本文主要是介绍论文复现《SplaTAM: Splat, Track Map 3D Gaussians for Dense RGB-D SLAM》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
SplaTAM算法是首个开源的基于RGB-D数据,生成高质量密集3D重建的SLAM技术。
通过结合3DGS技术和SLAM框架,在保持高效性的同时,提供精确的相机定位和场景重建。
代码仓库:spla-tam/SplaTAM: SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM (CVPR 2024) (github.com)![]() https://github.com/spla-tam/SplaTAM
https://github.com/spla-tam/SplaTAM
论文地址:2312.02126.pdf (arxiv.org)
一、实验环境
1.1 电脑环境
Ubuntu18.04,python3.10,cuda11.6,pytorch1.12.1
1.2 配置须知
根据作者给的代码仓库,本人按照README文件进行配置,需要注意如下几点:
1、pip install -r requirements.txt这块git的下载可能会很慢,可以注释掉然后再重新下载
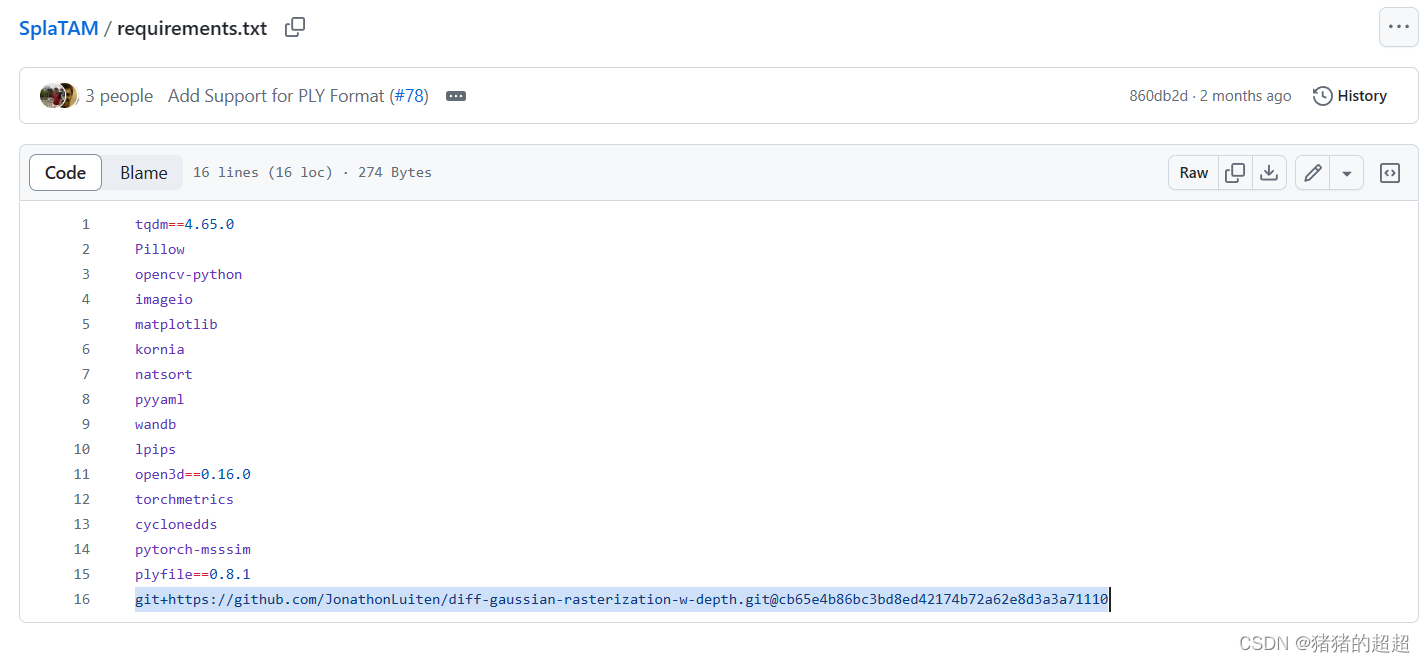
在项目目录下运行下面指令即可:
