本文主要是介绍Dense Distinct Query for End-to-End Object Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
对象检测中的一对一标签分配成功地消除了作为后处理的非极大值抑制( NMS )的需要,并使流水线端到端。然而,这引发了一个新的困境,因为广泛使用的稀疏查询无法保证高召回率,而密集查询不可避免地带来更多类似的查询并遇到优化困难。由于稀疏查询和密集查询都有问题,那么端到端对象检测中预期的查询是什么?本文证明了该解决方案应该是密集的区别查询( DDQ ) 。具体来说,我们首先像传统的检测器一样设置密集的查询,然后选择不同的查询进行一对一分配。DDQ 融合了传统和最近端到端检测器的优点,显著提高了包括FCN 、 R-CNN 、和 DETR 在内的各种检测器的性能。最令人印象深刻的是,DDQ-DETR 使用 ResNet-50 主干在 12 个 epoch 内在 MSCOCO 数据集上实现了 52.1 个 AP 。
总结
一对一标签分配消除了 NMS 的需要,但是带来了另一问题,即广泛使用的稀疏查询无法保证高召回率,而密集查询不可避免地带来更多类似的查询并遇到优化困难。因此,本文提出了密集的区别查询(DDQ )。具体,我们首先像传统的检测器一样设置密集的查询,然后选择不同的查询进行一对一分配。
1、介绍
传统的检测器 首先放置预定义的密集网格查询,以实现高召回率。然后应用具有共享权重的卷积以滑动窗口的方式快速处理密集查询。最后,将一个基于事实边界框分配给多个相似的候选查询进行优化。然而,一对多分配 会导致冗余预测,因此在推理过程中 需要额外的重复去除操作 (例如,非极大值抑制),这会导致与训练的推理不一致,并阻碍管道端到端。
DETR 打破了这一范式,它只为每个基本事实边界框分配一个肯定查询(一对一分配)以实现端到端。该方案需要大量计算来细化查询,并采用自关注来建模查询之间的交互,有利于一对一分配的优化。不幸的是,这限制了查询的数量。例如,DETR 仅初始化数百个可学习对象查询。因此,与传统检测器中的密集分布查询相比,稀疏查询的召回率不足。
最近的一些工作也试图将密集查询集成到一对一分配中。然而,端到端检测器中的密集查询面临着独特的挑战。例如,我们的分析表明,这种范式将不可避免地引入许多类似的查询(可能代表相同的实例),并且由于类似的查询在一对一分配下要被分配相反的标签。因此它受到了困难和低效的优化。既然一对一分配下的稀疏查询(低召回率)和密集查询(优化难度)都是次优的,那么端到端对象检测中的预期查询是什么?
