dense专题
![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)
[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval
引言 今天带来北京智源研究院(BAAI)团队带来的一篇关于如何微调LLM变成密集检索器的论文笔记——Making Large Language Models A Better Foundation For Dense Retrieval。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 密集检索需要学习具有区分性的文本嵌入,以表示查询和文档之间的语义关系。考虑到大语言模

SQLSERVER排名函数RANK,DENSE_RANK,NTILE,ROW_NUMBER
SQL SERVER排名函数RANK,DENSE_RANK,NTILE,ROW_NUMBER 前言 本文意于用实例数据帮助理解SQL SERVER排名函数RANK,DENSE_RANK,NTILE,ROW_NUMBER。 准备工作 创建测试表: ? 1 2 3 4 5 create table test( id int identity(1,1)

keras 实现dense prediction 逐像素标注 语义分割 像素级语义标注 pixelwise segmention labeling classification 3D数据
主要是keras的示例都是图片分类。而真正的论文代码,又太大了,不适合初学者(比如我)来学习。 所以我查找了一些资料。我在google 上捞的。 其中有个教程让人感觉很好.更完整的教程。另一个教程。 大概就是说,你的输入ground truth label需要是(width*height,class number),然后网络最后需要加个sigmoid,后面用binary_crossentro

ROW_NUMBER() OVER()、RANK() OVER()、DENSE_RANK() OVER()的使用
工作中需要用到对多列分组并排序后的组内数据。这时候就需要用ROW_NUMBER() OVER()啦。 语法格式:row_number() over(partition by 分组列 order by 排序列 desc) 注意:over()里头的分组以及排序的执行晚于sql中 where 、group by、 order by 的执行。 SELECT l.purchase_order,l

Convolutional layers/Pooling layers/Dense Layer 卷积层/池化层/稠密层
Convolutional layers/Pooling layers/Dense Layer 卷积层/池化层/稠密层 Convolutional layers 卷积层 Convolutional layers, which apply a specified number of convolution filters to the image. For each subregion, the

论文笔记 DenseCap: Fully Convolutional Localization Networks for Dense Captioning
李飞飞组的文章,是一篇很有意思的文章,主要介绍了一种CNN解决密集字幕任务的方法。密集字幕任务主要含两个方面: (1)单个单词描述的目标检测任务;(2)对整个图像的一个预测区域的字幕标注任务。具体任务需求如下: 文章主要提出了全卷积定位网络(FCLN)架构,无需外部区域的建议,并可以用单轮优化进行端对端的训练。该架构包含一个卷积网络,一个新的密集定位层,一个生成标签序列的递归神经网络的语言

SQL窗口函数:RANK()与DENSE_RANK()的区别
在SQL中,窗口函数允许我们对查询结果集中的行进行排序和排名,而RANK()和DENSE_RANK()是用来进行排名的常见选择。它们的主要区别在于如何处理排名相同的情况,也就是出现了排名并列的情况。 1. RANK() RANK()函数根据指定的ORDER BY子句对行进行排序,并为每一行分配一个排名: 排名分配: 对每个唯一的行根据指定的排序顺序分配唯一的排名。处理并列: 如果有多行

计算机视觉与深度学习 | TensorMask: A Foundation for Dense Object Segmentation(何凯明团队新作)近5年目标检测综述
博主github:https://github.com/MichaelBeechan 博主CSDN:https://blog.csdn.net/u011344545 =================================================== https://github.com/MichaelBeechan/tf-faster-rcnn TensorMask:
关于函数row_number,rank,dense_rank排序
eg:返回排名前三的用户 select no, sal, row_number() over(partition by mo order by sal desc) as row_number, rank() over(partition by mo order by sal desc) as rank, de