git clone https://github.com/JonathonLuiten/diff-gaussian-rasterization-w-depth2、然后配置的时候,需要在终端bash的环境变量里面加入cuda的位置,修改.bashrc
3、编译器gcc版本需要降低到10,运行指令:
conda install gxx_linux-64=104、然后在下载的这个目录运行pip install .(注意有一个点 . )即可安装好diff-gaussian-rasterization-w-depth这个库(可微高斯光栅化的库)。
1.3 下载数据集(运行下载脚本即可)
代码提供给了几种数据集,有IPhone设备收集(可以在线和捕获照片后离线), 也有经典的数据集Replica、TUM-RGBD、ScanNet、ScanNet++、ReplicaV2 随后作者给出了上述数据集的基准测试的运行指令。
二、配置过程
由于本人在Ubuntu系统下运行,因此配置的过程也是使用的基于Linux的:
2.1 环境搭建
(conda安装+Python3.10的虚拟环境+cuda+pytorch+requirements.txt对应功能包)
conda create -n splatam python=3.10
conda activate splatam
conda install -c "nvidia/label/cuda-11.6.0" cuda-toolkit
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge
pip install -r requirements.txt2.2 下载数据集
由于没有IPhone手机和相关设备,因此只能离线下载数据集进行渲染,本人选择的是TUM-RGBD数据集,因为Replica数据集太大了,下载时间太长。
bash bash_scripts/download_tum.sh2.3 训练SplaTAM(渲染过程)
首先先把 configs/tum/splatam.py 文件里的 use_wandb = True 改成了 False 。
然后在终端运行即可开始训练:
python scripts/splatam.py configs/tum/splatam.py训练过程如图所示:

使用的GTX4070显卡,训练了大概四五十分钟。
三、复现结果
训练完成之后,我们运行下面的指令即可得到渲染的最终结果和渲染过程视频。
3.1 最终结果展示
在终端输入指令
python viz_scripts/final_recon.py configs/tum/splatam.py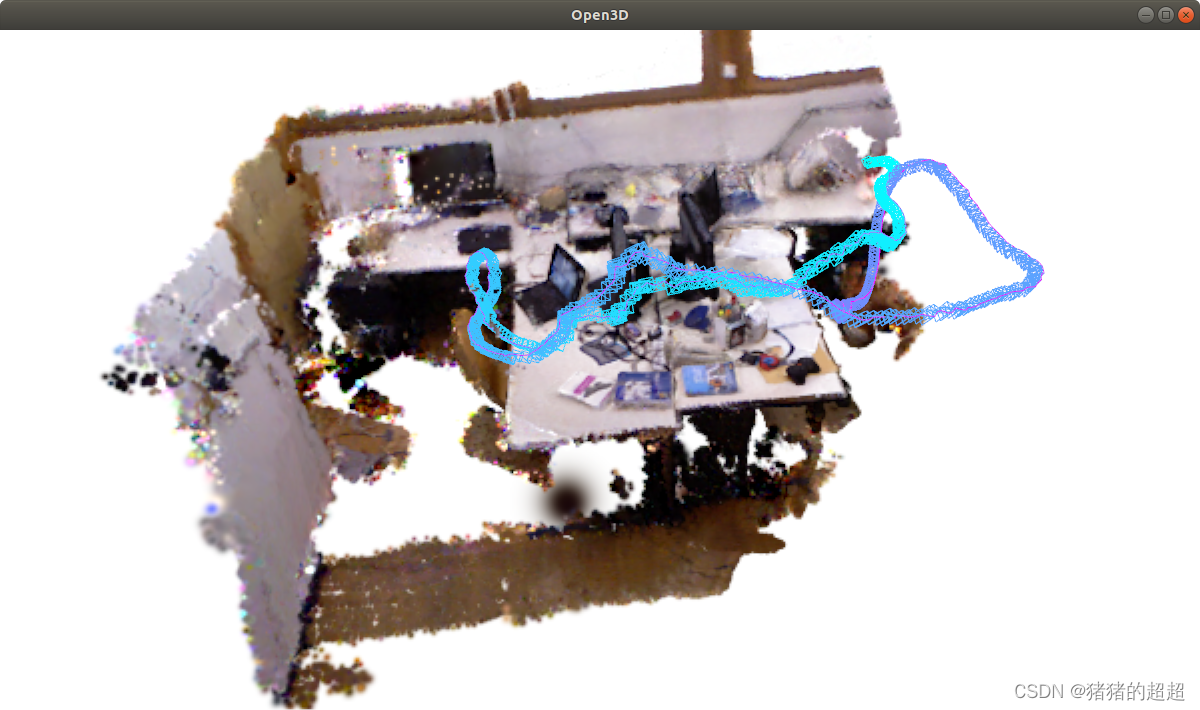
在config/tum/splatam.py中修改参数,重新再训练得到对比如下:

3.2 渲染过程视频
在终端输入指令
python viz_scripts/online_recon.py configs/tum/splatam.py视频放不上去,大家可以运行这个指令自我尝试一下。
四、算法解读
4.1 算法对比
【数据集】
在四个数据集ScanNet++ 、Replica、TUM-RGBD、ScanNet进行评估
【评价指标】
为了测量RGB渲染性能使用了PSNR、SSIM和LPIPS
【损失函数】
