权重初始化的影响
- 5.6 定性分析
- 6 结论和未来工作
原文链接:https://arxiv.org/abs/2208.07670
(2023)
标题
上下文 mask
自编码器
摘要
self-supervised masked AE 建模 text 内部 token 的语义
context-supervised masked AE 建模 text 之间的语义
密集段落检索旨在基于查询和段落的密集表示(即向量)从大型语料库中检索查询的相关段落。最近的研究探索了改进预训练语言模型以提高密集检索性能。本文提出了 CoT-MAE(ConTextual Masked Auto-Encoder),这是一种简单而有效的用于密集段落检索的生成预训练方法。 CoT-MAE 采用非对称编码器解码器架构,学习通过自监督和上下文监督的屏蔽自动编码将句子语义压缩为密集向量。准确地说,自监督屏蔽自动编码学习对文本范围内标记的语义进行建模,上下文监督屏蔽自动编码学习对文本范围之间的语义相关性进行建模。我们在大规模段落检索基准上进行了实验,并显示出相对于强基线的显着改进,证明了 CoT-MAE 的高效率。我们的代码可在 https://github.com/caskcsg/ir/tree/main/cotmae 获取。
1 引言
段落检索旨在从大型语料库中检索查询的相关段落,这有利于许多下游应用程序,例如网络搜索(Fan et al 2021;Guo et al2022 年; Lin、Nogueira 和 Yates 2021)、问答系统(Karpukhin 等人 2020;Lee 等人 2020;Zhu 等人 2021)和对话系统(Gao 等人 2022a;Yu 等人 2021)。
长期以来,以BM25(Robertson,Zaragoza et al 2009)为代表的稀疏检索是占主导地位的检索方法。最近,随着预训练语言模型(PLM)的发展,密集检索受到越来越多的关注(Devlin et al 2018;Liu et al 2019)。密集检索模型通常基于具有暹罗或双编码器架构的预训练语言模型,将查询和文档编码到低维向量空间中以进行有效搜索(Hofstatter et al 2021; Humeau ¡ et al 2019; Xiong et al 2020詹等人,2021,2020)。查询和文档之间的相关性是通过向量空间中的余弦相似度或点积函数来计算的。因此,基于 PLM 的高质量文本表示对于密集段落检索至关重要。
DPR(Karpukhin et al 2020)成功证明密集检索模型可以优于 BM25 方法。
从那时起,出现了一些工作,通过改进为密集检索量身定制的预训练过程来提高密集检索性能。 (Lu et al 2021;Gao and Callan 2021a;Liu and Shao 2022)鼓励编码器通过辅助自监督重建任务来提高文本表示建模能力。辅助任务通常利用弱解码器在来自编码器的文本向量的帮助下重建屏蔽文本,这迫使编码器提供更好的文本表示。尽管这些工作已被证明非常有效,并在密集检索方面取得了一些改进,但它们主要关注单文本内部建模,而没有考虑上下文信息。 (Chang et al 2020;Gao and Callan 2021b;Ma et al 2022)提出了多源和多粒度对比跨度预测任务,以在预训练期间对相关文本跨度之间的语义相似性进行建模。预训练中引入的这些判别任务改善了密集检索,并且经过训练的检索器实现了最先进的性能。
同时,在多模态表示学习中(Li et al 2021, 2022),生成性预训练任务(例如基于图像的文本解码)已被证明是有效的,这给我们留下了一个问题:基于跨度上下文的生成辅助任务的效果如何?提高密集检索。