rank(),dense_rank(),row_number()函数区别
rank,dense_rank,row_number区别 一:语法(用法): rank() over([partition by col1] order by col2) dense_rank() over([partition by col1] order by col2) row_number() over([partition by col1] order
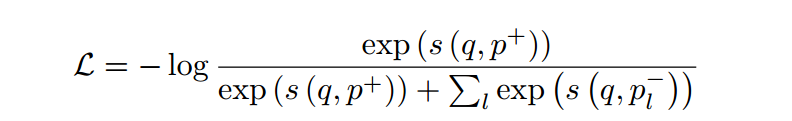
信息检索(36):ConTextual Masked Auto-Encoder for Dense Passage Retrieval
ConTextual Masked Auto-Encoder for Dense Passage Retrieval 标题摘要1 引言2 相关工作3 方法3.1 初步:屏蔽自动编码3.2 CoT-MAE:上下文屏蔽自动编码器3.3 密集通道检索的微调 4 实验4.1 预训练4.2 微调4.3 主要结果 5 分析5.1 与蒸馏检索器的比较5.2 掩模率的影响5.3 抽样策略的影响5.4 解码器
Tensorflow常用函数-keras.layers.Dense
keras.layers.Dense(units, activation=None, use_bias=None, kernel_initializer=None,bias_initializer=None,kernel_regularizer=None,bias_regularizer=None,activity_regularizer=None,kernel_constraint=None,b
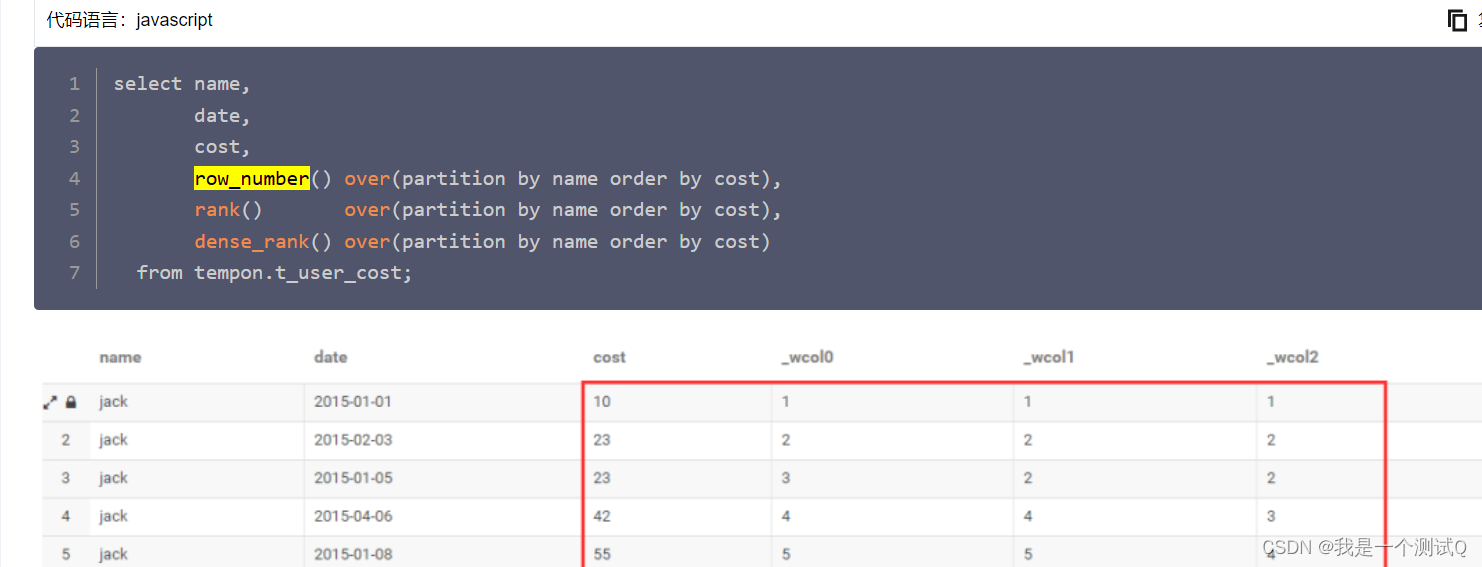
hive-row_number() 和 rank() 和 dense_rank()
row_number() 是无脑排序 rank() 是相同的值排名相同,相同值之后的排名会继续加,是我们正常认知的排名,比如学生成绩。 dense_rank()也是相同的值排名相同,接下来的排名不会加。不会占据排名的坑位。
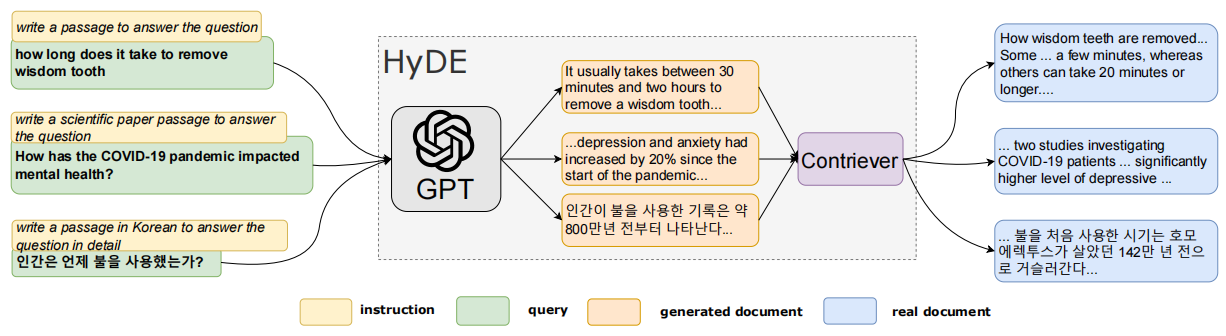
【IR 论文】HyDE:让 LLM 对 query 做查询改写来改进 Dense Retrieval
论文:Precise Zero-Shot Dense Retrieval without Relevance Labels ⭐⭐⭐⭐ CMU, ACL 2023, arXiv:2212.10496 Code: github.com/texttron/hyde 文章目录 论文速读总结 论文速读 在以往的 dense retrieval 思路中,需要对 input quer
Dense embedding model 和 sparse embedding model 对比
Dense embedding model 和 sparse embedding model 都是将高维稀疏向量嵌入到低维稠密向量的技术,常用于自然语言处理 (NLP) 任务中。两种模型的主要区别在于它们如何表示嵌入向量: Dense embedding model 使用稠密向量来表示每个单词或短语。每个维度的值代表该单词或短语在语义空间中对应方面的重要性。例如,一个维度的值可能表示该单词的积极