对于深度渲染性能使用深度L1损失
对于摄像机姿态估计跟踪使用平均绝对轨迹误差(ATE RMSE)
【Baselines】
比较的主要基线方法是Point-SLAM。
- 完成了四个数据集上在线相机位姿实验;
- 高斯图重建与摄像机pose的可视化;
- 渲染质量比较评估;
- 颜色和深度损失消融。
4.1 各向同性的3DGS
SplaTAM公式:
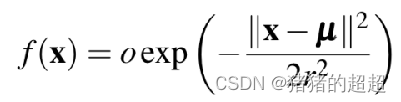
3DGS公式:
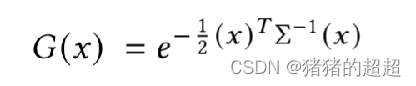
4.2 基于Splatting的可微分渲染

4.3 SplaTAM的缺点
尽管 SplaTAM 实现了最先进的性能,但该方法对运动模糊、大深度噪声和激进旋转表现出一定的敏感性。
五、代码解读
5.1 代码整体框架
对于项目代码的分析框架如下所示:
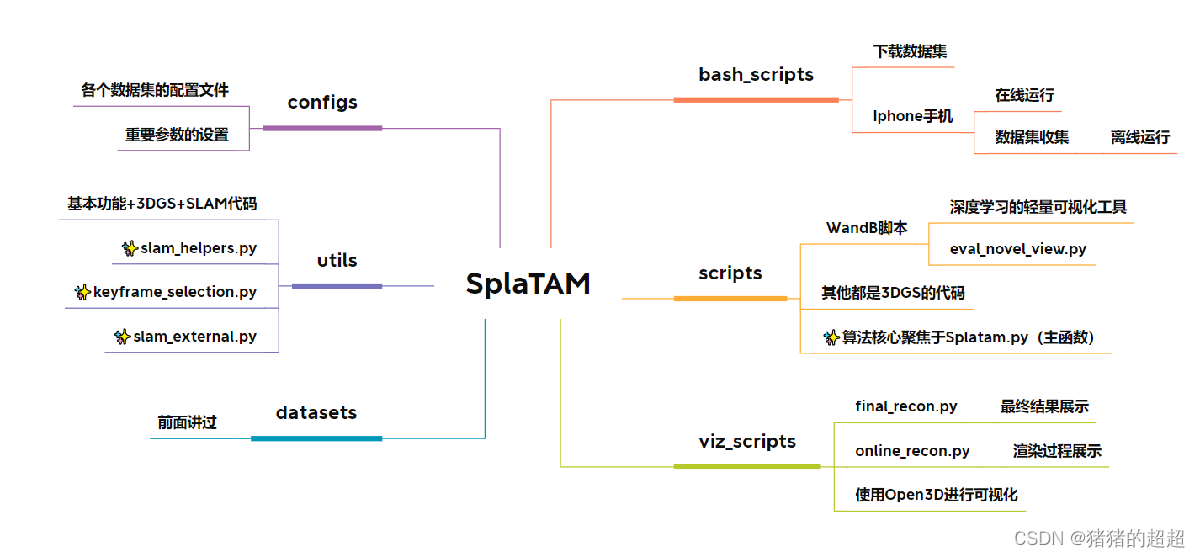
5.2 配置文件:configs/tum/splatam.py
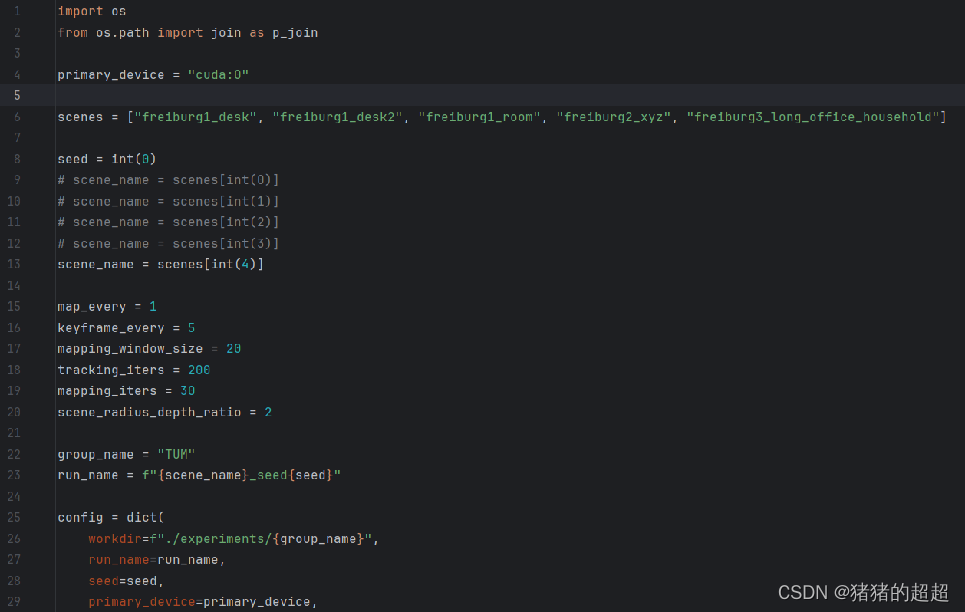
- 一、场景选择 (scene_name): 通过索引选择一个场景进行处理,共五个场景 map_every: 每多少帧进行一次映射(Map)操作。 keyframe_every: 每多少帧选择一个关键帧。 mapping_window_size: 映射窗口的大小。
