distinct专题

Java Stream的distinct去重原理分析
《JavaStream的distinct去重原理分析》Javastream中的distinct方法用于去除流中的重复元素,它返回一个包含过滤后唯一元素的新流,该方法会根据元素的hashcode和eq... 目录一、distinct 的基础用法与核心特性二、distinct 的底层实现原理1. 顺序流中的去重

详解MySQL中DISTINCT去重的核心注意事项
《详解MySQL中DISTINCT去重的核心注意事项》为了实现查询不重复的数据,MySQL提供了DISTINCT关键字,它的主要作用就是对数据表中一个或多个字段重复的数据进行过滤,只返回其中的一条数据... 目录DISTINCT 六大注意事项1. 作用范围:所有 SELECT 字段2. NULL 值的特殊处
Longest Substring with At Most K Distinct Characters
Given a string, find the length of the longest substring T that contains at mostk distinct characters. For example,Given s = “eceba” and k = 2, T is "ece" which its length is 3. 思路:跟 Longest Sub

Longest Substring with At Most Two Distinct Characters
Given a string, find the length of the longest substring T that contains at most 2 distinct characters. For example,Given s = “eceba”, T is "ece" which its length is 3. 思路:同向双指针,跟Longest Substrin
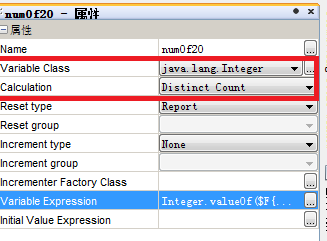
iReport利用Print Repeated Values做分组报表以及对重复值做distinct运算
iReport自带的分组功能有可能是比较符合西方的分组标准,对于中国人来说希望显示方便、节省纸张,对于iReport实现起来就稍微复杂一点了。 本文所用demo地址:http://download.csdn.net/detail/u013284604/6812623 iReport版本 5.1.0,demo所用数据源:json数据源 一、iReport利用Print Repeated Val
SparkRDD之distinct和first
distinct:对RDD中的元素进行去重。 first:返回RDD中第一个元素。 package com.cb.spark.sparkrdd;import java.util.Arrays;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.a