DenseDiffusion:Dense Text-to-Image Generation with Attention Modulation
1 研究目的 该文献的研究目的主要是: 探讨一种更为广泛的调制方法,通过设计多个正则化项来优化图像合成过程中的空间控制。论文的大致思想是,在现有的基于数据驱动的图像合成系统基础上,通过引入更复杂的调制策略,实现对文本描述和空间控制更为精确的图像合成。 在研究中,作者发现了以下问题: 现有的文本到图像扩散模型很难在给定密集字幕的情况下合成逼真的图像,并且倾向于省略或混合不同对象的视觉
论文复现《SplaTAM: Splat, Track Map 3D Gaussians for Dense RGB-D SLAM》
前言 SplaTAM算法是首个开源的基于RGB-D数据,生成高质量密集3D重建的SLAM技术。 通过结合3DGS技术和SLAM框架,在保持高效性的同时,提供精确的相机定位和场景重建。 代码仓库:spla-tam/SplaTAM: SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM (CVPR 2024) (githu

【论文阅读】RS-Mamba for Large Remote Sensing Image Dense Prediction(附Code)
论文作者提出了RS-Mamba(RSM)用于高分辨率遥感图像遥感的密集预测任务。RSM设计用于模拟具有线性复杂性的遥感图像的全局特征,使其能够有效地处理大型VHR图像。它采用全向选择性扫描模块,从多个方向对图像进行全局建模,从多个方向捕捉大的空间特征。 论文链接:https://arxiv.org/abs/2404.02668 code链接:https://github.com/walking