在这项研究中,我们证明了解决方案应该是密集的不同查询( DDQ ),这意味着 用于对象检测的查询应 该是密集分布的以检测所有对象,也应该是彼此不同的以促进一对一标签分配的优化 。在这一原则的指导下,我们不断提高各种检测器架构的性能,包括FCN 、 R-CNN 和 DETR 。对于 由全卷积网络( FCN )组 成的一级检测器 ,我们首先 提出了一种金字塔混洗操作来代替繁重的自注意, 以对密集查询之间的交互进行建模。然后,不同查询选择方案确保只对所选的不同查询进行一对一分配 ,防止将矛盾的标签分配给类似的查询。这种端到端的一级探测器被命名为DDQ-FCN ,并在一级探测器中实现了最先进的性能。DDQ还自然地扩展到 DETR 和 R-CNN 结构, 方法是首先如 [38] 中那样设置密集查询,然后选择不同的查询 用于随后的细化阶段 ,分别称为 DDQ-R-CNN 和 DDQ-DETR 。
总结
既然有密集查询和一对一查询,那么为了平衡二者之间的缺点,可以使用密集的不同查询( DDQ )。
2 、相关工作
一对多任务的密集查询 。一级检测器,如 RetinaNet 和 FCOS ,使用密集分布的查询进行回归和分类。同样的方式也适用于多阶段模型的区域建议网络。对于这种传统的探测器来说,一对多任务是一种常见的做法。尽管从静态标签分配(如基于IOU 的和基于中心的)到预测感知的动态标签分配,一对多分配的发展很快。这种策略也长期受到批评,因为它们将每个基本事实与多个查询配对,因此需要额外的后处理来消除推理时的重复预测,从而防止了管道的端到端。
具有一对一分配的稀疏查询 。 DETR 设计了一小组学习的位置嵌入,这些嵌入表示图像中要关注的位置。然后,这些查询通过一对一的分配进行优化,形成一个端到端的管道。稀疏R-CNN 将传统 R-CNN 框架中的查询重新表述为边界框及其相应的嵌入。锚点DETR 提供锚点和查询位置之间的对应关系。 DAB-DETR显示学习一组4-D 锚框作为查询。尽管查询的形式各不相同,但它们共享稀疏查询和一对一分配的相同核心思想。因此,低召回率是这些检测器的预期问题。
具有一对一分配的密集查询 。
DeFCN 和 OneNet 都试图将一对一分配与密集查询相集成。尽管与 FCOS 相比,它们的性能具有竞争力,但与最近采用动态一对多分配策略的检测器仍然存在明显的性能差距。正是在一对一分配下类似查询的优化难度造成了性能差距。高效DETR 和两阶段可变形 DETR 也可以被视为该范式的多阶段版本。尽管DINO、 Group DETR 和 HDeformableDETR 引入了更多的正样本来加快收敛,但类似查询和一对一分配之间的阻碍效应仍然没有消除。