为了改进密集段落检索的文本表示建模,本文通过进一步以生成方式引入文本跨度之间的语义相关性,提出了一种新颖的预训练方法。在建模时,我们共同考虑文本范围内标记的语义以及文本范围之间的语义相关性。如图1-(a)所示,我们通过采样策略从文档中选择两个相邻的文本跨度TA和TB,形成跨度对。然后,如图 1-(b) 所示,我们使用屏蔽自动编码对整个过程进行建模。首先,我们考虑自监督屏蔽自动编码,它仅考虑编码器端范围内的未屏蔽标记来重建屏蔽文本范围。如图 1-(b) 中的紫色流程所示,我们分别对 TA 和 TB 应用屏蔽操作,将屏蔽文本馈送到编码器,以使用(自)屏蔽语言建模 (MLM) 目标重建原始文本。
接下来,我们考虑上下文监督自动编码,它在解码器端联合考虑跨度中的未屏蔽标记及其相邻跨度嵌入(即其上下文)来重建屏蔽文本跨度。如图1-(b)绿色流程所示,在解码端,我们以TB为例。我们对 TB 应用掩码操作,并将掩码的 TB 及其上下文(即 TA 的编码嵌入)提供给解码器,与上下文 MLM 目标联合重建 TB。我们将整个过程称为ConTextual Masked AutoEncoding (CoT-MAE),并使用MLM损失进行统一优化。请注意,我们仅在预训练中使用解码器。在密集检索微调期间,不再需要解码器。
我们的设计有几个好处。首先,CoT-MAE 使用自我监督和上下文监督的屏蔽自动编码任务。这两个任务通过上下文表示联系起来,并联合优化以学习更好的文本表示建模能力。其次,非对称编码器-解码器结构非常灵活。我们使用具有足够参数的深度编码器来学习良好的文本表示建模能力。我们使用没有足够参数的浅层解码器来很好地恢复屏蔽标记,这导致对编码器上下文的强烈依赖,并迫使编码器学习提供更好的文本表示。最后,我们可以使用非对称掩码操作,即在编码器和解码器端使用不同的掩码率。受到(He et al 2022;Wettig et al 2022)大掩码率可能有利于预训练的启发,我们在 CoT-MAE 的编码器和解码器中分别采用高达 30% 和 45% 的掩码率。解码器侧较大的掩码率进一步增加了上下文监督掩码自动编码的难度,并迫使编码器侧获得更强大的文本编码能力。
为了验证我们提出的 CoT-MAE 的有效性,我们在大规模网络搜索和开放域 QA 基准上进行了实验:MS-MARCO Passage Ranking (Nguyen et al 2016)、TREC Deep Learning (DL) Track 2020 (Craswell et al) al 2020)和自然问题(NQ)(Kwiatkowski 等人 2019)。
实验结果表明,CoT-MAE 比竞争基线检索器取得了相当大的进步。此外,我们还进行了广泛的消融实验来说明 CoT-MAE 设计的合理性。
我们的贡献可以总结如下:
- 我们提出了一种专为密集检索而定制的新型生成预训练方法 CoTMAE。
- 我们设计了一种数据构造方法和非对称编码器-解码器结构,以实现高效的预训练。
- 实验表明,CoT-MAE 在基准测试中比竞争检索器取得了相当大的进步。
2 相关工作
针对检索的 PLM 的任务:
1)使用 AE 来强迫 encoder 学习更好的表示
2)多种类型的对比任务
微调(传统的DPR方法,直接在IR任务上训练):
1)挖掘硬负例
2)后期交互
3)知识蒸馏
4)查询聚类
5)数据增强
6)联合优化检索器和重新排序器
DPR(Karpukhin et al 2020)在密集检索模型方面优于 BM25 方法。从那时起,出现了许多提高密集检索性能的工作,包括改进预训练和微调的技术。
为密集检索量身定制的预训练任务