- 二、跟踪迭代和映射迭代 (tracking_iters, mapping_iters): tracking_iters: 跟踪(Tracking)阶段每帧的迭代次数。 mapping_iters: 映射(Mapping)阶段的迭代次数。 scene_radius_depth_ratio :用于在剪枝(Pruning)和致密化(Densification)过程中设置深度和场景半径的比例。
- 三、跟踪配置 (tracking 字典): 包含了是否使用真实位姿(Ground Truth Poses)、是否前向传播姿态、是否使用轮廓(Silhouette)作为损失函数的一部分等设置。 映射配置 (mapping 字典):包含了映射迭代次数、是否添加新的高斯点、轮廓阈值、是否使用L1损失等。 prune_gaussians: 是否在映射过程中剪枝高斯点。 pruning_dict: 剪枝相关的参数,如开始剪枝的迭代后、移除大高斯点后的迭代数等。 use_gaussian_splatting_densification: 是否使用基于高斯溅射的致密化方法。 densify_dict: 致密化相关的参数,如开始致密化的迭代后、移除大高斯点后的迭代数等。
- 四、可视化配置 (viz 字典): 包含了渲染模式、是否显示轮廓、可视化相机和轨迹、可视化窗口大小、视野深度等。
5.3 核心算法文件:scripts/splatam.py
其中的rgbd_slam函数是核心算法的实现
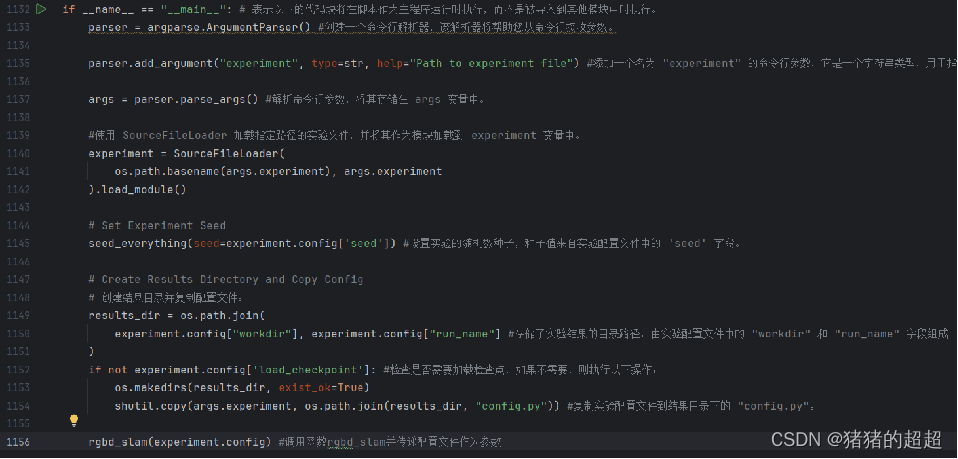
1、打印配置信息、创建输出目录、初始化WandB、加载设备和数据集等操作;
2、迭代处理RGB-D帧,进行跟踪(Tracking)和建图(Mapping)。