用于密集视觉冲击的紧凑三维高斯散射Compact 3D Gaussian Splatting For Dense Visual SLAM
Compact 3D Gaussian Splatting For Dense Visual SLAM 用于密集视觉冲击的紧凑三维高斯散射 Tianchen Deng 邓天辰11Yaohui Chen 陈耀辉11Leyan Zhang 张乐妍11Jianfei Yang 杨健飞22Shenghai Yuan 圣海元22Danwei Wang 王丹伟22Weidong Chen 陈
ValueError:Tensor(“dense_1/Softmax:0“, shape=(?, 3), dtype=float32) is not an element of this graph
今天在写接口的时候再次出现了一个经典的老问题,如下所示: ValueError: Tensor Tensor("dense_1/Softmax:0", shape=(?, 3), dtype=float32) is not an element of this graph. 这里主要是想记录一下具体的解决方案,防止之后再次遇到的时候还需要去查资料,这里提供两种措施,如下: 1、每次预测完成之
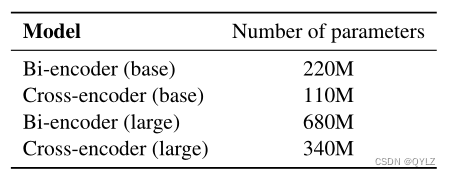
论文:Scalable Zero-shot Entity Linking with Dense Entity Retrieval翻译笔记(实体链接)
文章目录 论文标题:通过密集实体检索实现可扩展的零镜头实体链接摘要1 引言2 相关工作3 定义和任务制定4 方法4.1 双编码器4.2 交叉编码器4.3 知识蒸馏 5 实验5.1 数据集5.2 评估设置和结果5.2.1 零点实体链接5.2.2 tackbp-20105.2.3 WikilinksNED Unseen-Mentions 5.3 知识蒸馏 6 定性分析7 结论A 训练细节和超参数
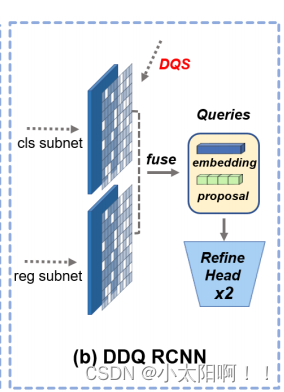
Dense Distinct Query for End-to-End Object Detection
摘要 对象检测中的一对一标签分配成功地消除了作为后处理的非极大值抑制( NMS )的需要,并使流水线端到端。然而,这引发了一个新的困境,因为广泛使用的稀疏查询无法保证高召回率,而密集查询不可避免地带来更多类似的查询并遇到优化困难。由于稀疏查询和密集查询都有问题,那么端到端对象检测中预期的查询是什么?本文证明了该解决方案应该是密集的区别查询( DDQ ) 。具体来说,我们首先像传统的检测器一样设