一类(Lu et al 2021;Gao and Callan 2021a;Liu and Shao 2022)迫使编码器通过辅助自监督自动编码任务提供更好的文本表示。例如,(Lu et al 2021;Gao and Callan 2021a)建议使用弱解码器执行自动编码,其容量和注意力灵活性有限,以推动编码器提供更好的文本表示。 (Liu and Shao 2022)建议对编码器和弱解码器应用不对称掩蔽比。来自编码器的句子嵌入与其积极屏蔽的版本相结合,以由解码器重建原始句子。与这些工作类似,我们的方法采用非对称编码器和弱解码器架构。不同的是,我们提出了上下文监督自动编码,其中来自编码器的给定文本的屏蔽版本及其相邻文本的嵌入(即其上下文)被联合输入解码器以重建给定文本。
另一类的作品(Chang et al 2020;Gao and Callan 2021b;Ma et al 2022)提出了多源和多粒度对比跨度预测任务,以类似于预训练中的段落检索。 (Chang et al 2020)提出了三个任务:逆完型填空任务(ICT)、主体优先选择(BFS)和维基链接预测(WLP)。这三个任务利用维基百科页面的文档结构自动生成对比对并拉近相关对,同时排除不相关的对。类似地,(Gao and Callan 2021b)在预训练过程中引入了语料库级别的对比跨度预测损失,假设来自同一文档的跨度比来自不同文档的跨度更接近。 (Ma et al 2022) 将对比跨度预测任务概括为多个粒度级别,即单词级、短语级、句子级和段落级。不同的是,我们通过上下文嵌入辅助的解码器端 MLM 重建引入了一种生成式非对比上下文屏蔽自动编码任务,该任务更具挑战性,但被证明更有效。
微调
许多尝试都在探索提高微调性能,例如挖掘硬负例(Xiong et al 2020; Zhan et al 2021)、后期交互(Khattab and Zaharia 2020)、从强大的老师那里提取知识(Lin, Yang) 、Lin 2021;Santhanam 等人 2021)、查询聚类(Hofstatter 等人 2021)、数据增强 ¡(Qu 等人 2020)以及联合优化检索器和重新排序器(Ren 等人 2021b;Zhang 等人 2022、2021) 。
例如,(Xiong et al 2020)提出通过使用定期更新的近似最近邻(ANN)索引搜索语料库来构造硬负例,该方法已被证明非常有效并被以下方法采用。 (Zhan et al 2021) 进一步利用微调的密集检索器来提高挖掘的硬底片的质量。
(Khattab 和 Zaharia 2020)提出了一种后期交互,对编码器的最后隐藏状态应用 MaxSim 操作,以对查询和文档之间的细粒度相似性进行建模。 (Lin、Yang 和 Lin 2021)从 ColBERT 的 MaxSim 算子中提取到检索器中,同时(Santhanam 等人 2021)建议从更强的重新排序器中提取到 ColBERT。 (Hofstatter et al 2021) 引入了 ¡ 一种高效的主题感知查询和平衡边缘采样技术来提高微调效率。 (Qu et al 2020)结合了三种有效策略来实现良好的性能,即跨批次负例、去噪硬负例和数据增强。 (Ren et al 2021b) 通过设计统一的列表训练方法来引入动态列表蒸馏,以自适应地改进检索器和重新排序器。 (Zhang et al 2022) 设计了混合列表感知变压器重排序 (HLATR) 作为后续重排序模块,以合并检索和重排序阶段功能。 (Zhang et al 2021)提出了对抗性检索器排序器,它由双编码器检索器和交叉编码器排序器组成,根据极小极大对抗目标进行联合优化。由于我们专注于预训练带来的改进,因此(Gao and Callan 2021a,b; Ma et al 2022),我们重用了开源微调管道 Tevatron(Gao et al 2022b)来评估我们预训练的有效性。 - 训练方法。
3 方法
在本节中,我们首先介绍屏蔽自动编码器结构作为预备知识。然后介绍了CoT-MAE的数据构建和模型结构。
3.1 初步:屏蔽自动编码