3、保存关键帧信息和参数。
4、最后,评估最终的SLAM参数。
其他的重要函数见本人所制作的PPT,如下所示:
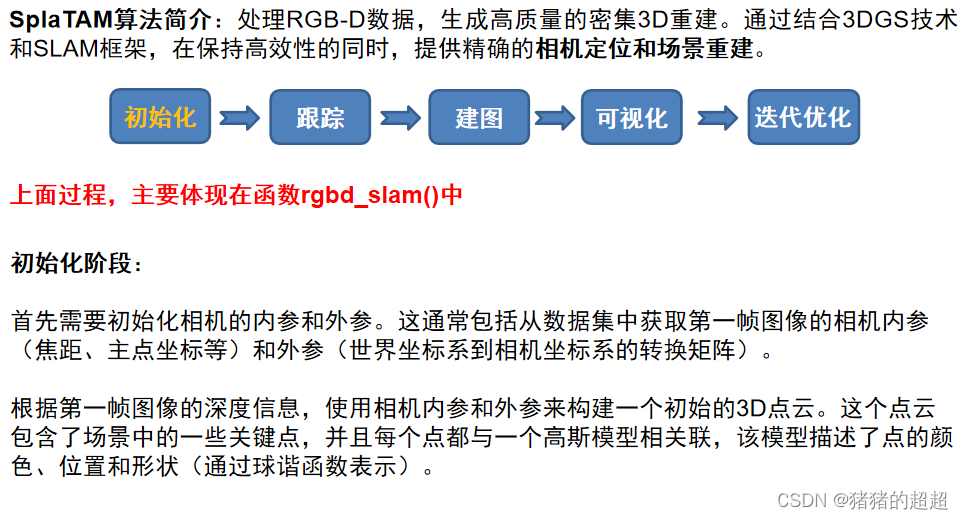
5.3.1 初始化阶段

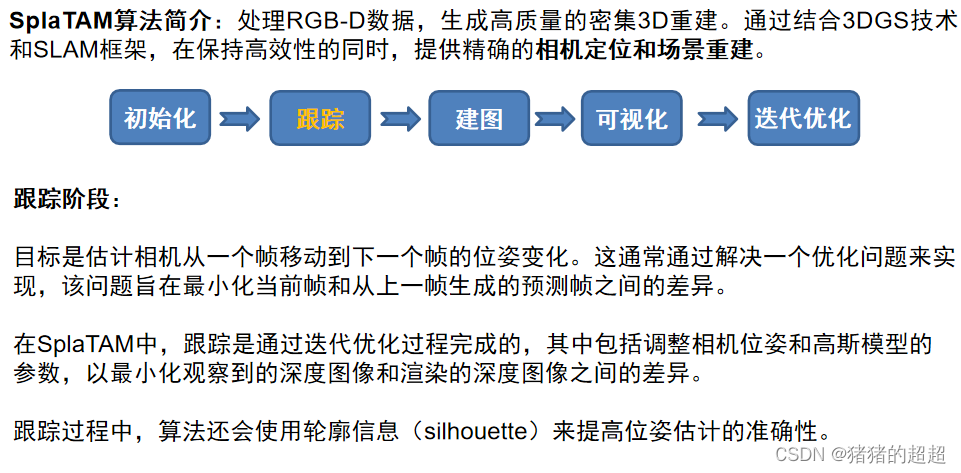
5.3.2 Tracking阶段

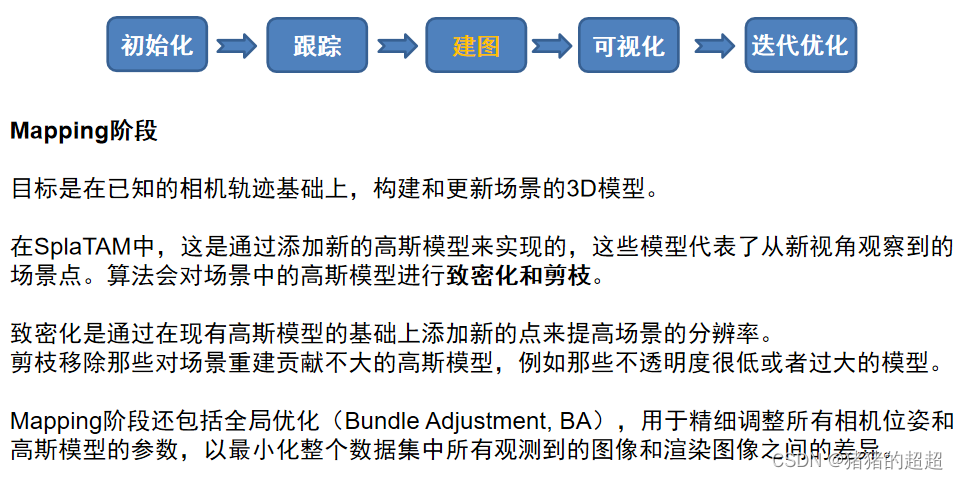
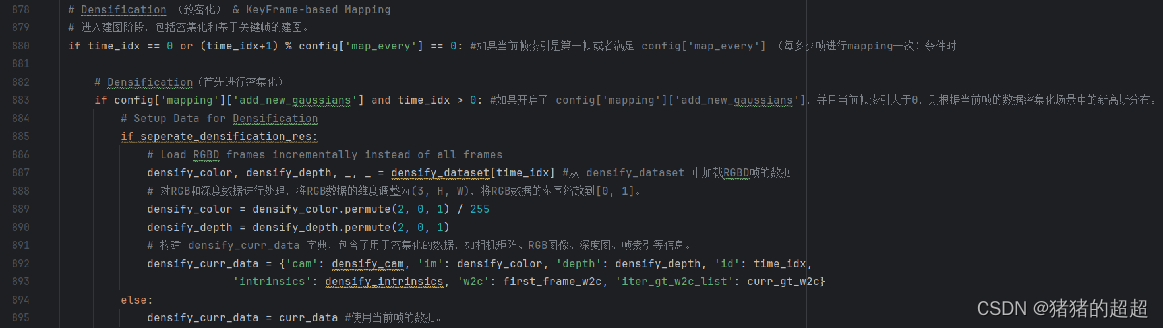
5.3.3 Mapping阶段

5.3.4 可视化阶段
可视化阶段: 可以使用生成的3D模型和相机轨迹来可视化场景。 将3D点云渲染成2D图像,并展示相机在场景中的运动轨迹。 可视化有助于理解算法的性能和重建的质量,还可以用于调试和优化算法参数。
5.3.5 迭代优化
在整个SplaTAM算法中,跟踪和建图阶段是交替进行的。 每次迭代都会根据新的观测数据更新相机轨迹和场景模型,直到满足停止条件,例如达到预设的迭代次数或者误差收敛到一个可接受的范围。
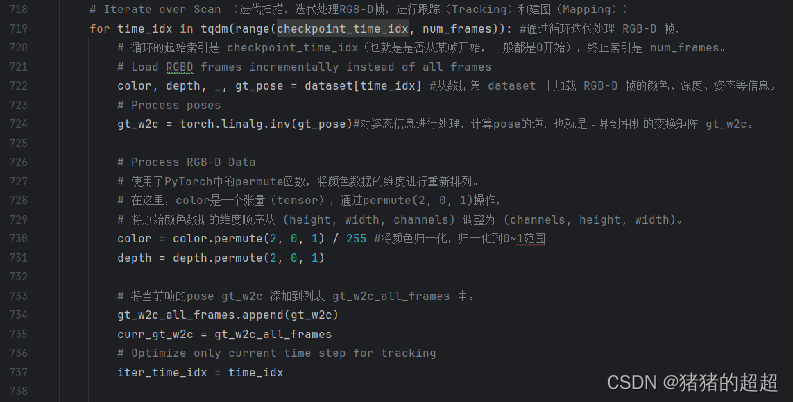
5.3.6 反向传播

5.4 其他算法文件
5.4.1utils/keyframe_selection.py
5.4.2utils/slam_external.py
5.4.3utils/slam_helper.py
这部分的内容,还请读者们自行阅读代码,代码量较少,阅读难度较低。
5.5 光栅化
3DGS的渲染过程是利用了光栅化(rasterization) 而光栅化的过程需要在GPU上运行。
from diff_gaussian_rasterization import GaussianRasterizationSettings GaussianRasterizer这部分的源码用cuda写的 GaussianRasterizationSettings与GaussianRasterizer对应的代码 在submodules/diff-gaussian-rasterization/diff_gaussian_rasterization/__init__.py 光栅化的源码主要的运行及计算的工程是forward(采用前向渲染)
该函数使用了CUDA并行计算,通过调用名为 preprocessCUDA 的 CUDA 核函数来执行高斯光栅化的前处理。CUDA 核函数的执行由函数参数确定。在 CUDA 核函数中,每个线程块由多个线程组成,负责处理其中的一部分数据,从而加速高斯光栅化的计算。
参考链接如下:https://github.com/JonathonLuiten/diff-gaussian-rasterization-w-depth
总结
本人从配置运行SplaTAM,到进行算法解读和代码讲解,细致入微地对基于3D-GS的SLAM算法经典之作,进行了一个总结回顾。
这篇关于论文复现《SplaTAM: Splat, Track Map 3D Gaussians for Dense RGB-D SLAM》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