2、稀疏和密集查询分析
当前的端到端检测器使用密集或稀疏查询,但这两种查询在训练过程中都存在问题。特别地,稀疏查询的调用率较低,而密集查询在优化方面存在问题。为了说明这一点,我们在Spare R-CNN 中将查询数量从10 个增加到 7000 个,性能如图 2 黑线所示。
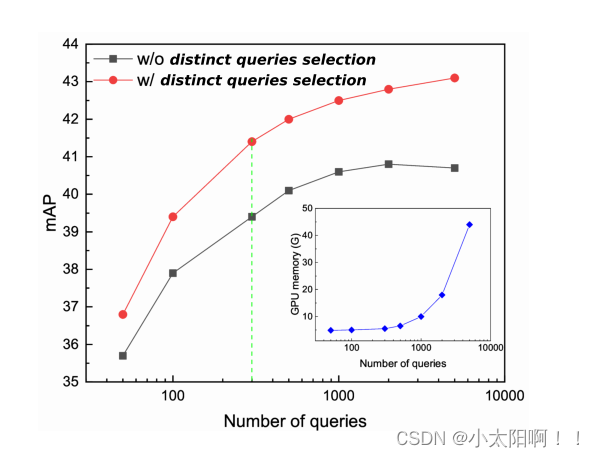
性能首先随着查询数量增加到 2000 左右而不断上升,这意味着 spare R-CNN 中的稀疏查询由于召回率低而远远不够。另一方面,随着查询数量的进一步增加,性能最终趋于平稳,甚至下降。这种现象可以用一对一分配的端到端检测器中难以区分类似查询来解释,尤其是当查询变得密集时。
为了理解相似的查询如何阻碍优化,我们提供了一个简化的示例,其中我们假设存在两个相同的查询。 在这种情况下,一对一分配为其中一个分配前景标签,但为另一个分配背景标签。在不失一般性的情况下,我们采用二进制交叉熵损失进行分类。因此,这两个查询的损失变成
查询存在时,损失值为: 。重复查询和非重复查询之间的梯度的比率
。重复查询和非重复查询之间的梯度的比率 为:
为:
如 toy 示例,重复查询会降低梯度,甚至导致负训练,这会显著抑制收敛。为了避免这个问题,我们 在一 对一分配过程之前增加了一个不同的查询选择操作 。 不同查询选择策略是通过一个简单的类无 NMS 实现 的 。 因此,过滤后的不同查询更容易优化,这样的操作可以明显提高性能 ,如图 2 的红色曲线所示。更令人惊讶的是,随着查询数量的增加,性能余量不断增加。对于可变形DETR 也观察到类似的趋势。换句话说,一旦我们确保所选查询是不同的,Spare R-CNN 的性能就可以随着不同查询数量的增加而不断提高。
3、方法
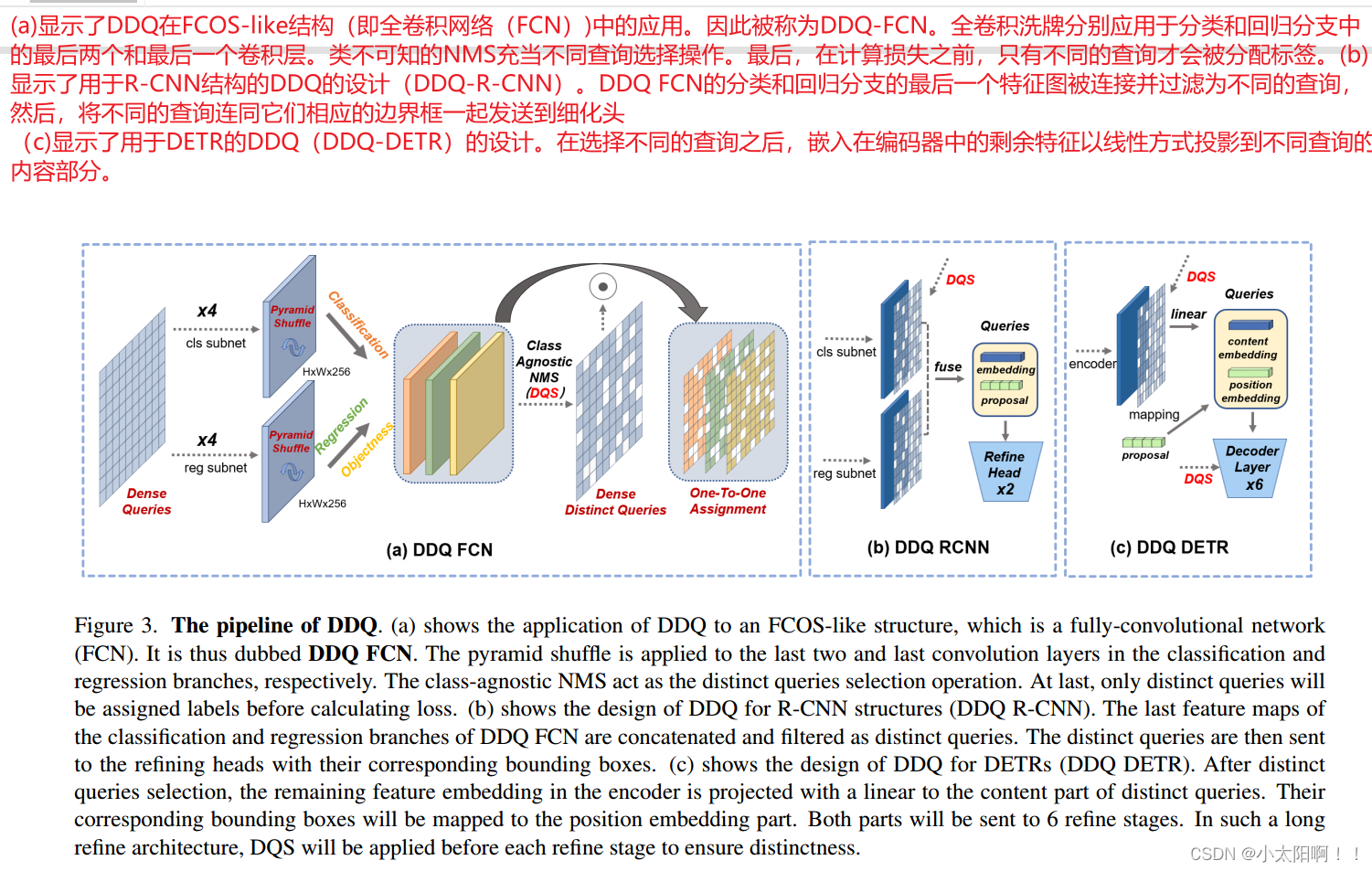
密集不同查询( DDQ )是我们设计对象检测器的原则 , 可以集成到不同的体系结构中 。我们首先简要描述了DDQ 的设计,然后详细描述了三种架构: FCN 、 R-CNN 和 DETR 。整个管道如图 3 所示。
3.1 DDQ范式
密集查询 。如图 2 所示,密集查询的内存成本飙升。造成这种情况的主要原因是每个查询的计算量很大,DDQ 没有在 DETR 中采用可学习 的位置嵌入,而是直接将每个特征图上的特征点作为密集分布的初始查询。如果输入分辨率为800x800,则特征金字塔中的查询数量可以轻松超过 10000 ,为了以合理的计算成本区分密集查询,轻量级卷积和线性网络作为第一阶段,以滑动窗口的方式处理所有查询。 