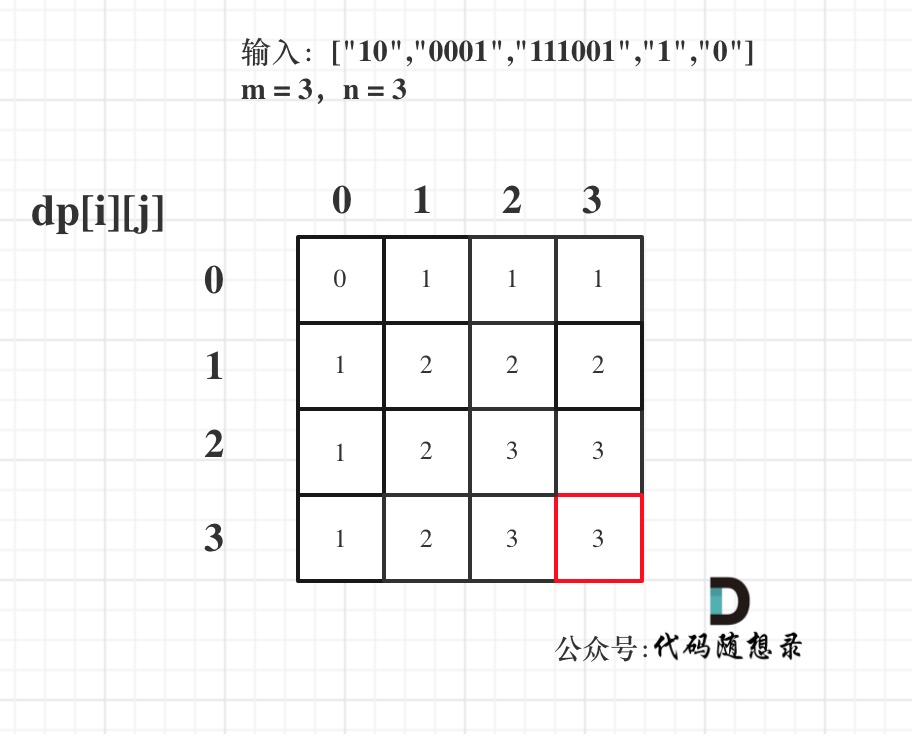
文本屏蔽自动编码,即 BERT 的 MLM 任务,在未标记的数据上进行训练,无需额外的手动标记。形式上,给定一个带有 n 个后续标记的文本 T,我们在文本的开头添加一个特殊标记 [CLS],如下所示
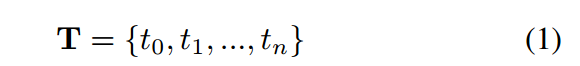
,其中 t0 表示 [CLS] 标记。我们随机选择一定比例的代币,即掩码率,并将其替换为特殊代币[MASK]。受(He et al 2022;Wettig et al 2022)大掩码率可能有利于预训练的启发,我们采用大于 BERT 15% 设置的掩码率。我们将被 [MASK] 替换的标记表示为 m(T),其余标记表示为 T\m(T)。
然后 T\m(T) 通过编码器以恢复带有掩码语言模型 (MLM) 损失的 m(T)。我们将此过程表述为:

对于编码器或解码器中的第 l 个 Transformer 层,其输出是该层的隐藏状态
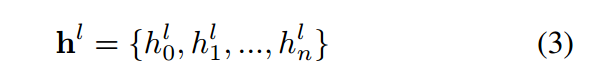
通常,编码器最后一层的 [CLS] 位置的隐藏状态,即 h last 0 ,将被用作 T 的嵌入表示。
3.2 CoT-MAE:上下文屏蔽自动编码器
CoT-MAE 共同学习对文本范围内标记的语义以及文本范围之间的语义相关性进行建模。
我们首先描述如何从未标记的文档构建训练数据,如图 1-(a) 所示。给定一个文档,我们使用 NLTK 等工具将其拆分为不超过最大长度的文本范围。然后,我们使用采样策略从文档中选择两个相邻的文本跨度 TA 和 TB 来形成跨度对。一对中的两个跨度是彼此的邻居或上下文。
采样策略
我们使用三种采样策略,称为“Near”、“Olap”和“Rand”。近邻策略对两个相邻的跨度进行采样,但不重叠以形成一对。 Olap 策略对具有部分重叠段的两个相邻跨度进行采样以形成一对。 Rand 策略随机采样两个不重叠的跨度以形成一对
然后,我们介绍了CoT-MAE的模型设计,如图1-(b)所示。我们使用非对称编码器解码器结构,具有强的深层编码器和弱的浅层解码器。深层编码器有足够的参数来学习良好的文本表示建模能力,而浅层解码器则被设置为辅助编码器实现这一目标。由于CoT-MAE对跨度对采用对偶建模过程,因此我们仅详细介绍图1-(b)的左半部分。即TA在编码器侧,TB在解码器侧。我们采用非对称掩码操作,在编码器和解码器端使用不同的掩码率。
我们对编码器端的TA应用随机掩码操作。
我们将被 [MASK] 替换的标记表示为 menc(TA),其余标记表示为 TA\menc(TA)。类似地,我们在解码器端对 TB 应用另一个随机掩码操作。
我们将被 [MASK] 替换的标记表示为 mdec(TB),其余标记表示为 TB\mdec(TB)。
自监督预训练
在编码器方面,我们仅考虑跨度中未屏蔽的标记来重建文本跨度。未屏蔽的标记 TA\menc(TA) 通过编码器传递,以使用自监督屏蔽语言模型(self-MLM)损失来恢复 menc(TA):
下标“smlm”表示该过程是自监督的,上标A表示对TA应用自监督预训练
上下文监督预训练
在解码器方面,我们考虑到其未屏蔽的标记及其相邻的跨度嵌入(即其上下文嵌入)来重建该对中的另一个文本跨度。具体来说,对于 TB,其上下文嵌入是来自编码器最后一层的 TA 的 [CLS] 隐藏状态,也表示为 h last 0 。我们将 TB\mdec(TB) 和 h last 0 联合输入解码器,以使用上下文监督的掩码语言模型损失来恢复 m(TB):
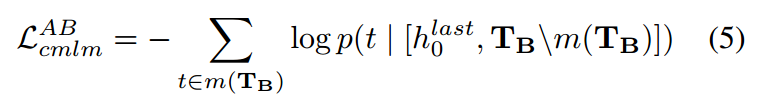
下标“cmlm”表示该过程是上下文监督的,上标“AB”表示TB使用TA作为上下文,“[]”表示串联操作。然后,我们将编码器和解码器的损失相加,得到损失总和:
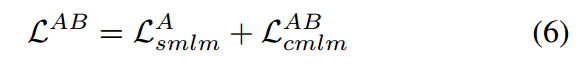
同时,还有一种双重情况,TB在编码器侧,TA在编码器侧。总损失为:
最后,我们提出的 CoT-MAE 的总损失为:

3.3 密集通道检索的微调
在 CoT-MAE 预训练结束时,我们只保留编码器并丢弃解码器。编码器权重用于初始化查询编码器 fq 和通道编码器 fp 以进行密集检索。查询(或段落)编码器使用最后一层的 [CLS] 嵌入作为查询(或段落)表示,表示为 fq(q)(或 fp§)。查询-段落对 < q, p > 的相似度定义为内积:

查询和段落编码器在检索任务的训练语料库上进行微调,并具有对比损失:
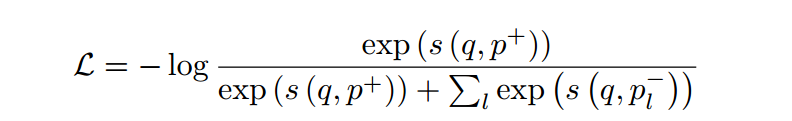
其中 p + 表示正向段落,{p − l } 表示一组负向段落。在实践中,我们重用了广泛采用的评估管道,即 Tevatron (Gao et al 2022b)。该管道使用 BM25 负片训练第一阶段检索器,然后使用 BM25 负片和第一阶段检索器挖掘的硬负片训练第二阶段检索器。第二阶段检索器用作最终检索器进行评估
4 实验
在本节中,我们首先介绍预训练和微调的细节。然后我们介绍实验结果。
4.1 预训练
我们从预训练的 12 层 BERT 库初始化 CoT-MAE 的编码器,并从头开始初始化解码器。接下来(Gao 和 Callan 2021b),预训练数据集是根据包含 320 万个文档的 MS-MARCO 段落语料库 1 构建的。我们使用NLTK将每个文档分割成句子,并将连续的句子分组为跨度,但不超过最大跨度长度等于128。我们使用引入的三种采样策略的均匀混合,并在不同时期动态选择两个跨度形成跨度对。预训练过程。我们使用 AdamW 优化器预训练多达 1200k 步,学习率为 1e-4,线性调度的预热比率为 0.1。我们在 8 个 Tesla A100 GPU 上训练了 4 天,全局批量大小为 1024。由于预训练中的计算预算很高,我们不会调整这些超参数,而是将其留给未来的工作。预训练后,我们丢弃解码器,只留下编码器进行微调。
4.2 微调
我们对 MS-MARCO 通道排名(Nguyen et al 2016)、Natural Question(Kwiatkowski et al 2019)和 TREC Deep Learning (DL) Track 2020(Craswell et al 2020)任务上预训练的 CoT-MAE 进行微调以进行评估。继coCondenser(Gao and Callan 2021b)之后,我们使用(Qu et al 2020)中发布的MS-MARCO语料库,继RocketQA(Qu et al 2020)之后,我们使用DPR创建的NQ版本(Karpukhin et al 2020)。我们重复使用了广泛采用的评估管道,即 Tevatron(Gao 等人 2022b),并使用公共固定种子(42)来支持再现性。
请注意,当我们专注于改进预训练技术时,我们不使用任何增强的方法,例如从强大的重新排序器或多向量表示中蒸馏,尽管它们可以带来进一步的改进。接下来(Gao and Callan 2021b;Hofstatter et al 2021),对于评估指标,我们对 MS-MARCO 使用 MRR@10、Recall@50 和 Recall@1000,对 MS-MARCO 使用 Recall@5、Recall@20、Recall@100 TREC DL 的 NQ 和 nDCG@10。
基线