SQL中distinct 和 row_number() over() 的区别及用法
1 前言 在咱们编写 SQL 语句操作数据库中的数据的时候,有可能会遇到一些不太爽的问题,例如对于同一字段拥有相同名称的记录,我们只需要显示一条,但实际上数据库中可能含有多条拥有相同名称的记录,从而在检索的时候,显示多条记录,这就有违咱们的初衷啦!因此,为了避免这种情况的发生,咱们就需要进行“去重”处理啦,那么何为“去重”呢?说白了,就是对同一字段让拥有相同内容的记录只显示一条记录。 那么,如
Select Distinct
请问sql语句“Select Distinct”是什么意思?可不可以讲一下它的用法 举报| 分享| 2010-11-19 21:38 qq417617128 | 浏览 11249 次 1.Select Distinct 货品编码,数量 From 订单信息2.Select Distinct 货品编码 From 订单信息第一句和第二句有什么分别,请高手说说Distinct用法 我
SQL中的DISTINCT和GROUP BY异同
在SQL中,DISTINCT和GROUP BY都是非常重要的关键字,它们各自有着独特的用途和应用场景。尽管两者在一定程度上都可以帮助我们处理重复的数据,但它们的目的、用法以及适用场景都有所不同。下面我们将深入探讨这两个关键字的异同点。 1. 概念理解 1.1 DISTINCT DISTINCT关键字用于从查询结果中去除重复的行,只保留唯一的记录。它通常用于SELECT语句中,紧接在SELEC
count(distinct ...) over (partition by...) 替换成mysql
你这个是用了 Oracle 的分析函数。 SQL Server 是不支持的。如果语句比较简单的。例如SELECT COUNT( distinct A) OVER ( partition by B) FROM C可以修改为:SELECT COUNT( distinct A) FROM CGROUP BY B但是如果你的逻辑很复杂的话,那就麻烦了。
sql count()加distinct和条件去重统计
表数据: userid userType------------------------------------------A 1B 1B 1C 2 需求:查出userType=1和userType=2的用户数,并且直接用字段展示出来,可能还有很多其他类型,也
count,distinct和group by对null值的操作
distinct 会将所有null视为一项 group by 将所有null值视为一项 count 不会计算null值项,count(null)=0 select count() from (select count() as num from library_books group by stayLibraryHallCode) temp; 输出结果是3229 select COUNT
distinct去掉mysql中重复字段值
http://xiaozhuge0825.blog.163.com/blog/static/5760606820113135125148/ distinct去掉mysql中重复字段值 2011-04-13 17:01:25| 分类:mysql | 标签:mysql distinct 不重复字段值 |字号 订阅 在使用mysql时,有时需要查询出某个字段不重复的记录
聊聊flink Table的Distinct Aggregation
序 本文主要研究一下flink Table的Distinct Aggregation 实例 //Distinct can be applied to GroupBy Aggregation, GroupBy Window Aggregation and Over Window Aggregation. Table orders = tableEnv.scan("Orders"
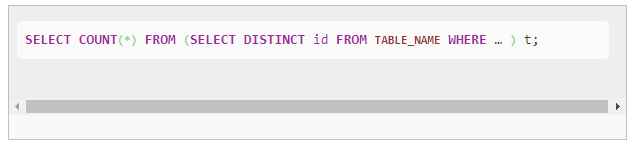
hive中count(distinct) 的原理
目录 count(distinct id)的原理count(distinct id)的解决方案 参考博客: https://blog.csdn.net/oracle8090/article/details/80760233 回到顶部 count(distinct id)的原理 count(distinct id)从执行计划上面来看:只有一个reducer任务(即使你
UVA 10069 Distinct Subsequences(dp + 高精度)
Problem E Distinct Subsequences Input: standard input Output: standard output A subsequence of a given sequence is just the given sequence with some elements (possibly none) left out. Formall
Mysql基础教程(11):DISTINCT
MySQL DISTINCT 用法和实例 当使用 SELECT 查询数据时,我们可能会得到一些重复的行。比如学生表中有很多重复的年龄。如果想得到一个唯一的、没有重复记录的结果集,就需要用到 DISTINCT 关键字。 MySQL DISTINCT用法 在 SELECT 语句中使用 DISTINCT 关键字会返回一个没有重复记录行的结果集。 DISTINCT 的用法如下: SELECT DI
oracle去重查询/删除,distinct多列问题解决方案!
关于Oracle开发必备的基础操作 作者:孙夕恩 --去重查询方法一:根据id select * from sxe where id in(select min(id) from sxe group by username) order by id asc; --去重查询方法二:根据rownum select * from (select s.*,row
MySQL中distinct和group by性能比较[转]
http://www.cnblogs.com/zox2011/archive/2012/09/12/2681797.html
【SAP HANA 31】HANA中distinct和having去重比较
目录 1、DISTINCT 2、HAVING 3、性能对比 3.1、查询复杂度 3.2、查询优化 3.3、内存使用</
mysql 的DISTINCT、EXISTS、IN、GROUP BY..HAVING 用法记录
mysql 的DISTINCT (去掉重复) mysql 的EXISTS (存在于、 条件的字段,值均在括号中) mysql 的IN (在、 条件字段的在括号前,条件值在括号中) mysql 的GROUP BY..HAVING(分组,把字段值相同的统计出来,having 统计个数限制条件)GROUP BY..HAVING结合使用 SELECT * from class;SELECT *
spoj694/705 Distinct Substrings - 后缀数组
题目链接:http://acm.hust.edu.cn/vjudge/problem/19282 题目大意:求不同子串的个数 解题思路:后缀数组.. suffix(i)对子串个数所做的贡献为len-sa[i]+1,因为要求要不同的,所以减去与它串重复的子串个数h[i]。即每个后缀对答案的贡献为len-sa[i]+1-h[i];(***) #include<cstdio>#incl
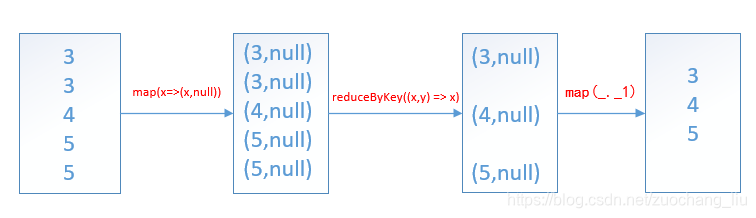
Spark distinct去重原理 (distinct会导致shuffle)
distinct算子原理: 含有reduceByKey则会有shuffle 贴上spark源码: /*** Return a new RDD containing the distinct elements in this RDD.*/def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] =
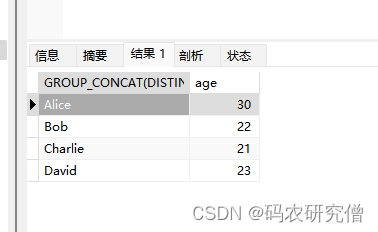
详细分析MySQL中的distinct函数(附Demo)
目录 前言1. 基本知识2. 基础Demo3. 进阶Demo 前言 该函数主要用于去重,对于细节知识,此文详细补充说明 1. 基本知识 DISTINCT 是一种用于查询结果中去除重复行的关键字 在查询数据库时,可能会得到重复的结果行,但有时只需要这些结果的唯一副本,这时就可以使用 DISTINCT 来过滤结果,确保每行只出现一次 类似如下: SELECT DISTINC
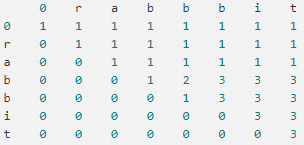
LeetCode - distinct-subsequences
题目: Given a string S and a string T, count the number of distinct subsequences of T in S. A subsequence of a string is a new string which is formed from the original string by deleting some (can be
8、InfluxDB常用函数(一)聚合函数,count()函数,DISTINCT()函数,MEAN()函数,MEDIAN()函数,SPREAD()函数,SUM()函数
8.InfluxDB学习之InfluxDB常用函数(一)聚合函数 8.1.count()函数 8.2.DISTINCT()函数 8.3.MEAN()函数 8.4.MEDIAN()函数 8.5.SPREAD()函数 8.6.SUM()函数 8.InfluxDB学习之InfluxDB常用函数(一)聚合函数 8.1.count()函数 返回一个(field)字段中的非空值的数量。 语法: SEL