不同查询 。为什么可以使用 类不可知的非最大值抑制( NMS )来选择不同的查询 ,以及它与传统 NMS 在传统检测器中的后处理有何不同。由于每个查询表示图像中的潜在实例 ,并且 一个实例可以通过其在图 像中的位置来唯一地表示 , 使用查询预测的边界框之间的类不可知重叠率来检测类似查询 是很自然的。更具体地说,我们应用类不可知的 NMS 来为以下一对一分配选择不同的查询 。因此,损失仅根据所选的不同查询进行计算。应该注意的是,这种操作在训练和推理中都被采用,而不是仅在推理中作为传统检测器的额外后处理。因此,这样的管道仍然遵循端到端检测器的定义。与传统检测器中的未经训练的NMS相比,它旨在减轻训练过程中一对一分配的负担,因此可以设置一个积极的 IoU 阈值( DDQ FCN 和DDQ R-CNN中为 0.7 , DDQ DETR 中为 0.8 )。
损失组成部分
密集查询不同的主要损失 。我们简单地应用 DETR 中的二分匹配算法,在一对一分配中具有相同的成本权重。没有采用额外的先验来与DETR 进行公平比较。 在区分阳性和阴性样本后, DDQ FCN 采用 GIoU 损失 和 Q 局部损失,权重分别为 2 和 1 。对于 DDQ-RCNN 和 DDQ-DETR ,我们只遵循 Spare R-CNN 和 DINO 的实现。
( 2 ) 密集查询的辅助损失 。尽管由于删除了类似的查询,更多有效优化在 DDQ 中,它还导致了许多“leaf”查询,通过这些查询不会反向传播梯度。因此,我们根据 DeFCN 中的设计, 设计了一个辅助头和一 个辅助损失,以进一步利用过滤查询的潜力 。辅助头和主头基本相同,只是它对密集查询采用了 soft 的一对多分配,以允许密集的梯度和更多的正样本加快训练。
3.2DDQ FCN
如图 3(a) 所示
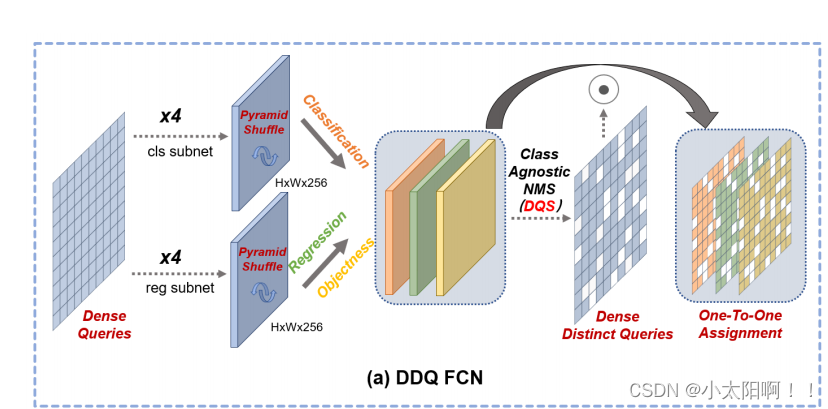
DDQ 原理首先应用于 FCOS ,作为用于对象检测的 FCN 结构的示例。研究发现,在密集特征金字塔上已经可以使用密集查询。然而,由于密集查询是用卷积层逐层处理的。不同级别之间缺失的交互对一对一分配的优化提出了挑战。受shuffleNet 中通道混洗操作的启发,我们 提出了一种金字塔混洗来补偿不同级 别的查询之间的交互 , 其中跨相邻级别的 S 个通道被混洗以形成新的特征金字塔 。 具体而言 , i 级功能部件同时与i-1 级和 i+1 级功能部件交换 S 通道。为了考虑特征金字塔上不同的空间维度, 在交换特征时采用 双线性插值 。我们 分别在分类和回归分支的最后两个和一个卷积层上应用金字塔洗牌操作 。这种方法稳定了训练并提高性能,而额外的计算成本可以忽略不计。在这个工作中,我们把S 设置为 64 ,这意味着每个特征级别与其他级别交换来自128 个通道的信息。(与其他方法的比较,可以在我们的补充材料中找到密集查询、消融和金字塔洗牌分析之间的交互建模)