rank() over, dense_rank() over, row_number() over的区别
rank() over, dense_rank() over, row_number() over的区别 --ROW_NUMBER() OVER 不需要考虑并列,即使查询出来的数值相同也会进行连续排名SELECT NAME, STUNO, SUBJECT, SCORE, ROW_NUMBER() OVER(PARTITION BY SUBJECT ORDER BY SCORE DESC) TO
MySQL row_number()函数,rank()函数和dense_rank()函数
从MySQL8.0开始引用row_number(), rank()函数和dense_rank()函数,也就是常见的窗口函数,三个函数都是一种用于计算排名的工具,它们根据指定的列对结果集进行排序,并为每一行分配一个排名值(1,2,3,...)。 函数区别点 1、row_number()函数不会跳过相同值排名,即常见顺序(1,2,3) 适用场景: 需要为每一行分配唯一的数字。不关心相同值的排
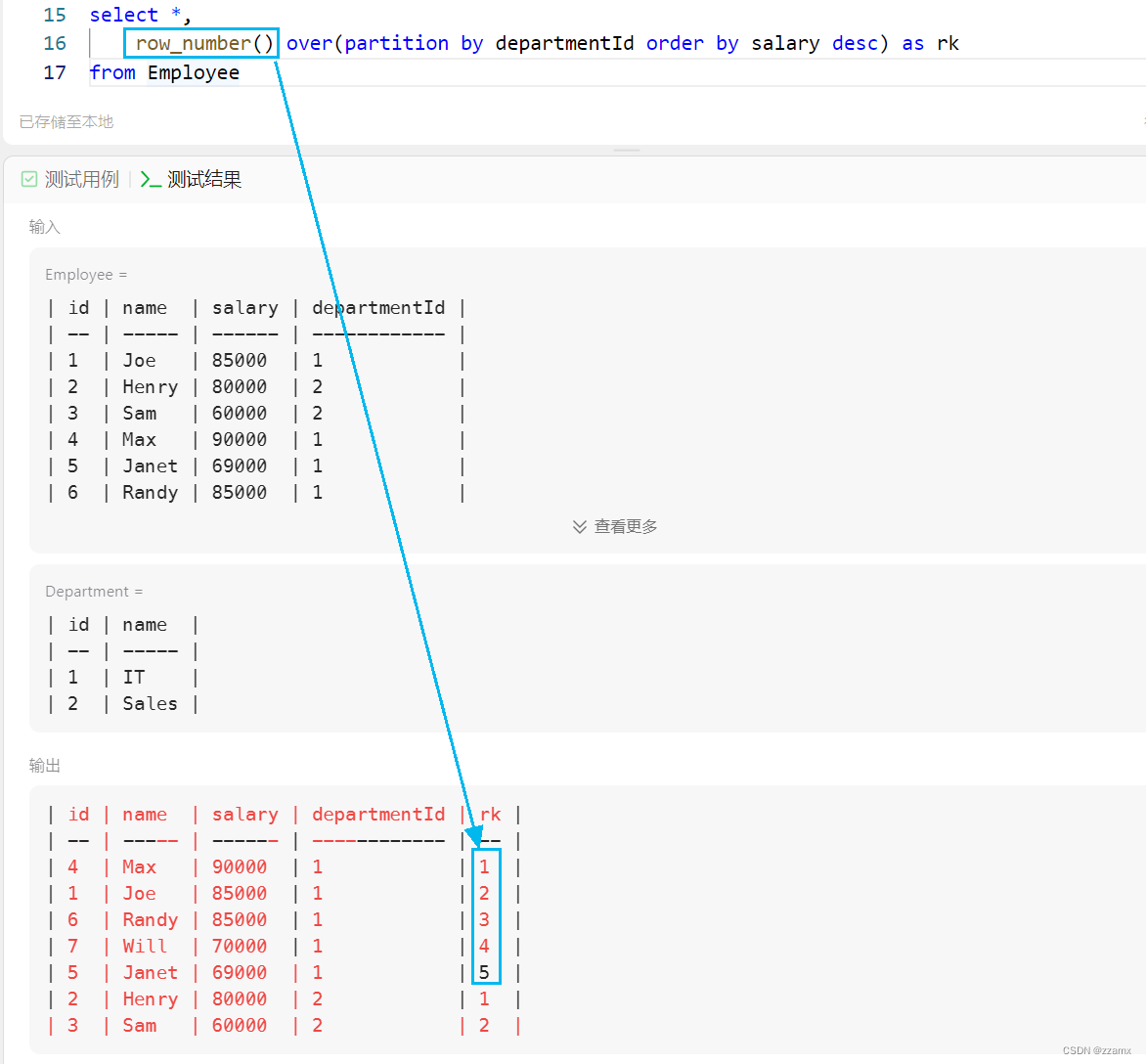
【SQL】185. 部门工资前三高的所有员工(窗口函数dense_rank();区分rank()、row_number())
前述 推荐阅读:通俗易懂的学会:SQL窗口函数 题目描述 leetcode题目 185. 部门工资前三高的所有员工 思路 先按照departmentId分组,再按照salary排序 ==>窗口函数dense_rank() over() select B.name as Department,A.name as Employee,A.salary as Salaryfrom (s

计算机视觉与深度学习 | TANDEM:Tracking and Dense Mapping in Real-time using Deep Multi-view Stereo
================================================ 博主github:https://github.com/MichaelBeechan 博主CSDN:https://blog.csdn.net/u011344545 ================================================ 计算机视觉与深度学习 | SLA