我们的基线方法包括稀疏检索方法和密集检索方法,如表1所示。稀疏检索基线的结果主要来自(Qu et al 2020),包括BM25、docT5query(Nogueira and Lin 2019)、DeepCT(Dai和 Callan 2019)和 GAR(Mao 等人 2020)。密集检索基线的结果主要来自(Gao and Callan 2021b; Liu and Shao 2022; Ren et al 2021b; Ma et al 2022),包括ANCE (Xiong et al 2020)、SEED (Lu et al 2021)、TAS-B (Hofstatter 等人 2021)、RetroMAE(Liu 和 Shao 2022)等等。
4.3 主要结果
我们在表 1 中列出了主要结果,其中表明与三个数据集上的竞争基线相比,CoT-MAE 取得了相当大的进步。在 MS-MARCO 通道排名数据集上,CoT-MAE 在 MRR@10 上超过了之前最先进的预训练方法 coCondenser 1.2%,这是明显的领先。这表明生成预训练方法在利用上下文增强语义表示建模能力方面比对比学习方法更有效。与RocketQA等改进微调阶段的方法或ColBERT等采用多向量的方法相比,CoT-MAE也表现得更好。在 NQ 数据集上,CoT-MAE 也实现了与 coCondenser 相当的性能,优于其余方法。虽然 coCondenser 在 R@5 上的表现稍好一些,但 CoT-MAE 在 R@100 上的表现优于它。在 TREC DL 数据集上,CoT-MAE 明显优于评估的基线,在 nDCG@10 上达到 70。总的来说,在最常用的基准数据集上将 CoT-MAE 与之前的有效方法进行比较表明,CoT-MAE 预训练过程可以有效提高密集检索。改进来自两个方面。一方面,预训练方法既考虑文本范围内标记的语义,又考虑相邻文本范围之间的语义相关性。另一方面,混合数据构建策略和具有非对称掩蔽策略的非对称编码器解码器结构共同有助于高效的预训练。
5 分析
我们首先将 CoT-MAE 与最先进的蒸馏猎犬进行比较。然后我们试图了解不同设置对 CoT-MAE 性能的影响。除非另有说明,我们的分析基于 MS-MARCO 通道排序任务,并且由于计算预算较高而预先训练了 800k(不是主实验中的 1200k)步骤。
5.1 与蒸馏检索器的比较
由于 CoT-MAE 专注于改进预训练以提高检索中的文本表示,因此与从重新排序器中提取的检索器进行比较是可选的,并保留在此处。典型的段落排名过程涉及检索然后重新排名管道。 Re-ranker 是一种交叉编码器,可以对查询和段落之间的完整交互进行建模,其功能强大,但计算量太大,无法应用于检索。 (Ren et al 2021b;Santhanam et al 2021;Zhang et al 2021)采用重排序器作为老师来提炼检索器,试图将重排序器的能力转移到检索器上。
为了进一步验证 CoT-MAE 预训练的有效性,我们首先将微调的 CoT-MAE 检索器(无蒸馏)与最先进的蒸馏检索器进行比较。然后我们训练一个在 MRR@10 上达到 43.3 的 CoT-MAE 重排序器,并使用该重排序器来提取 CoTMAE 检索器。
如表 2 所示,令人印象深刻的是,经过微调的 CoT-MAE 检索器(无蒸馏)实现了接近蒸馏检索器的性能,证明了 CoT-MAE 预训练的有效性。经过微调的 CoTMAE 检索器在 R@1k 上略优于所有蒸馏检索器,在 R@50 上仅次于 AR2,并在 MRR@10 上超过 RocketQAv2。应用蒸馏后,CoT-MAE 检索器在 MRR@10、R@50 和 R@1k 上明显超过了所有先前最先进的蒸馏检索器,这表明 CoT-MAE 重新排序器可以进一步改进 CoT-MAE 检索器
5.2 掩模率的影响