对于 DDQ FCN 中的不同查询选择模块,我们首先根据每个特征级别的分类得分选择前 1000 个预测,然 后应用阈值为 0.7 的类不可知非最大值抑制,以确保不同数据集的区分性和通用性。
3.3 DDQ R-CNN
我们将 DDQ-FCN 与稀疏 R-CNN 中的两个细化阶段相结合,构建了 DDQ-R-CNN 。如图 3 所示,
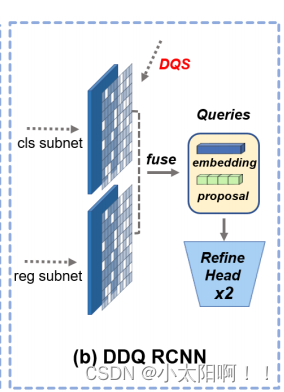
由于 DDQ FCN 中对密集不同查询的快速处理,我们根据剩余不同查询的分类得分选择了 300 个最具代表性的查询。然后,我们将分类分支和回归分支的最后一个特征图的不同位置的特征连接起来,以构建查询嵌入。查询嵌入和相应的边界框预测被传递给Spare R--CNN 的细化负责人。与 Spare R-CNN 需要 6 个阶段的迭代查询细化不同,DDQ R-CNN 只需要 2 个细化阶段。事实上,稀疏 R-CNN 中的长迭代阶段主要弥补了稀疏和有时相似的输入查询所造成的缺陷。首先,稀疏查询不能覆盖初始化时的所有实例,因此需要很长的级联阶段来细化。另一方面,类似的查询也需要长时间细化才能相互去区分,从而为每个实例输出一个热点预测。相反,来自DDQ R-CNN 的密集的不同查询解决了上述问题,因此可以显著减少迭代细化的数量。
3.4 DDQ DETR
我们构建了基于可变形 DETR 的 DDQ DETR 。如图 3 ( c) 所示,我们遵循两阶段可变形 DETR 来处理密集查询。我们没有用转换后的坐标初始化内容部分,而是将不同位置的特征图嵌入融合为内容部分,这使得初始查询更加不同。阈值为0.8 的类不可知 NMS 被设置为每个细化阶段之前选择不同的查询。为了与最近的DETR 进行比较,我们保留了最初的 6 个精炼阶段,并为精炼阶段选择了 K 个不同的查询。我们还根据分类得分直接选择前1.5k 个查询作为解码器中辅助头部的密集查询。密集查询和不同查询的并行转发遵循H-DeformableDETR 和 Group。
这篇关于Dense Distinct Query for End-to-End Object Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