(Wettig et al 2022) 发现,更大的掩码比可以优于 BERT 的 15% 基线 (Devlin et al 2018)。因此,我们探讨了不同掩码率对编码器和解码器的影响。如表3所示,在我们的实验中,当编码器掩码率为30%,解码器掩码率为45%时,CoT-MAE实现了最佳性能。当编码器掩码率不超过30%时,CoT-MAE的性能随着解码器掩码率的增加而提高。当编码器掩码率高达45%时,CoT-MAE的性能略有下降。我们认为这是由于当掩码率太大时编码器的上下文不足造成的。总的来说,CoT-MAE 对大范围的 mask rates 相当鲁棒,适当的大 mask rates 可以获得相对更好的性能,这与(Wettig et al 2022)在 BERT 预训练中的发现类似。
5.3 抽样策略的影响
在CoT-MAE的数据构建过程中,我们使用了Near、Olap和Rand三种跨度采样策略。我们进一步探讨不同采样策略的影响。我们尝试不同策略的组合,包括仅使用单一策略、混合两种策略以及混合三种策略。如表4所示,混合三种策略时获得最佳性能,混合两种策略时性能略有下降,仅使用单一策略时下降较大。趋势表明,数据组成的多样性有利于预训练。然而,即使只有单一策略,CoT-MAE也能取得不错的结果,进一步说明了CoT-MAE模型设计的有效性。
5.4 解码器层数的影响
我们进一步探讨了不同解码器层数对 CoT-MAE 性能的影响。我们对一些最常见的层设置进行实验,如表 5 所示。使用两层解码器,CoT-MAE 在我们的实验中取得了最佳结果。较弱或较强的解码器都会降低性能。当解码器中只有一层 Transformer 层时,解码器的建模能力太弱,无法充分融合上下文嵌入和未屏蔽的令牌嵌入,导致信息利用效率低下。当层数较多时,由于解码器的能力较强,屏蔽自动编码任务对上下文嵌入的依赖减少,导致对编码器训练的约束不足。总的来说,CoT-MAE对于不同层的解码器的性能是相当稳健的,适当更深的解码器可以获得相对较好的性能。
5.5 解码器权重初始化的影响
CoT-MAE的编码器结构与BERT相同,因此编码器直接用预训练的BERT进行初始化。相比之下,解码器只有两层,因此存在不同的初始化选项。我们探索了四种不同的初始化方法:从预训练 BERT 的前两层 (0,1) 初始化、均匀选择层 (5,11) 初始化、最后两层 (10,11) 初始化以及随机初始化。我们对每个步骤训练 800k 个步骤,并绘制它们的性能曲线,如图 2 所示。一般来说,长时间的预训练足以让参数有限的解码器收敛,因此解码器的最终结果相当不错。
经过超过 600k 的预训练后,随机初始化持续改进,而其他初始化方法往往会出现波动。值得注意的是,在仅训练 200k 时,具有不同初始化的 CoT-MAE 显着优于 coCondeser(38.2),这进一步证明了 CoT-MAE 预训练的效率。
5.6 定性分析
为了定性地理解我们提出的预训练方法的收益,我们在表 6 中展示了 CoT-MAE 可以准确回忆相关排名第一段落的示例。
在示例中,尽管 BERT 或 coCondenser 召回的排名第一的段落与查询具有标记级重叠,但它们在语义上并不高度相关。相比之下,由于在预训练阶段通过屏蔽自动编码对 token 和 span 上下文进行联合建模,CoT-MAE 在语义理解方面表现更好。这进一步证明CoT-MAE预训练方法比之前的预训练方法更有效。
6 结论和未来工作
本文提出了一种专为密集检索而定制的新的生成预训练方法,考虑了文本范围内标记的语义以及相邻文本范围之间的语义相关性。实验结果表明,CoT-MAE 在基准测试中比竞争基线检索器取得了相当大的进步。未来,我们将进一步探索在多语言和多模态领域应用上下文屏蔽自动编码器的可能性。
这篇关于信息检索(36):ConTextual Masked Auto-Encoder for Dense Passage Retrieval的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)